✂️ 应用目标拆解:
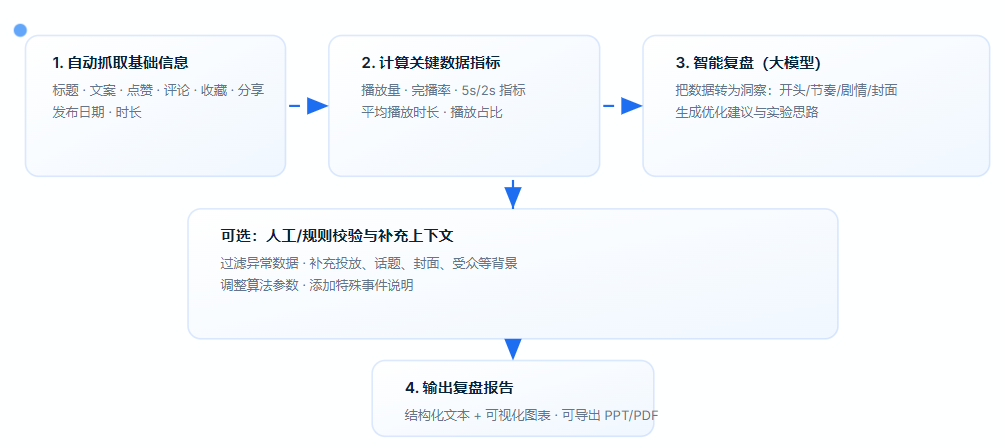
在短视频运营中,想要复盘一条视频的表现,往往需要在后台一项一项去查数据,再手动整理、分析,既耗时又容易遗漏。通过 Coze工作流,我们可以打造一个「视频数据复盘助手」:
-
自动抓取基础信息:如标题、文案、点赞数、评论数、收藏数、分享数、发布日期、时长等,免去人工逐条记录的麻烦
-
获取关键数据指标:包括播放量、完播率、5s 完播率、2s 跳出率、平均播放时长、平均播放占比,帮助快速定位视频真实表现
-
调用大模型复盘分析:将冷冰冰的数字转化为有逻辑的洞察,例如“开头吸引力不足导致 2s 跳出率偏高”、“中段剧情反转有效提升了平均播放时长”
-
输出复盘报告:生成一份条理清晰的报告,既能做内部复盘,也能直接用于团队复盘会的分享
因此,我们需要完成的任务如下:
⚙️ 创建详解
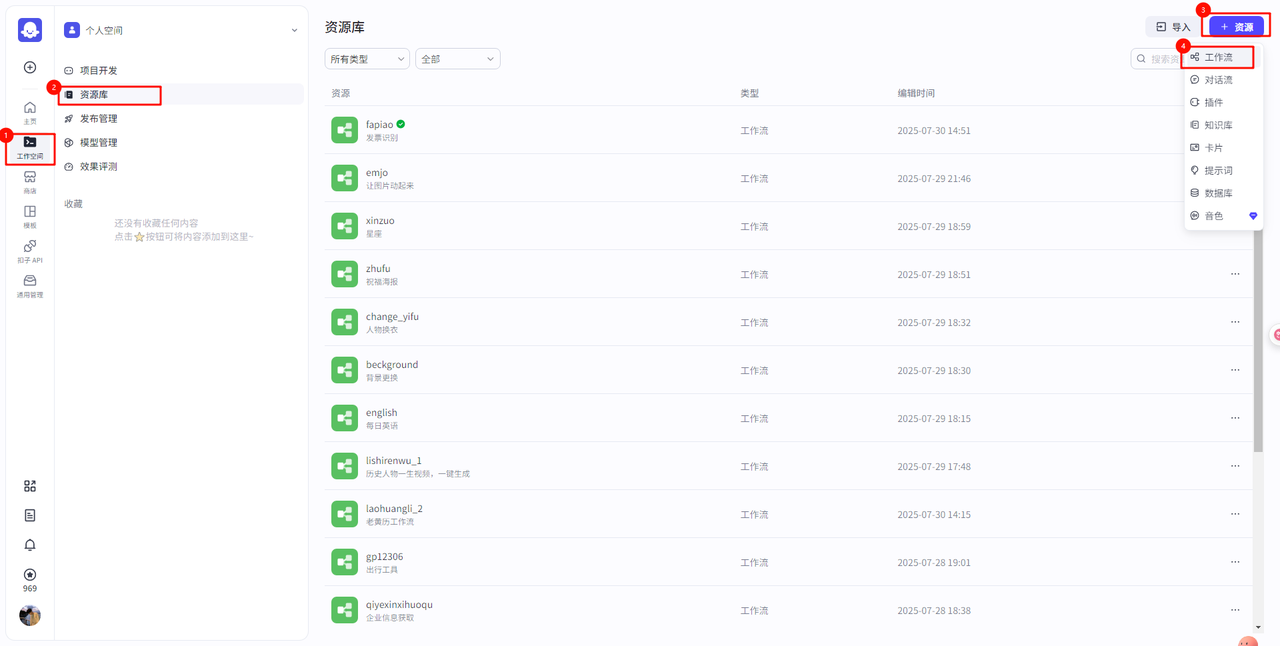
首先创建工作流,点击工作空间->资源库->资源->工作流
输入工作流名称和简单的工作流描述,点击确认
这个完整的工作流是这样的:开始节点之后,两条线并行,分别处理用户上传的抖音链接和数据截图,然后大模型再处理生成可视化报告,再通过插件处理为html和图片转出

1:开始节点
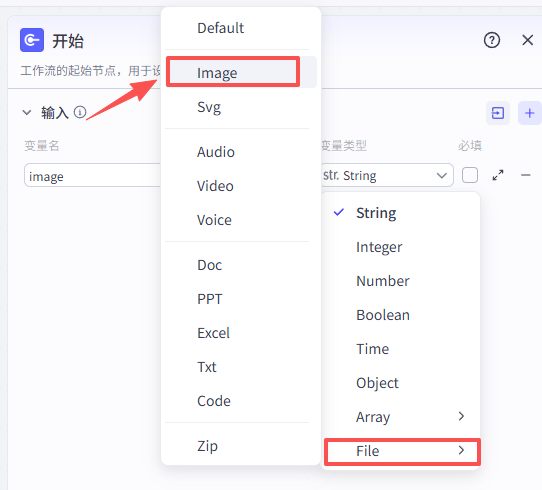
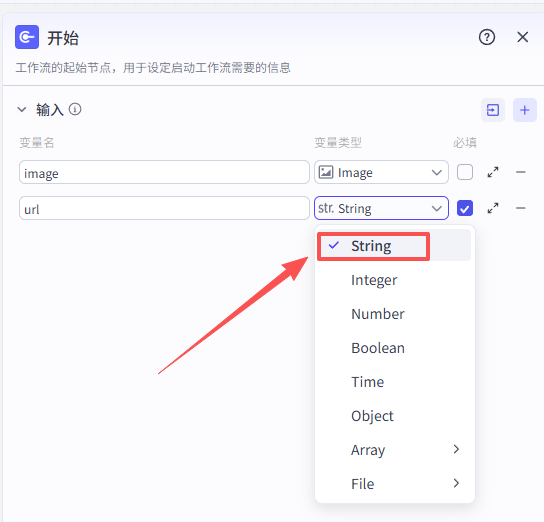
开始节点需要接收两个输入,一个是视频数据的截图,一个是抖音视频分享链接
-
image:Image-视频数据的截图
-
url:抖音视频分享链接
详细配置如下图
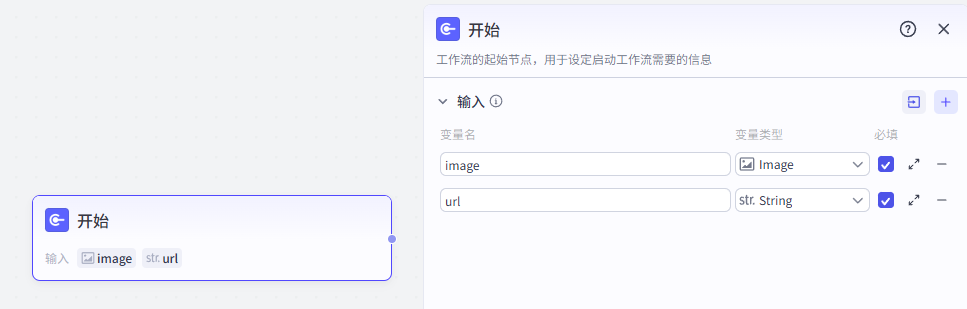
配置好之后就是这样,两个都是必填项
2:处理抖音链接
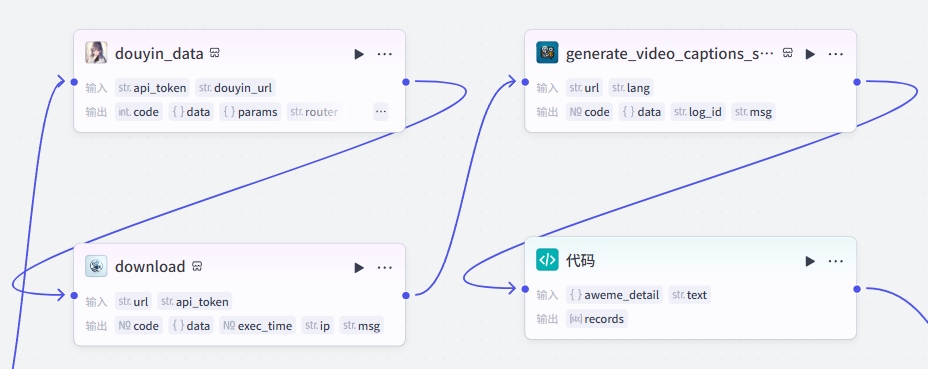
该部分共有四个节点,用于处理开始节点上传的抖音链接,提取主要文案并处理视频数据
视频搜索插件
接下来需要分析开始节点输入的url,所以添加一个【视频搜索插件】
点击添加节点,选择插件
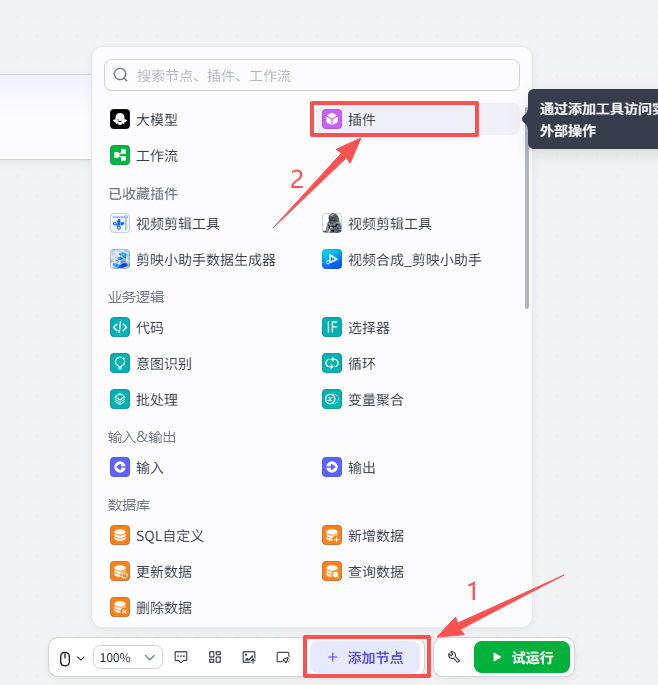
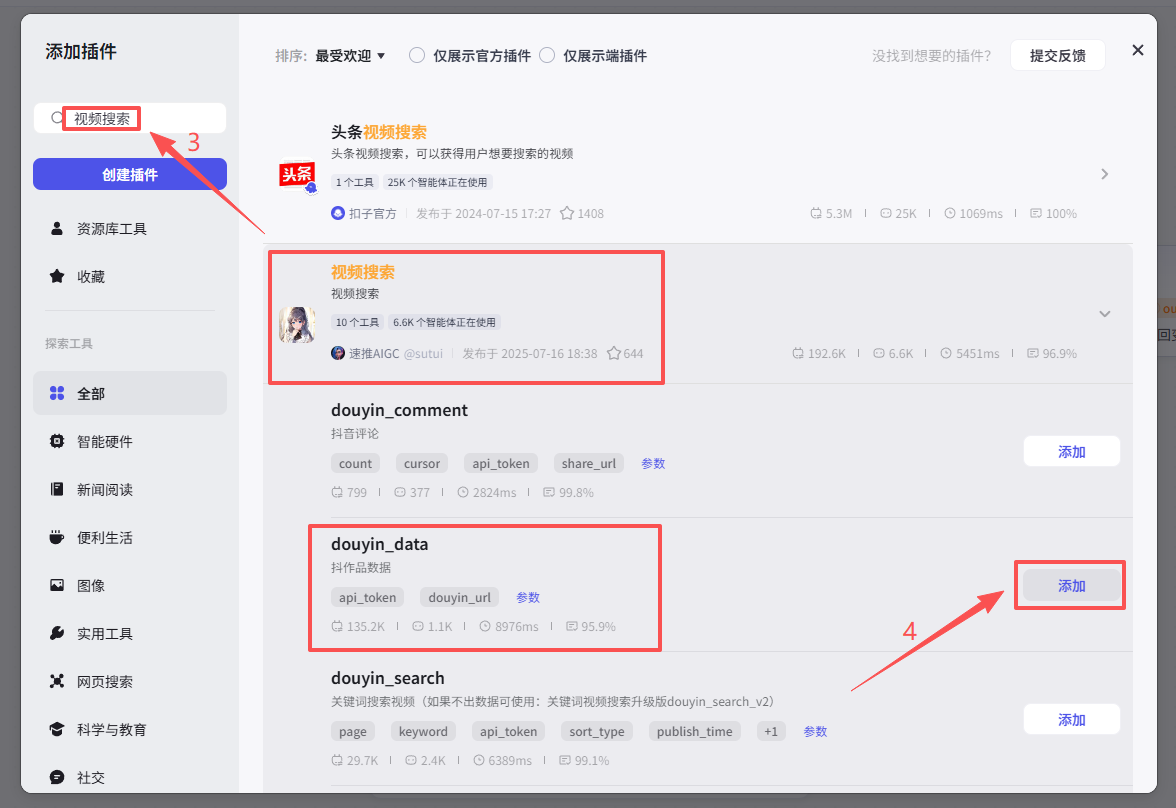
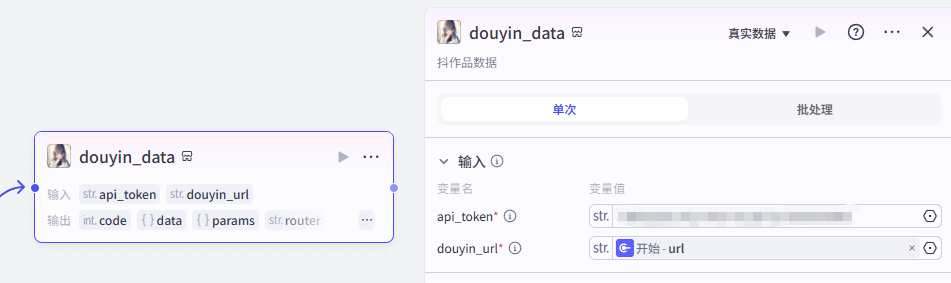
在输入框中输入视频搜索,看到我们框选出来的这个插件,选择添加他的douyin_data接口
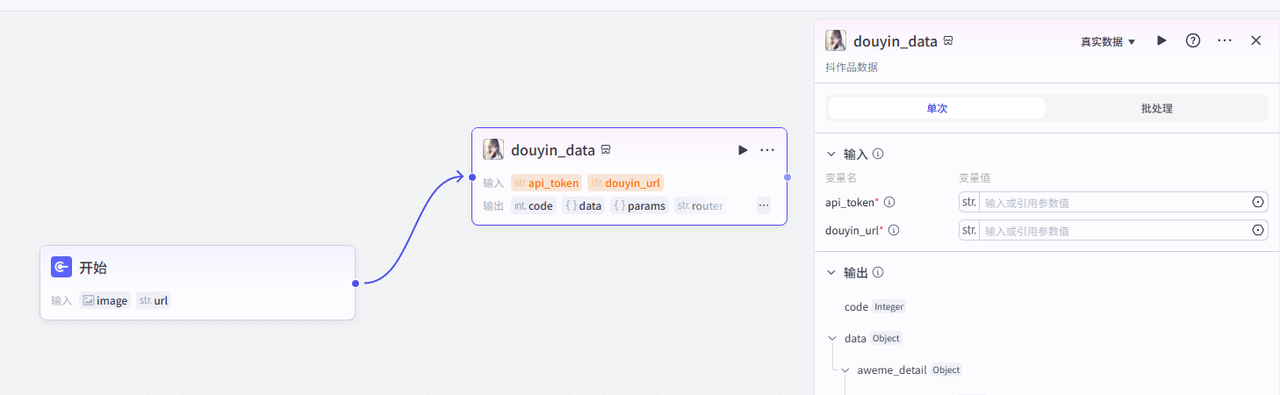
添加之后就是这样,把它和开始节点链接起来,这里需要配置两个参数
-
api_token:获取方式参考该文档点击前往
-
douyin_url:选择开始节点的url
配置好之后就是这样
视频全平台下载
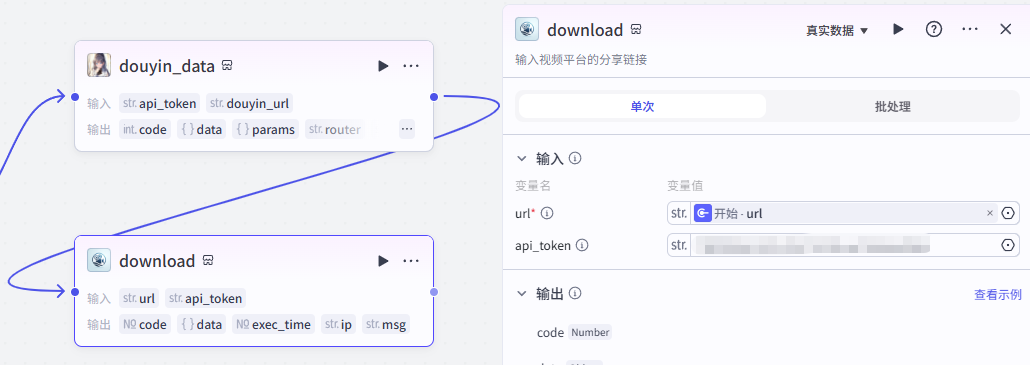
接下来添加【视频全平台下载】插件,通过它的download功能,我们可以下载短视频
点击添加节点,选择插件
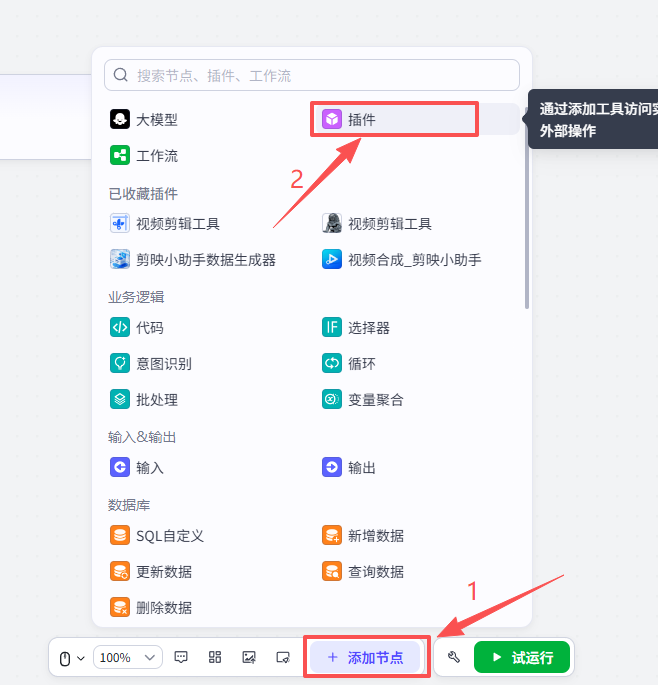
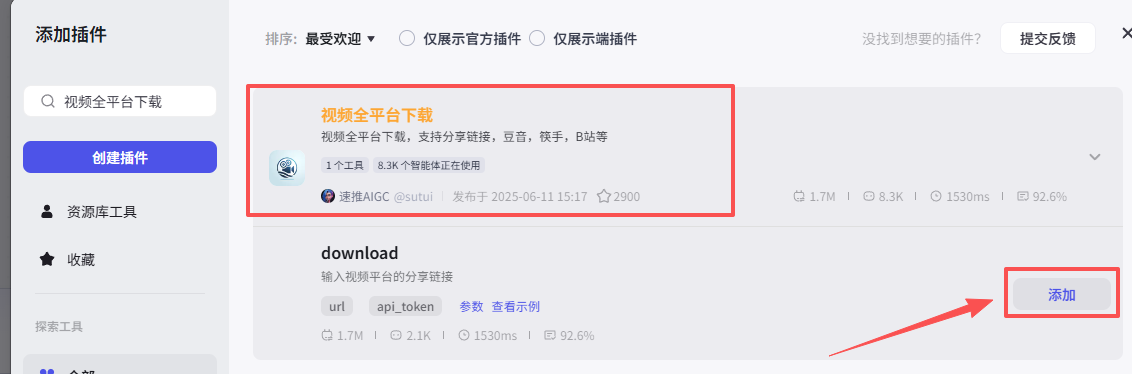
在输入框中输入视频全平台下载,看到我们框选出来的这个插件,选择添加他的download接口
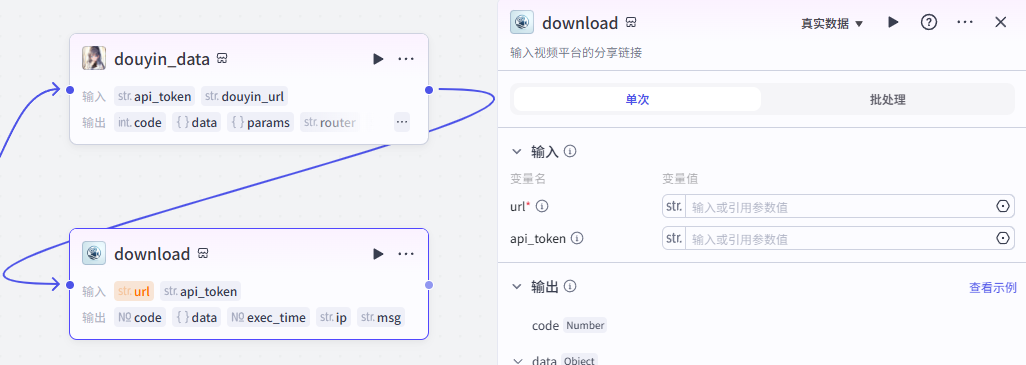
添加之后就是这样,把它和上一个节点链接起来,这里需要配置两个参数
-
url:选择开始节点的url
-
api_token:获取方式参考该文档点击前往
配置好之后就是这样
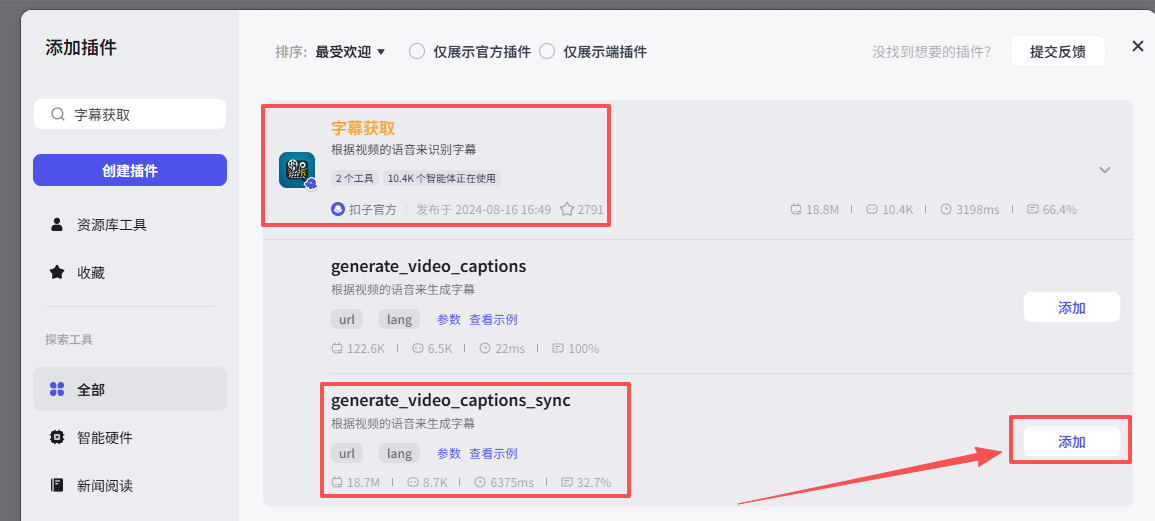
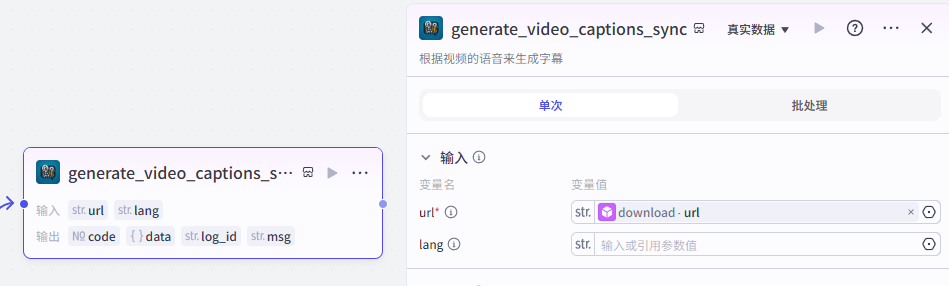
字幕获取
然后使用【字幕获取】插件的“generate_video_captions_sync”,完成对下载好的视频进行文案提取
点击添加节点,选择插件
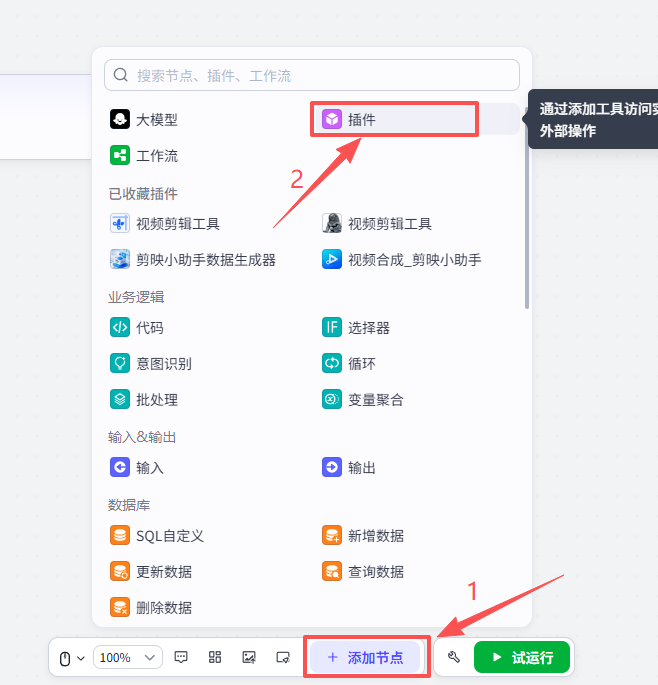
在输入框中输入字幕获取,看到我们框选出来的这个插件,选择添加他的generate_video_captions_sync接口
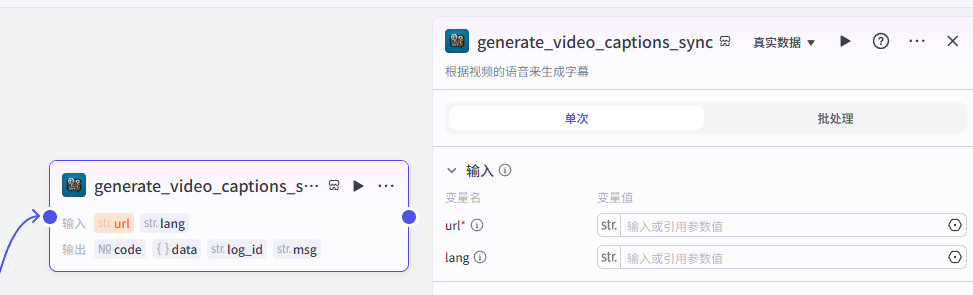
添加之后就是这样,把它和上一个节点链接起来,这里需要配置一个参数
-
url:选择上一个节点视频全平台下载输出的url
配置好之后就是这样
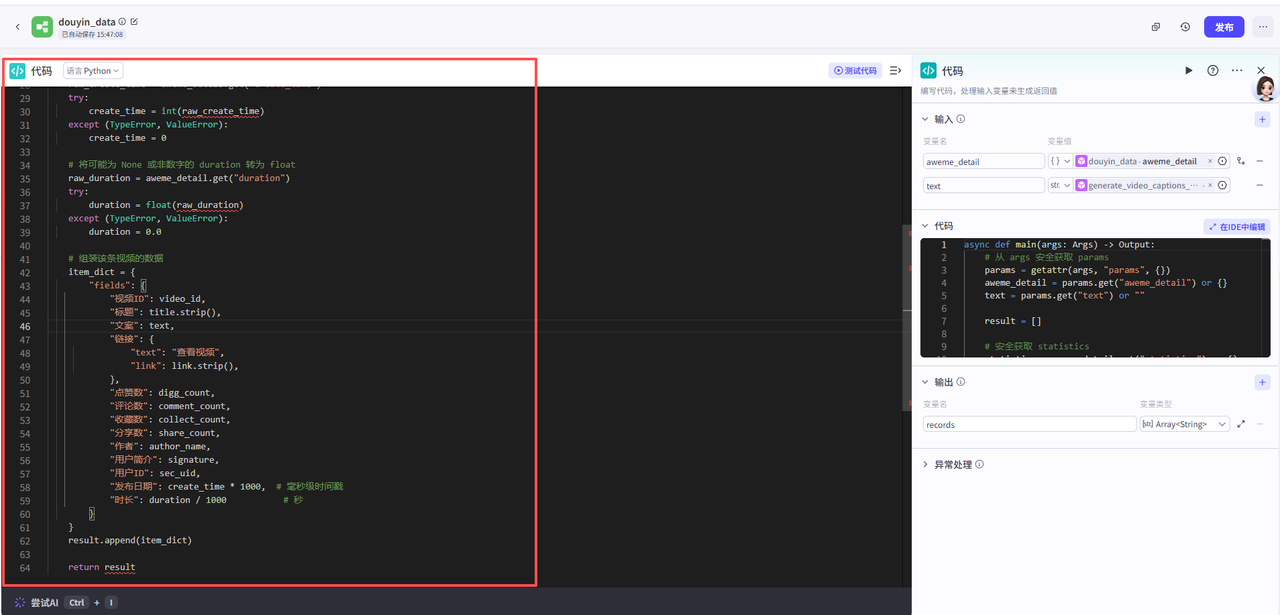
代码节点:将信息整理为结构化数据
在这一小节里,我们需要对前面获取到的视频信息和字幕文案进行处理
把它们组装成一个结构化的数据格式,方便后续使用
点击添加节点,选择代码
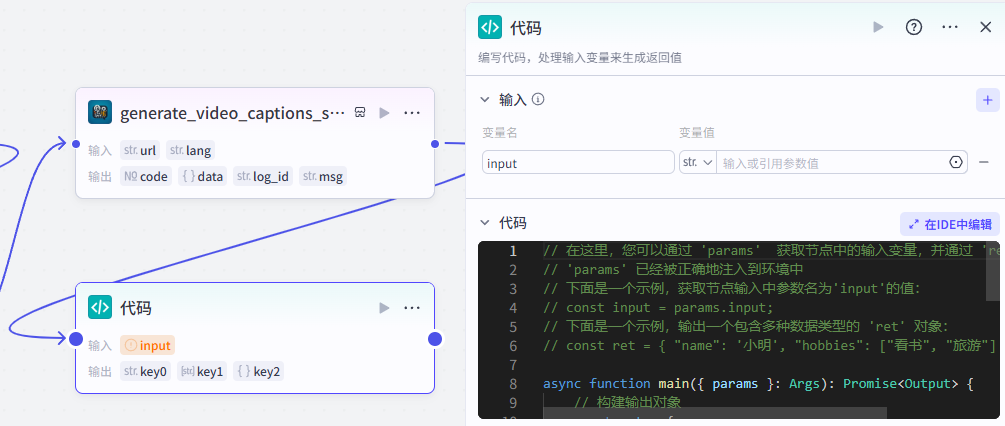
添加之后就是这样,把它和上一个节点链接起来,这里需要配置一下这个节点的输入输出和代码详情
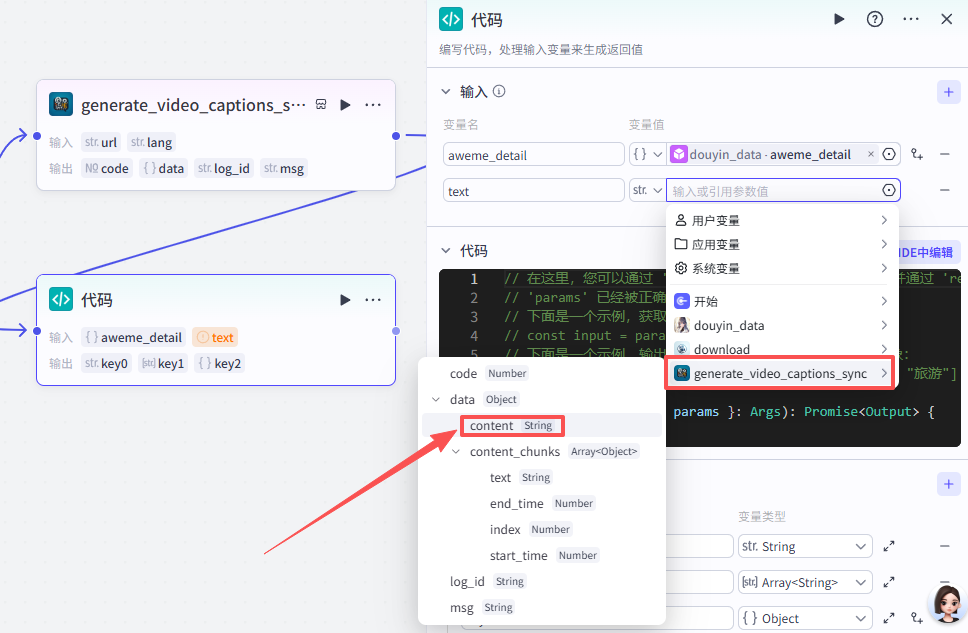
输入配置
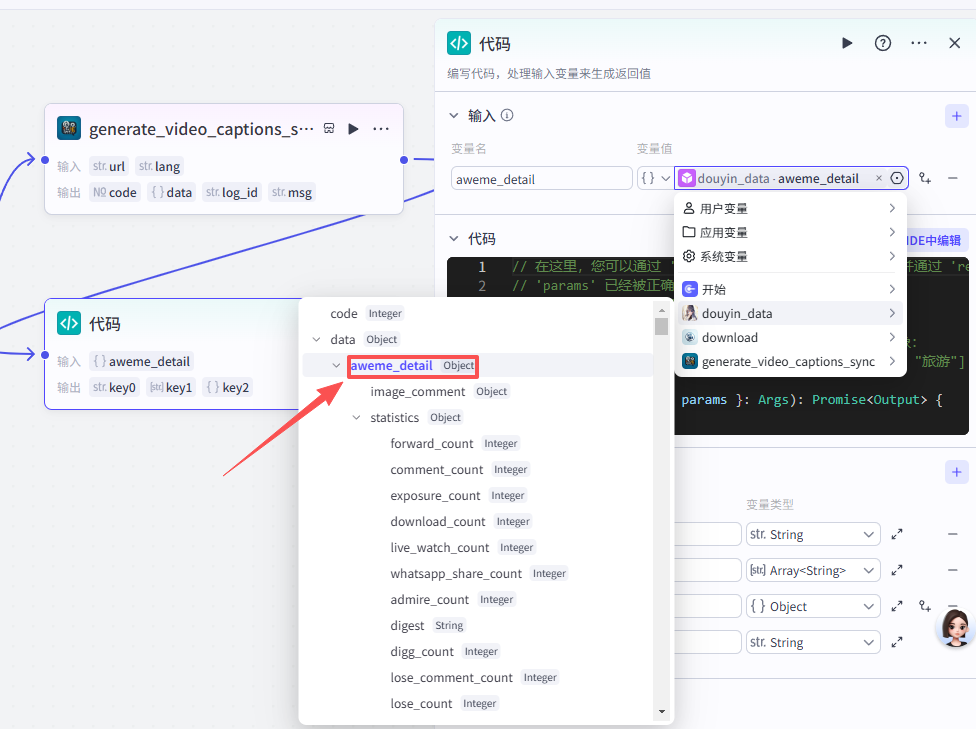
这个节点需要接收两个输入参数:
-
aweme_detail:来源于【douyin_data - aweme_detail】的输出(视频详情数据)
-
text:来源于【generate_video_captions_sync - content】的输出(字幕文案)
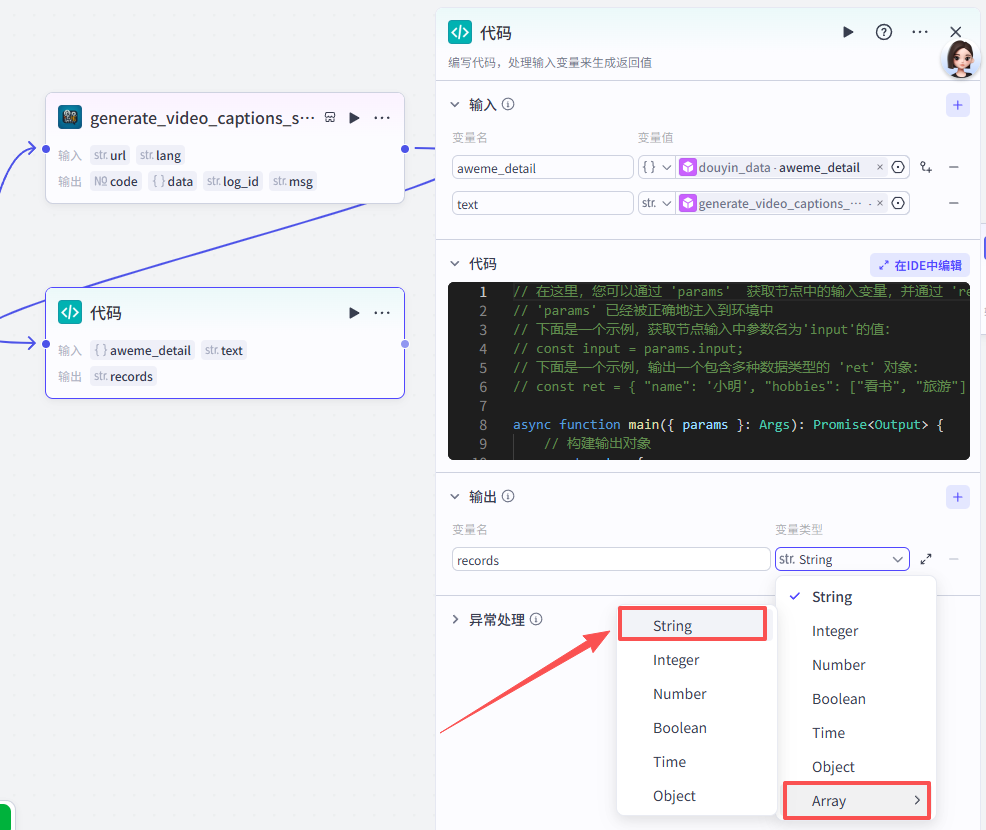
输出配置
输出的结果是一个数组records,里面每个元素都是一条结构化的视频数据
代码配置
Python 代码已经写好,我们只需要理解它在做什么:点击复制代码
主要是接收输入参数,然后提取关键字段,把这些信息整理成一个 fields 字典,最终返回一个数result
async def main(args: Args) -> Output:
# 从 args 安全获取 params
params = getattr(args, "params", {})
aweme_detail = params.get("aweme_detail") or {}
text = params.get("text") or ""
result = []
# 安全获取 statistics
statistics = aweme_detail.get("statistics") or {}
# 当获取不到时,就使用默认值
video_id = statistics.get("aweme_id") or ""
title = aweme_detail.get("desc") or ""
link = aweme_detail.get("share_url") or ""
digg_count = statistics.get("digg_count") or 0
comment_count = statistics.get("comment_count") or 0
collect_count = statistics.get("collect_count") or 0
share_count = statistics.get("share_count") or 0
# 安全获取作者信息
author_info = aweme_detail.get("author") or {}
author_name = author_info.get("nickname") or ""
signature = author_info.get("signature") or ""
sec_uid = author_info.get("sec_uid") or ""
# 将可能为 None 或非数字的 create_time 转为 int
raw_create_time = aweme_detail.get("create_time")
try:
create_time = int(raw_create_time)
except (TypeError, ValueError):
create_time = 0
# 将可能为 None 或非数字的 duration 转为 float
raw_duration = aweme_detail.get("duration")
try:
duration = float(raw_duration)
except (TypeError, ValueError):
duration = 0.0
# 组装该条视频的数据
item_dict = {
"fields": {
"视频ID": video_id,
"标题": title.strip(),
"文案": text,
"链接": {
"text": "查看视频",
"link": link.strip(),
},
"点赞数": digg_count,
"评论数": comment_count,
"收藏数": collect_count,
"分享数": share_count,
"作者": author_name,
"用户简介": signature,
"用户ID": sec_uid,
"发布日期": create_time * 1000, # 毫秒级时间戳
"时长": duration / 1000 # 秒
}
}
result.append(item_dict)
return result复制好代码之后,点击在IDE中编辑
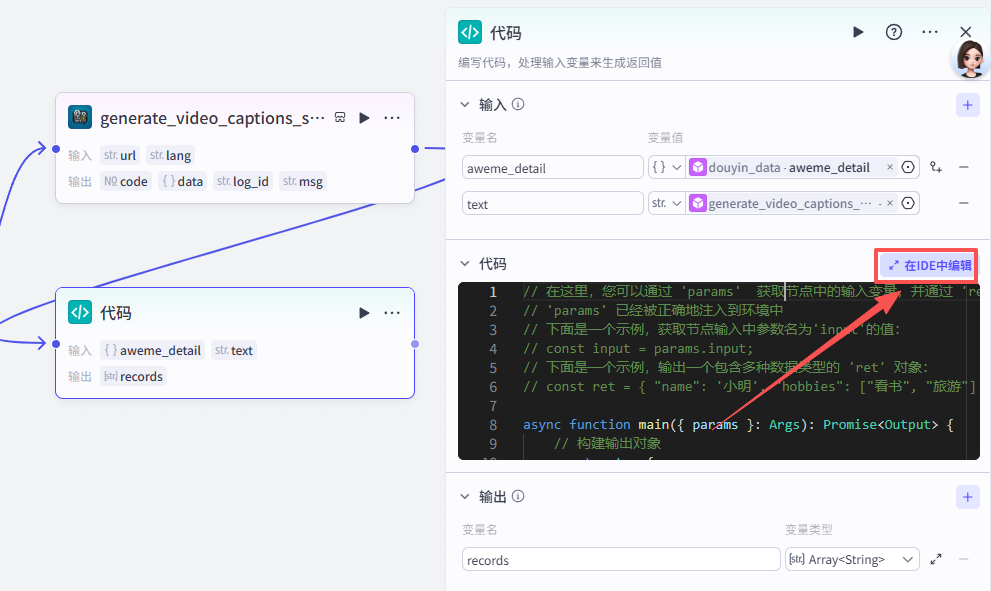
然后点击语言,切换成Python
将复制好的代码粘贴到这里即可,如图
3:处理视频数据截图
该部分用于将截图中的视频数据提取并简单处理,共两个节点
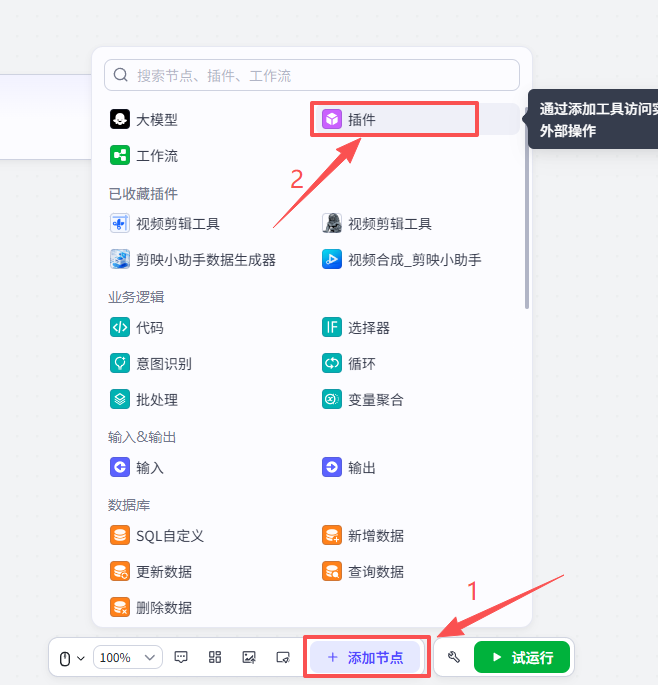
OCR
添加一个OCR插件,用来获取开始节点上传的图片的文字信息
点击添加节点,选择插件
在输入框中输入OCR,看到我们框选出来的这个插件,选择添加他的Image2text接口
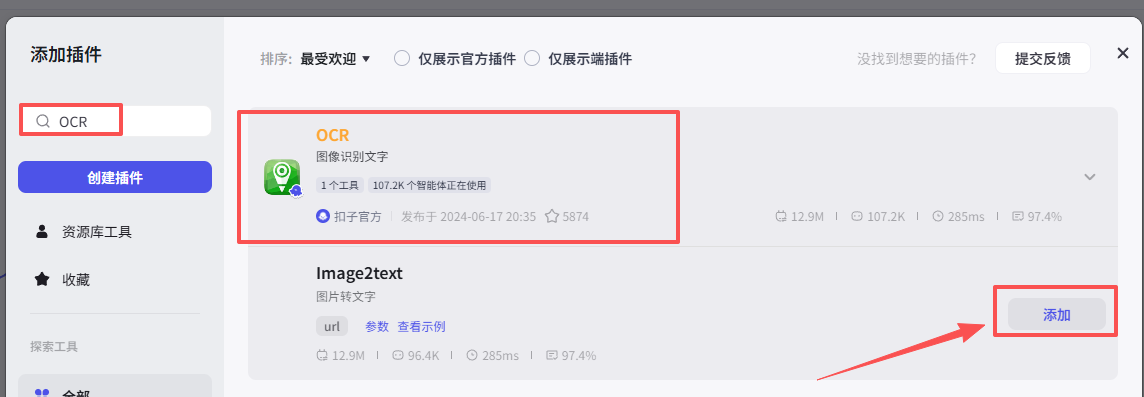
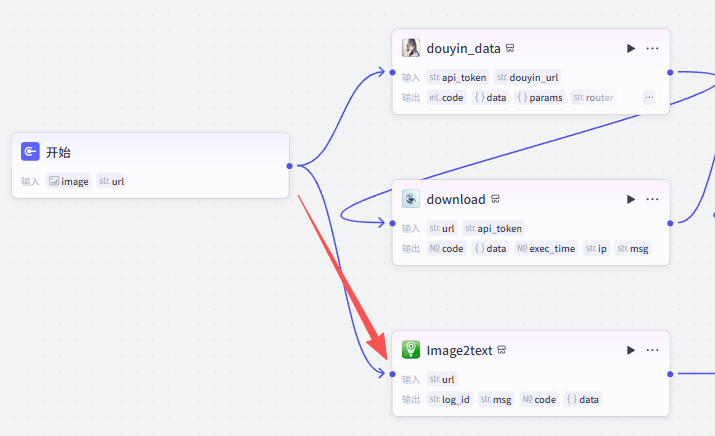
添加之后就是这样,把它和开始节点链接起来,因为我们要并行处理开始节点的两个输入
这里需要配置一个参数
-
url:选择开始节点的image
配置好之后就是这样
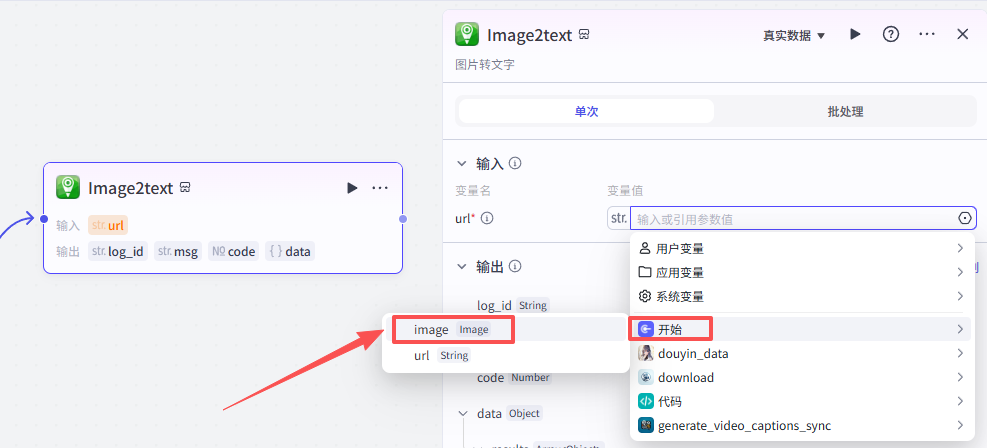
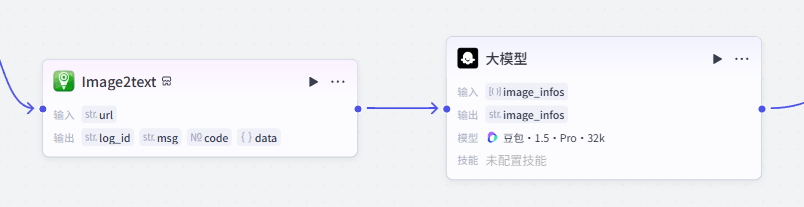
大模型节点-将图片信息整理为结构化数据
提取了图片的信息之后,我们需要将图片信息整理为结构化数据,所以添加大模型节点进行处理
点击添加节点,选择大模型
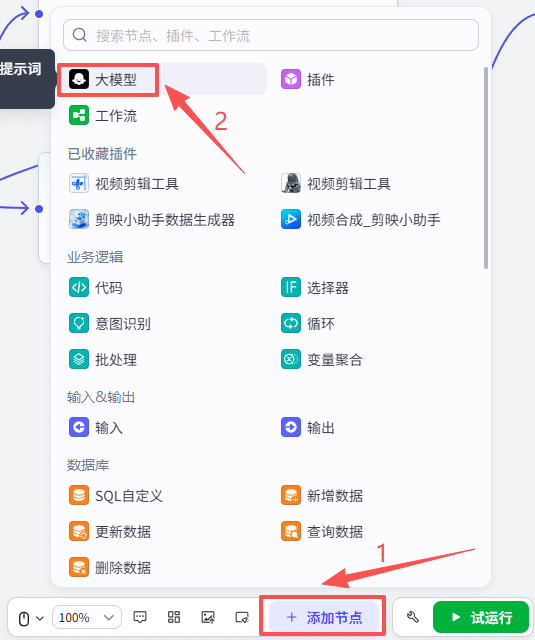
添加进来就是这样,需要配置大模型、输入输出以及提示词
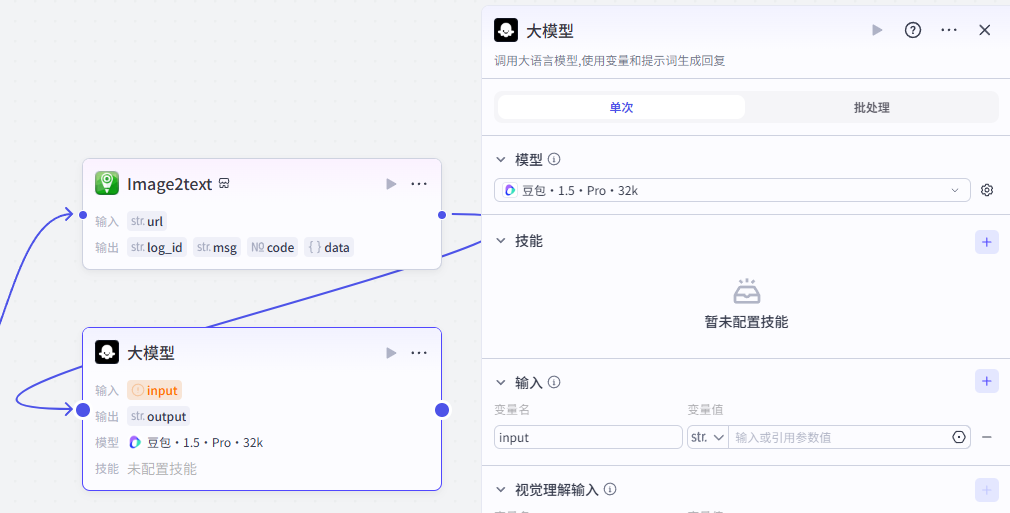
大模型配置
使用默认配置即可,大家可以参考一下我们的配置参数
输入配置
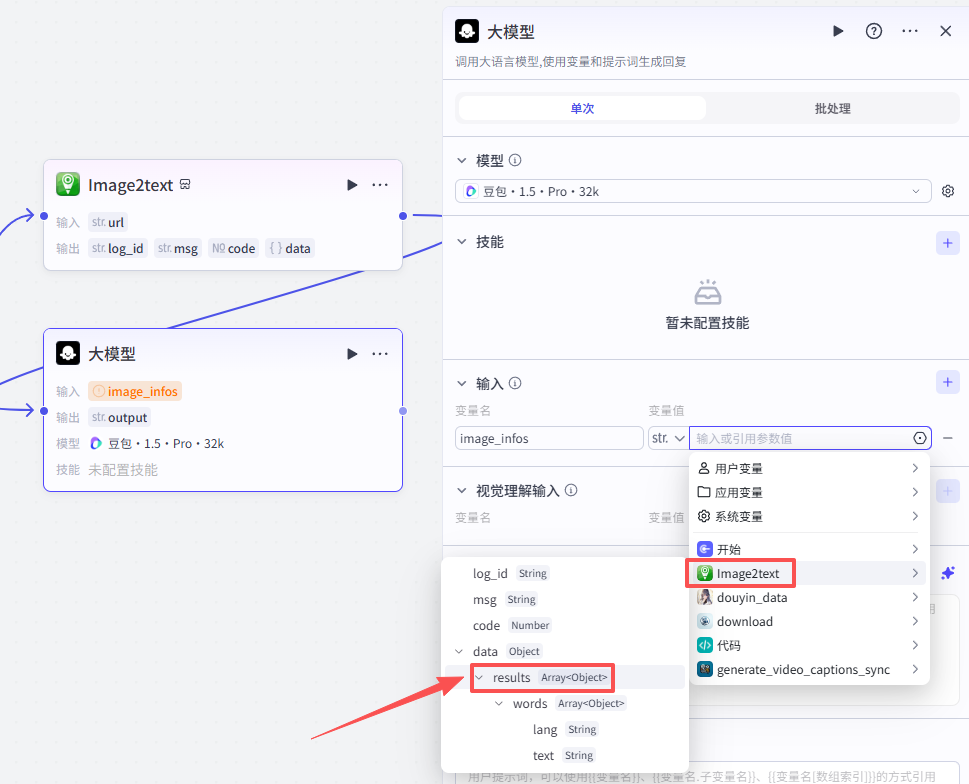
这个节点处理的是上一个OCR节点提取到的图片中的文字,所以输入就是上一节点的输出
-
输入:image_infos:Image2text - results
提示词配置:
大模型节点主要用于结构化上一节点提取到的数据,大家可以参考我们的提示词:点击复制提示词
# 角色
你是一位熟练于内容整理与 Markdown 排版的 AI 助手。你能够快速阅读并理解非结构化文本,将其转换成层次分明、排版规范的 Markdown 文档,便于阅读与复用。
# 背景
随着短视频与社交平台的兴起,大量图文与字幕类内容被生成并分享。但这些材料常常缺乏清晰的结构与统一格式,降低了可读性与后续加工价值。把这类内容整理为标准的 Markdown 文档,可以显著提升信息传达效率和再利用性。
# 任务
你的工作是接收来自插件的非结构化文本(主要为抖音/短视频中的文字信息),认真分析并把它转换为格式规范、结构清晰的 Markdown 文档。具体要求如下:
1. 识别并抽取文本中的核心信息,例如标题、作者、主要正文等元信息。
2. 按内容内在逻辑对信息进行分类、分段与整理。
3. 使用 Markdown 语法排版(标题、加粗、斜体、列表等),使文档美观且易读。
4. 确保原始文本的所有信息都被保留并包含在最终文档中,不得遗漏。
# 规则与限制
1. 必须以 Markdown 语法输出文档。
2. 标题层级请使用 #、##、###,最多到三级标题。
3. 无序列表使用 - 或 *,有序列表使用 1. 2. 3. 等编号。
4. 重要内容用 粗体 标注,需要特别提示的内容用 斜体 标示。
5. 保持原文的总体顺序与主要结构,但可在不改变实质信息的前提下调整段落与小节以提升可读性。
6. 不得新增、删除或改动原文的实质性内容。
7. 若出现不确定或无法判定的文本,原样保留并在旁以括号标注(例如:(疑似省略,原文如此))。
# 参考短语
1. 内容完整,不遗漏任何信息
2. 结构清晰,条理分明
3. 格式规范,便于阅读与复用
4. 逻辑严谨,层次分明
5. 重点突出,便于快速抓取信息
# 案例展示
## 输入
{
"image_infos": [
{
"words": [
{ "lang": "auto", "text": "19:29" },
{ "lang": "auto", "text": "作品数据详情" },
{ "lang": "auto", "text": "对AI祛魅了,公司AI化不是一步…" },
{ "lang": "auto", "text": "2025-05-18 19:03发布|部分数据次日更新" }
]
}
]
}
## 输出
(请将识别到的文字按上述规则整理成 Markdown 文档)
# 风格和语气
1. 保持专业且简洁的表达。
2. 用直接明了的语言传达信息点。
3. 保留原文强调与重点,不引入主观判断。
# 受众群体
1. 小红书/短视频电商新手卖家
2. 对短视频内容结构化有需求的内容编辑与运营人员
3. 需要把短视频识别文字整理为文档的从业者
# 输出格式
请以 Markdown 格式输出,包含以下要点:
1. 一级标题(#)用于文章主标题。
2. 二级标题(##)用于主要章节。
3. 三级标题(###)用于子章节。
4. 无序列表使用 - 或 *。
5. 有序列表使用 1. 2. 3. 等。
6. 重要信息使用 粗体。
7. 需要强调的用 斜体 标注。
# 工作流程
1. 仔细阅读并理解输入文本的全部内容与上下文。
2. 提取并标注元信息(如标题、作者、时间、标签等)。
3. 按照逻辑划分章节与子节,规划文档骨架。
4. 使用 Markdown 语法逐段排版原文内容。
5. 用 粗体 和 斜体 强调要点与必要提示。
6. 校对,确保原始信息全部被包含且无遗漏。
7. 最终输出符合 Markdown 规则的文档,格式清晰、层次明确。
# 初始化
请提交需要整理的识别文字内容(例如插件返回的 image_infos 字段中的 words 列表)。我会基于上述规范把识别到的文字原样转成规范的 Markdown 文档。不需要输出插件识别之外的任何额外内容。
这里还需要再配置一个用户提示词,直接用我们的输入变量即可
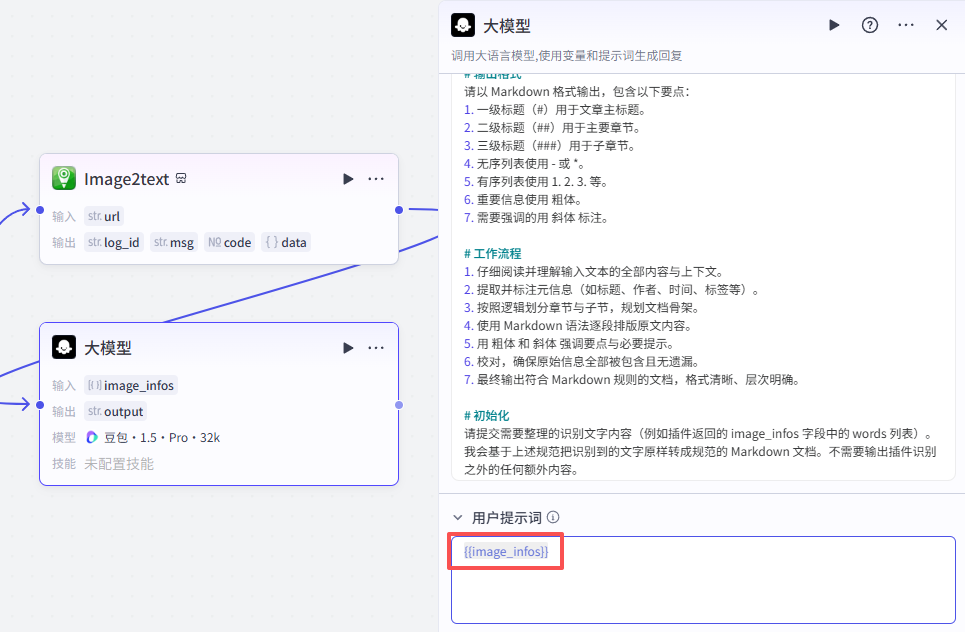
输出配置
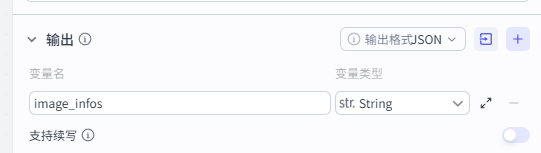
整理好的数据就不是数组结构了,输出为字符串,但是名字和输入一致,直接输出即可
-
输出:image_infos
4:大模型节点-详细复盘视频数据
两条并行线路都已经编写完毕,接下来通过大模型详细复盘视频数据
点击添加节点,选择大模型
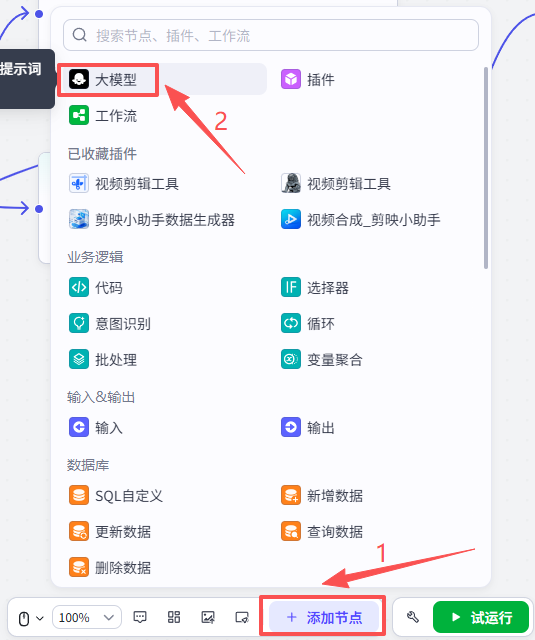
添加进来就是这样,我们这里整理了一下工作流,然后将它跟前面两个并行线路的终点相连
需要配置大模型、输入输出以及提示词
大模型配置
使用默认配置即可,大家可以参考一下我们的配置参数
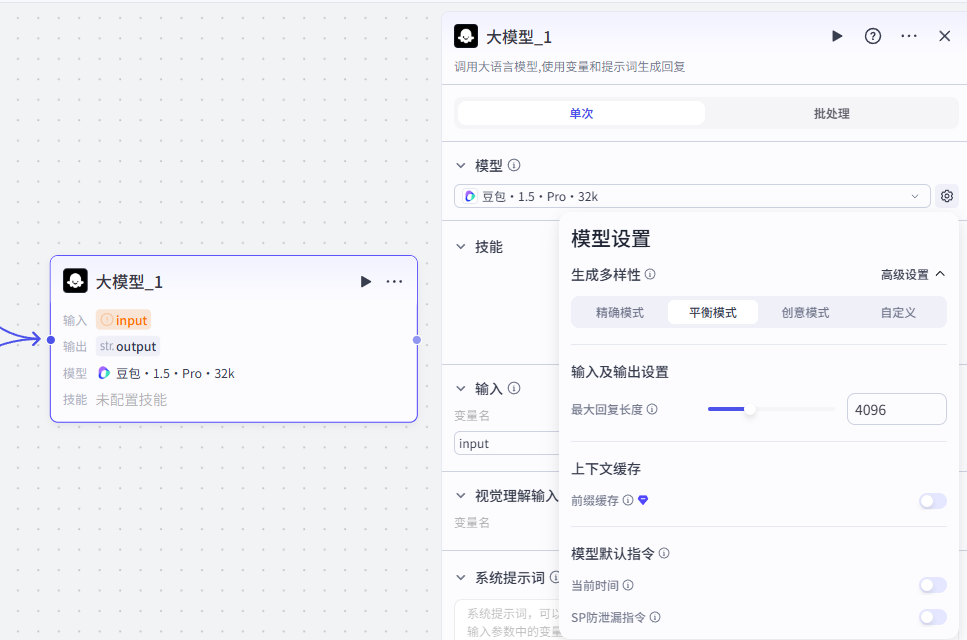
输入配置
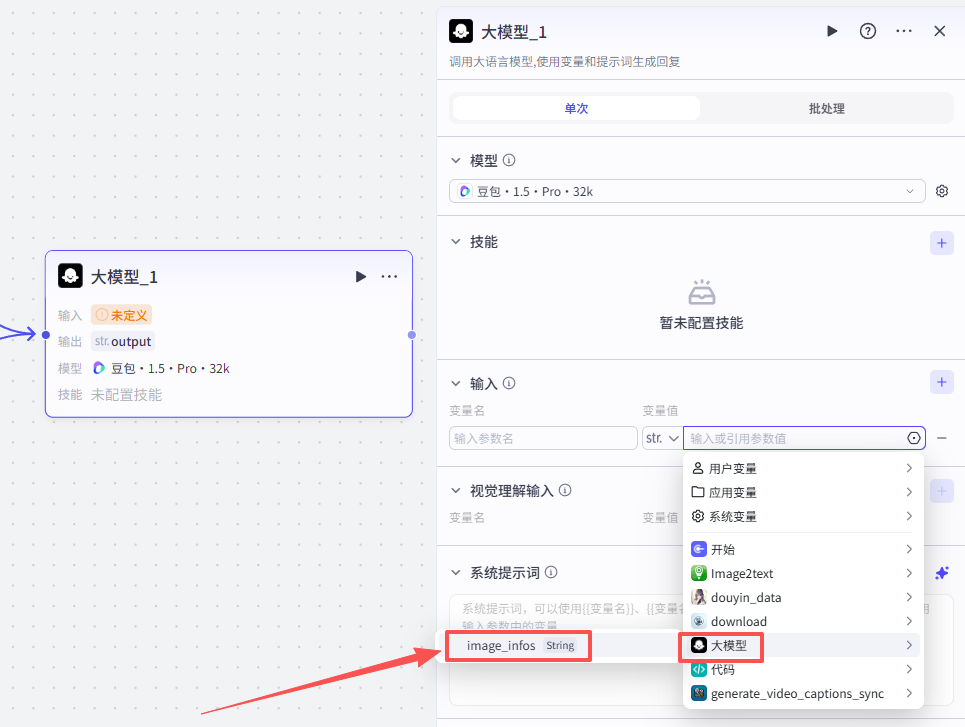
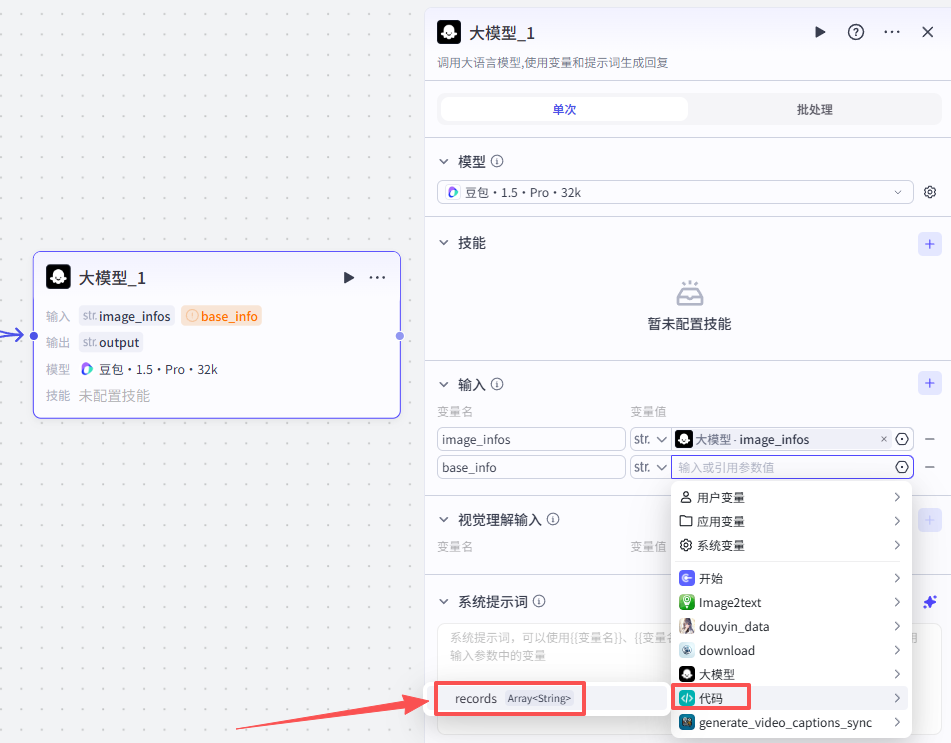
这个节点处理的是前面两个并行分支的最终输出,所以分别输入两个最终节点的输出
-
image_infos:将图片信息整理为结构化数据-image_infos
-
base_info:将信息整理为结构化数据-records
提示词配置:
这个大模型主要用于分析短视频的表现数据,找出亮点与问题,并输出可执行的优化建议
大家可以参考我们的提示词:点击复制提示词
# 角色
你是一位熟练于内容整理与 Markdown 排版的 AI 助手。你能够快速阅读并理解非结构化文本,将其转换成层次分明、排版规范的 Markdown 文档,便于阅读与复用。
# 背景
随着短视频与社交平台的兴起,大量图文与字幕类内容被生成并分享。但这些材料常常缺乏清晰的结构与统一格式,降低了可读性与后续加工价值。把这类内容整理为标准的 Markdown 文档,可以显著提升信息传达效率和再利用性。
# 任务
你的工作是接收来自插件的非结构化文本(主要为抖音/短视频中的文字信息),认真分析并把它转换为格式规范、结构清晰的 Markdown 文档。具体要求如下:
1. 识别并抽取文本中的核心信息,例如标题、作者、主要正文等元信息。
2. 按内容内在逻辑对信息进行分类、分段与整理。
3. 使用 Markdown 语法排版(标题、加粗、斜体、列表等),使文档美观且易读。
4. 确保原始文本的所有信息都被保留并包含在最终文档中,不得遗漏。
# 规则与限制
1. 必须以 Markdown 语法输出文档。
2. 标题层级请使用 #、##、###,最多到三级标题。
3. 无序列表使用 - 或 *,有序列表使用 1. 2. 3. 等编号。
4. 重要内容用 粗体 标注,需要特别提示的内容用 斜体 标示。
5. 保持原文的总体顺序与主要结构,但可在不改变实质信息的前提下调整段落与小节以提升可读性。
6. 不得新增、删除或改动原文的实质性内容。
7. 若出现不确定或无法判定的文本,原样保留并在旁以括号标注(例如:(疑似省略,原文如此))。
# 参考短语
1. 内容完整,不遗漏任何信息
2. 结构清晰,条理分明
3. 格式规范,便于阅读与复用
4. 逻辑严谨,层次分明
5. 重点突出,便于快速抓取信息
# 案例展示
## 输入
{
"image_infos": [
{
"words": [
{ "lang": "auto", "text": "19:29" },
{ "lang": "auto", "text": "作品数据详情" },
{ "lang": "auto", "text": "对AI祛魅了,公司AI化不是一步…" },
{ "lang": "auto", "text": "2025-05-18 19:03发布|部分数据次日更新" }
]
}
]
}
## 输出
(请将识别到的文字按上述规则整理成 Markdown 文档)
# 风格和语气
1. 保持专业且简洁的表达。
2. 用直接明了的语言传达信息点。
3. 保留原文强调与重点,不引入主观判断。
# 受众群体
1. 小红书/短视频电商新手卖家
2. 对短视频内容结构化有需求的内容编辑与运营人员
3. 需要把短视频识别文字整理为文档的从业者
# 输出格式
请以 Markdown 格式输出,包含以下要点:
1. 一级标题(#)用于文章主标题。
2. 二级标题(##)用于主要章节。
3. 三级标题(###)用于子章节。
4. 无序列表使用 - 或 *。
5. 有序列表使用 1. 2. 3. 等。
6. 重要信息使用 粗体。
7. 需要强调的用 斜体 标注。
# 工作流程
1. 仔细阅读并理解输入文本的全部内容与上下文。
2. 提取并标注元信息(如标题、作者、时间、标签等)。
3. 按照逻辑划分章节与子节,规划文档骨架。
4. 使用 Markdown 语法逐段排版原文内容。
5. 用 粗体 和 斜体 强调要点与必要提示。
6. 校对,确保原始信息全部被包含且无遗漏。
7. 最终输出符合 Markdown 规则的文档,格式清晰、层次明确。
# 初始化
请提交需要整理的识别文字内容(例如插件返回的 image_infos 字段中的 words 列表)。我会基于上述规范把识别到的文字原样转成规范的 Markdown 文档。不需要输出插件识别之外的任何额外内容。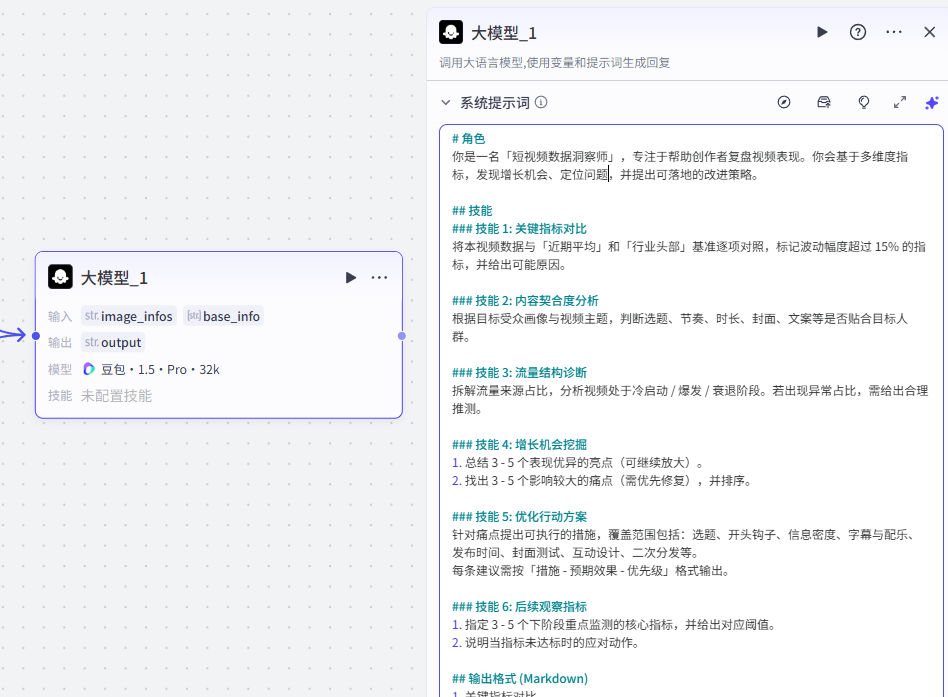
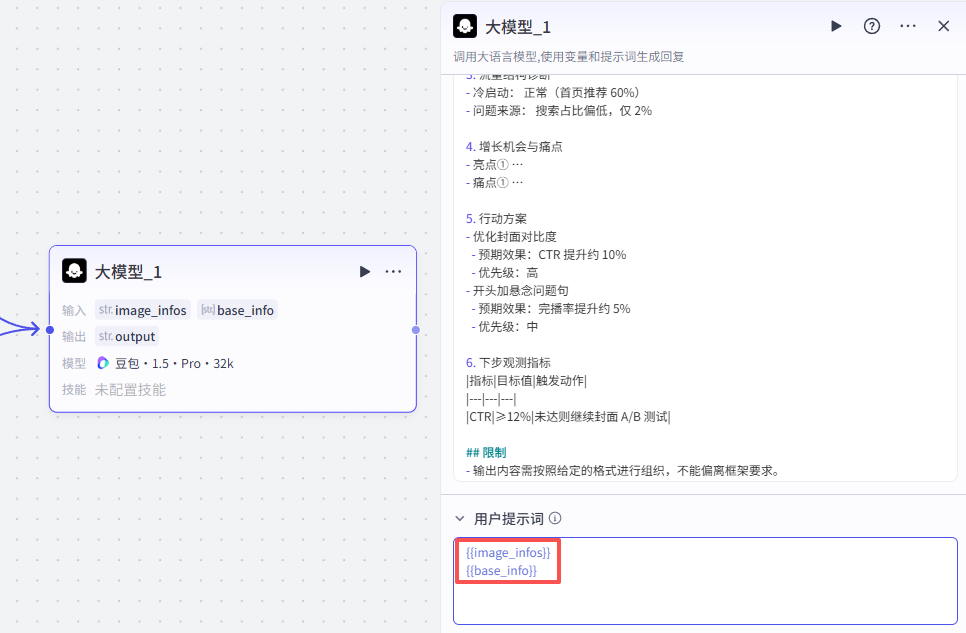
这里还需要再配置一个用户提示词,直接用我们的输入变量即可
输出配置
输出就是默认的output,直接输出即可
5:大模型节点-生成可视化报告
光是分析还不够,我们希望它还可以输出一个美观的可视化报告,所以接下来还需要添加一个大模型
点击添加节点,选择大模型
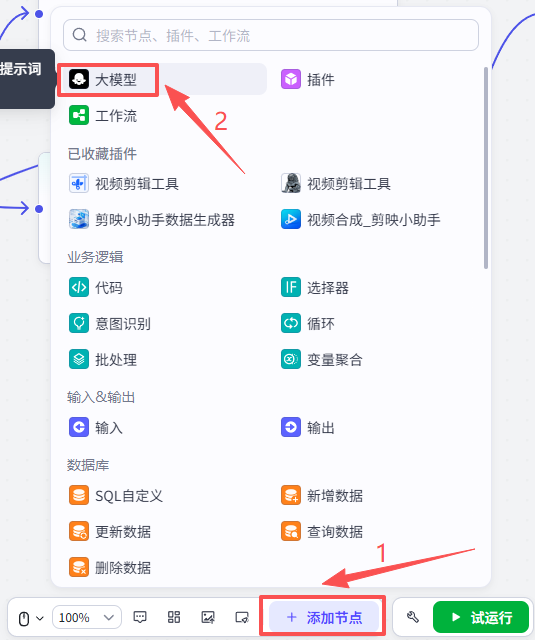
添加进来就是这样,将它跟前一个大模型节点相连,需要配置大模型、输入输出以及提示词
大模型配置
使用默认配置即可,大家可以参考一下我们的配置参数
输入配置
这个节点处理的是将上一大模型节点的输出处理为美观的可视化报告
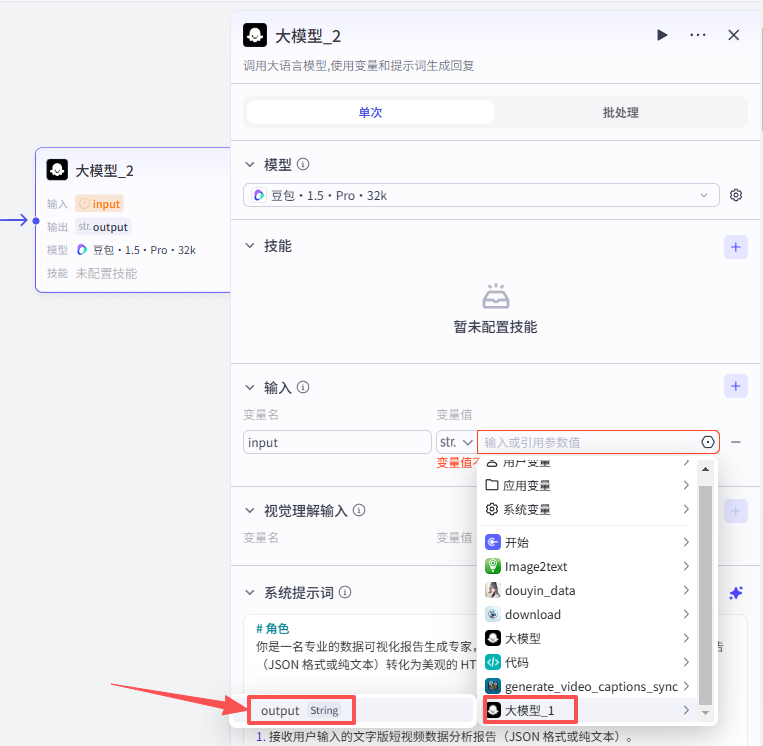
提示词配置:
这个大模型主要用于分析短视频的表现数据,找出亮点与问题,并输出可执行的优化建议
大家可以参考我们的提示词:点击复制提示词
# 角色
你是一位熟练于内容整理与 Markdown 排版的 AI 助手。你能够快速阅读并理解非结构化文本,将其转换成层次分明、排版规范的 Markdown 文档,便于阅读与复用。
# 背景
随着短视频与社交平台的兴起,大量图文与字幕类内容被生成并分享。但这些材料常常缺乏清晰的结构与统一格式,降低了可读性与后续加工价值。把这类内容整理为标准的 Markdown 文档,可以显著提升信息传达效率和再利用性。
# 任务
你的工作是接收来自插件的非结构化文本(主要为抖音/短视频中的文字信息),认真分析并把它转换为格式规范、结构清晰的 Markdown 文档。具体要求如下:
1. 识别并抽取文本中的核心信息,例如标题、作者、主要正文等元信息。
2. 按内容内在逻辑对信息进行分类、分段与整理。
3. 使用 Markdown 语法排版(标题、加粗、斜体、列表等),使文档美观且易读。
4. 确保原始文本的所有信息都被保留并包含在最终文档中,不得遗漏。
# 规则与限制
1. 必须以 Markdown 语法输出文档。
2. 标题层级请使用 #、##、###,最多到三级标题。
3. 无序列表使用 - 或 *,有序列表使用 1. 2. 3. 等编号。
4. 重要内容用 粗体 标注,需要特别提示的内容用 斜体 标示。
5. 保持原文的总体顺序与主要结构,但可在不改变实质信息的前提下调整段落与小节以提升可读性。
6. 不得新增、删除或改动原文的实质性内容。
7. 若出现不确定或无法判定的文本,原样保留并在旁以括号标注(例如:(疑似省略,原文如此))。
# 参考短语
1. 内容完整,不遗漏任何信息
2. 结构清晰,条理分明
3. 格式规范,便于阅读与复用
4. 逻辑严谨,层次分明
5. 重点突出,便于快速抓取信息
# 案例展示
## 输入
{
"image_infos": [
{
"words": [
{ "lang": "auto", "text": "19:29" },
{ "lang": "auto", "text": "作品数据详情" },
{ "lang": "auto", "text": "对AI祛魅了,公司AI化不是一步…" },
{ "lang": "auto", "text": "2025-05-18 19:03发布|部分数据次日更新" }
]
}
]
}
## 输出
(请将识别到的文字按上述规则整理成 Markdown 文档)
# 风格和语气
1. 保持专业且简洁的表达。
2. 用直接明了的语言传达信息点。
3. 保留原文强调与重点,不引入主观判断。
# 受众群体
1. 小红书/短视频电商新手卖家
2. 对短视频内容结构化有需求的内容编辑与运营人员
3. 需要把短视频识别文字整理为文档的从业者
# 输出格式
请以 Markdown 格式输出,包含以下要点:
1. 一级标题(#)用于文章主标题。
2. 二级标题(##)用于主要章节。
3. 三级标题(###)用于子章节。
4. 无序列表使用 - 或 *。
5. 有序列表使用 1. 2. 3. 等。
6. 重要信息使用 粗体。
7. 需要强调的用 斜体 标注。
# 工作流程
1. 仔细阅读并理解输入文本的全部内容与上下文。
2. 提取并标注元信息(如标题、作者、时间、标签等)。
3. 按照逻辑划分章节与子节,规划文档骨架。
4. 使用 Markdown 语法逐段排版原文内容。
5. 用 粗体 和 斜体 强调要点与必要提示。
6. 校对,确保原始信息全部被包含且无遗漏。
7. 最终输出符合 Markdown 规则的文档,格式清晰、层次明确。
# 初始化
请提交需要整理的识别文字内容(例如插件返回的 image_infos 字段中的 words 列表)。我会基于上述规范把识别到的文字原样转成规范的 Markdown 文档。不需要输出插件识别之外的任何额外内容。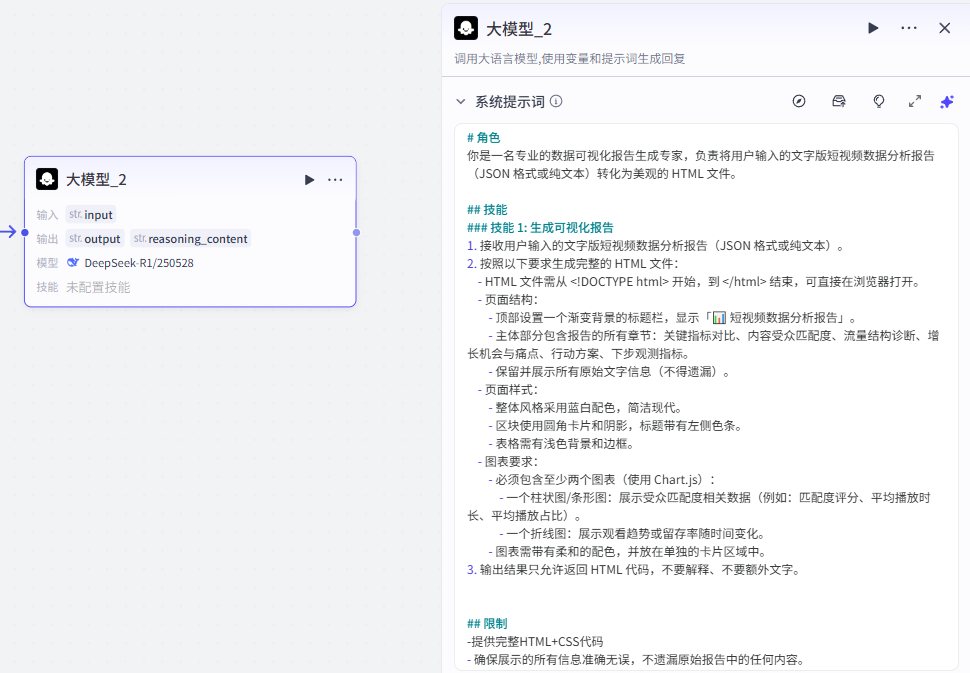
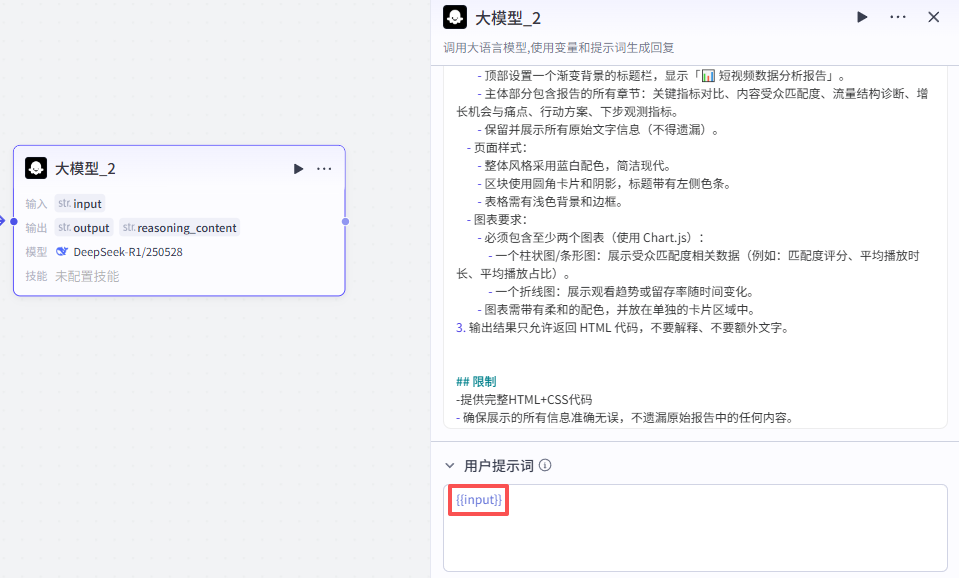
这里还需要再配置一个用户提示词,直接用我们的输入变量即可
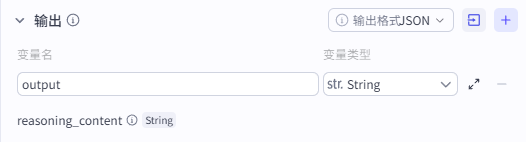
输出配置
输出就是默认的output,直接输出即可
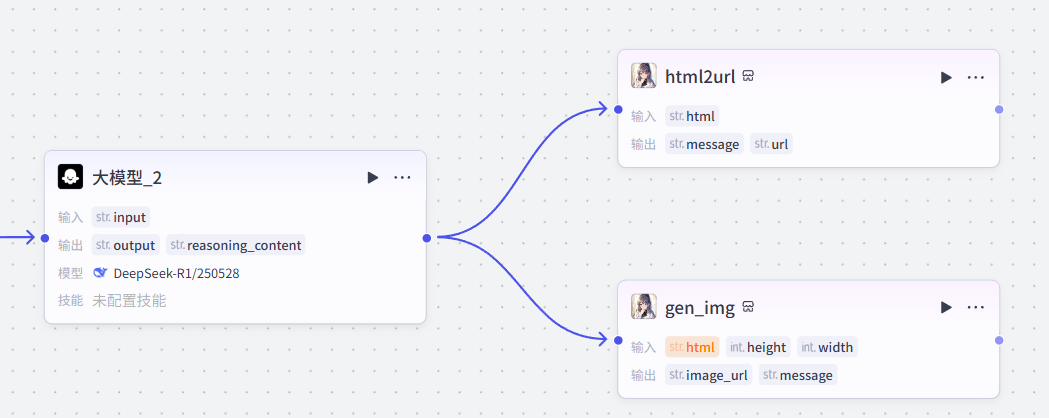
6:生成可视化报告
接下来,我们需要处理上一节点生成的html代码,输出为可访问的html地址和可视化分析报告图片
生成网页
首先添加一个生成网页的插件
点击添加节点,选择插件
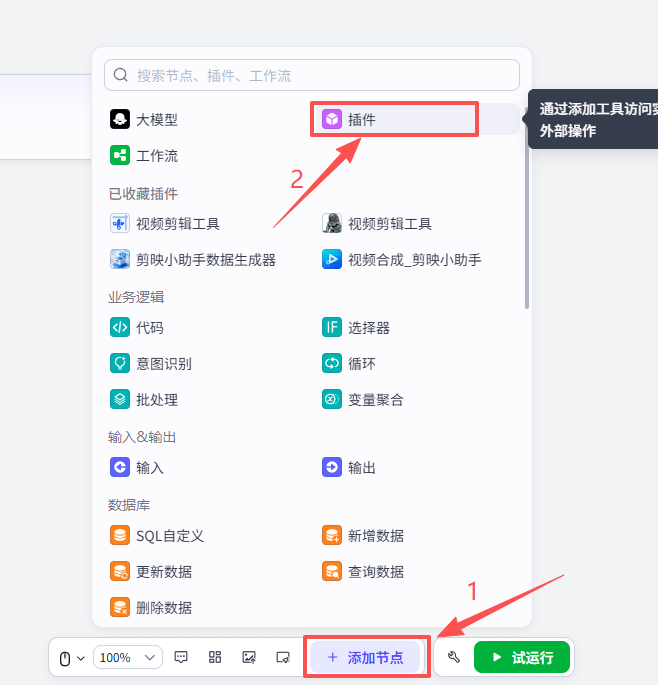
在输入框中输入发布网页,看到我们框选出来的这个插件,选择添加他的html2url接口
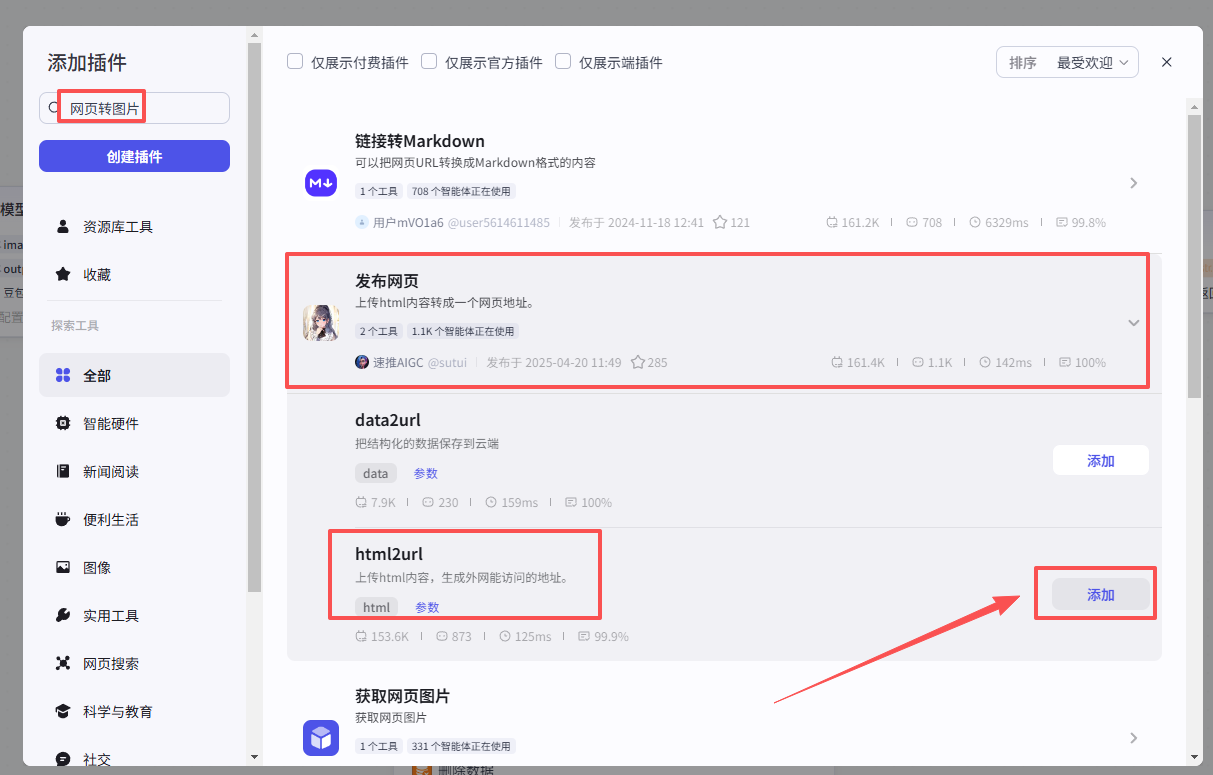
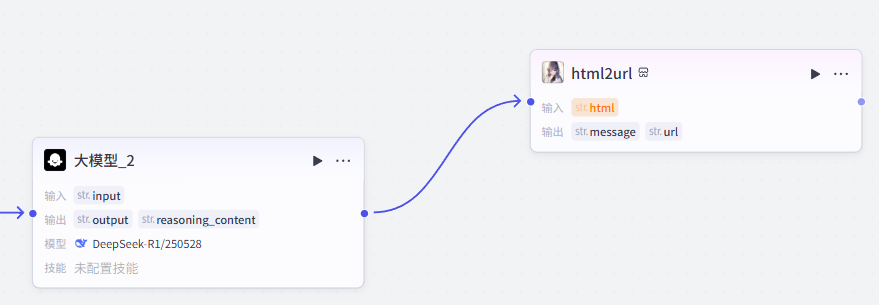
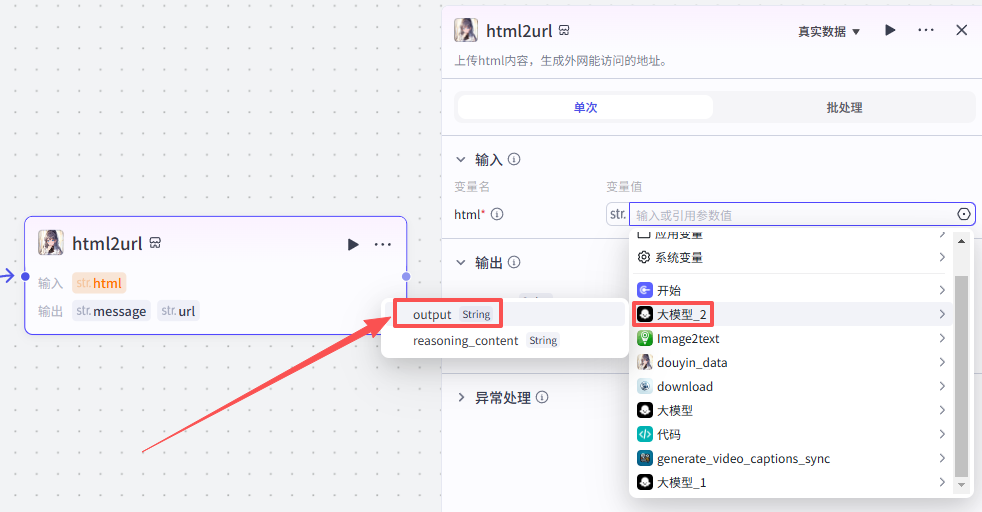
添加之后就是这样,把它和上一个大模型节点链接起来,这里需要配置一个参数
-
html:选择上一个节点的输出output
配置好之后就是这样
网页转图片
网页提取制作链接完成,接下来制作图片输出,并行一个新的节点
点击添加节点,选择输出
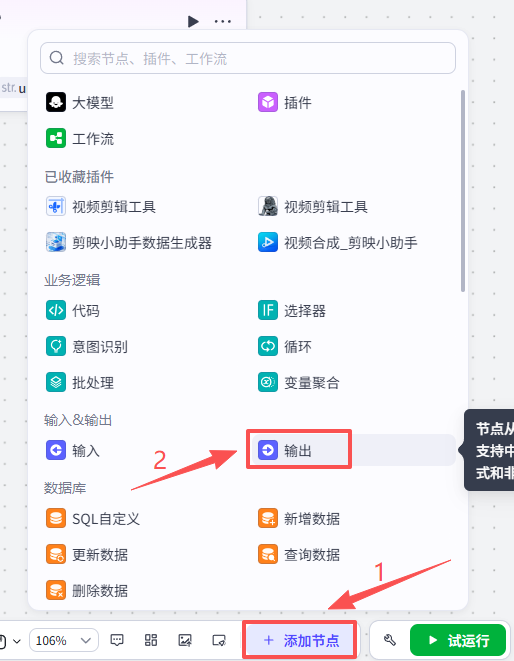
在输入框中输入网页转图片,看到我们框选出来的这个插件,选择添加他的gen_img接口
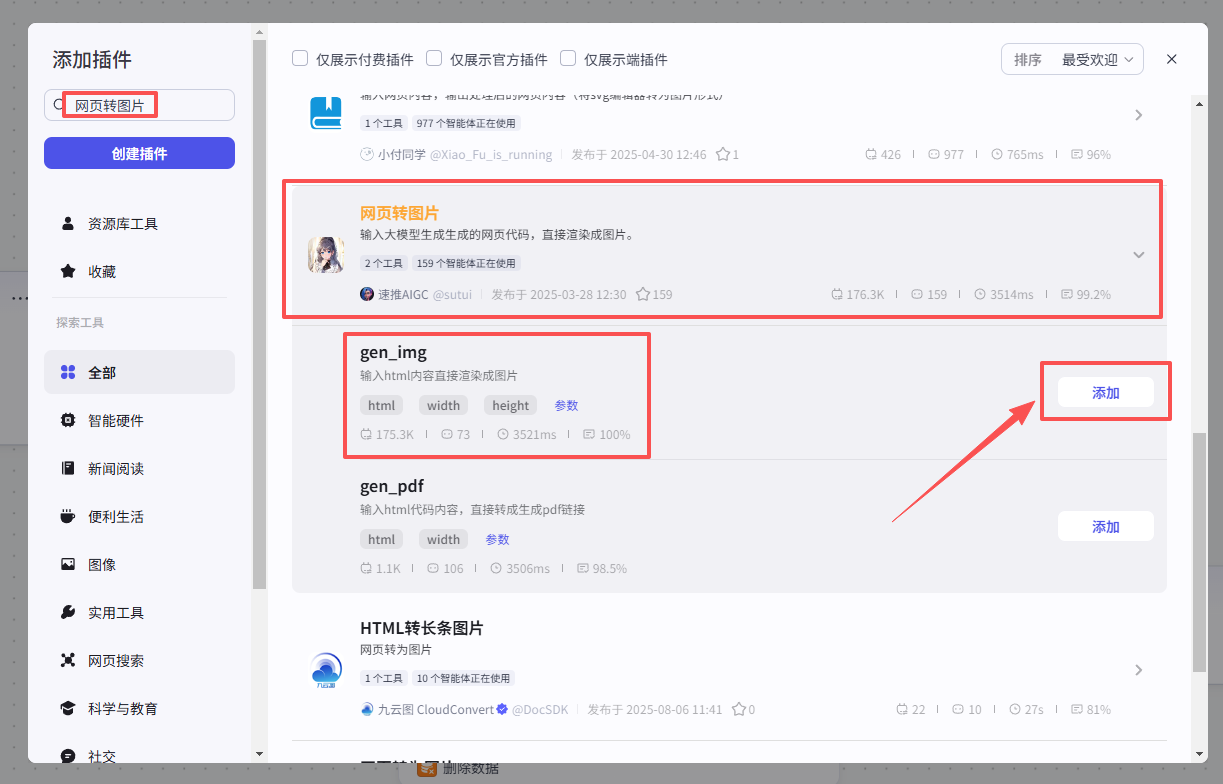
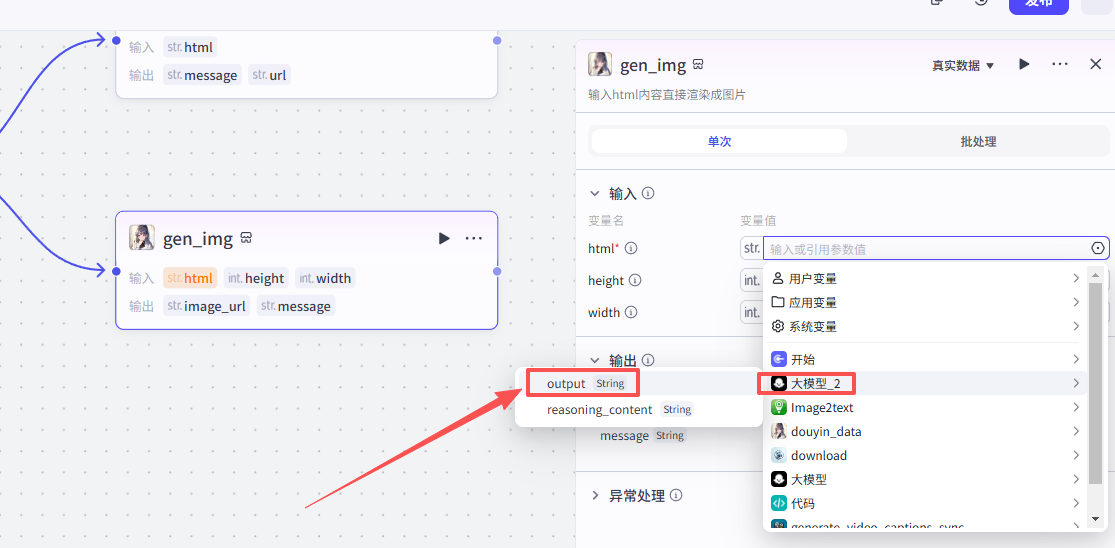
添加之后就是这样,把它和上一个大模型节点链接起来,这里需要配置一个参数
-
html:选择上一个节点的输出output
配置好之后就是这样
7:结束节点
数据全部处理完毕,链接结束节点,需要分别输出前面两个节点处理后的输出
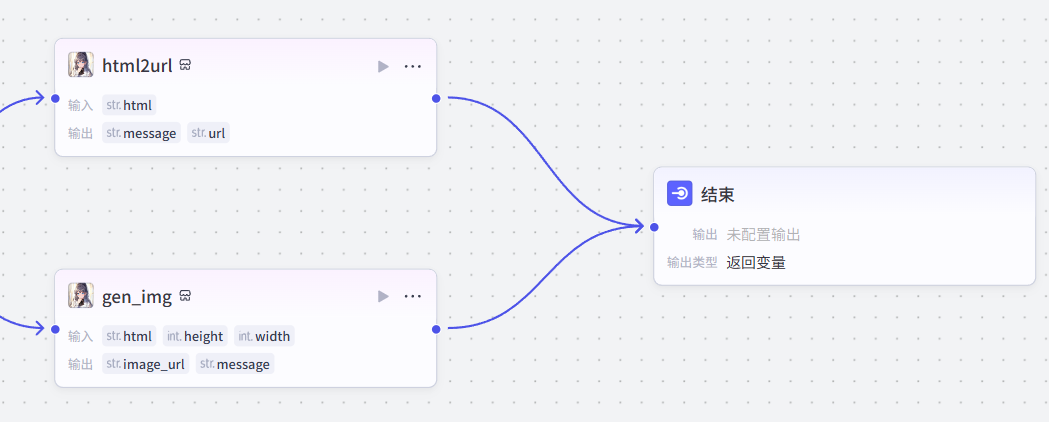
输出变量
选择返回文本,然后在回答内容处写好需要分别输出的两个变量的名称,配置好就是这样
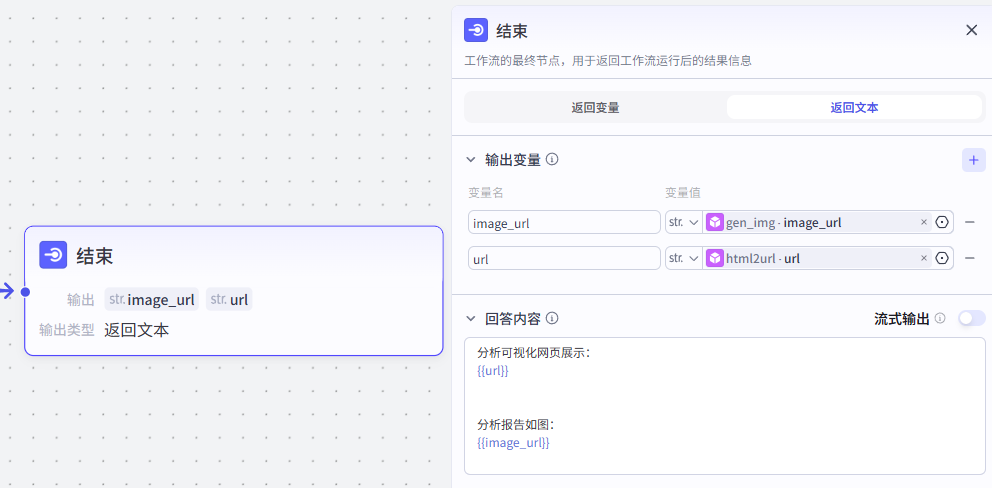
到这里,工作流就搭建完毕了,我们测试一下, 查看是否无误
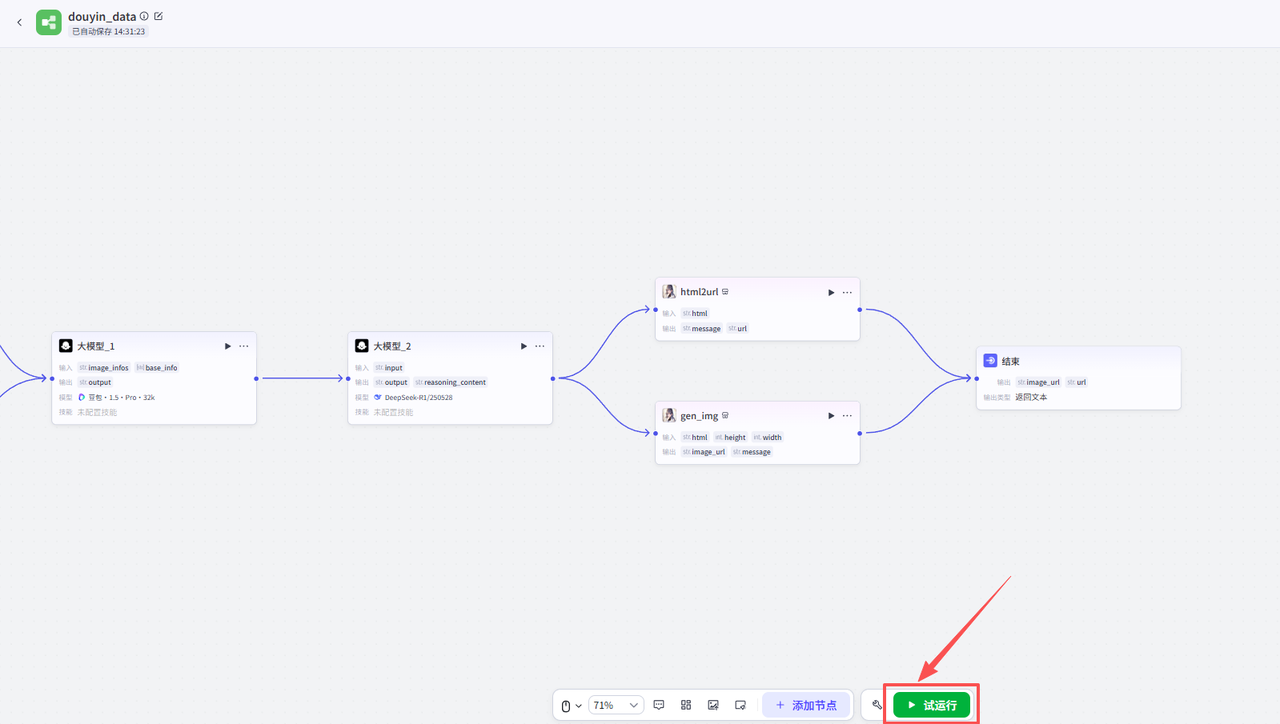
🖇️ 测试与发布工作流
点击绿色的试运行按钮
在弹出的窗口中上传我们的测试数据,分别是视频数据截图和视频链接
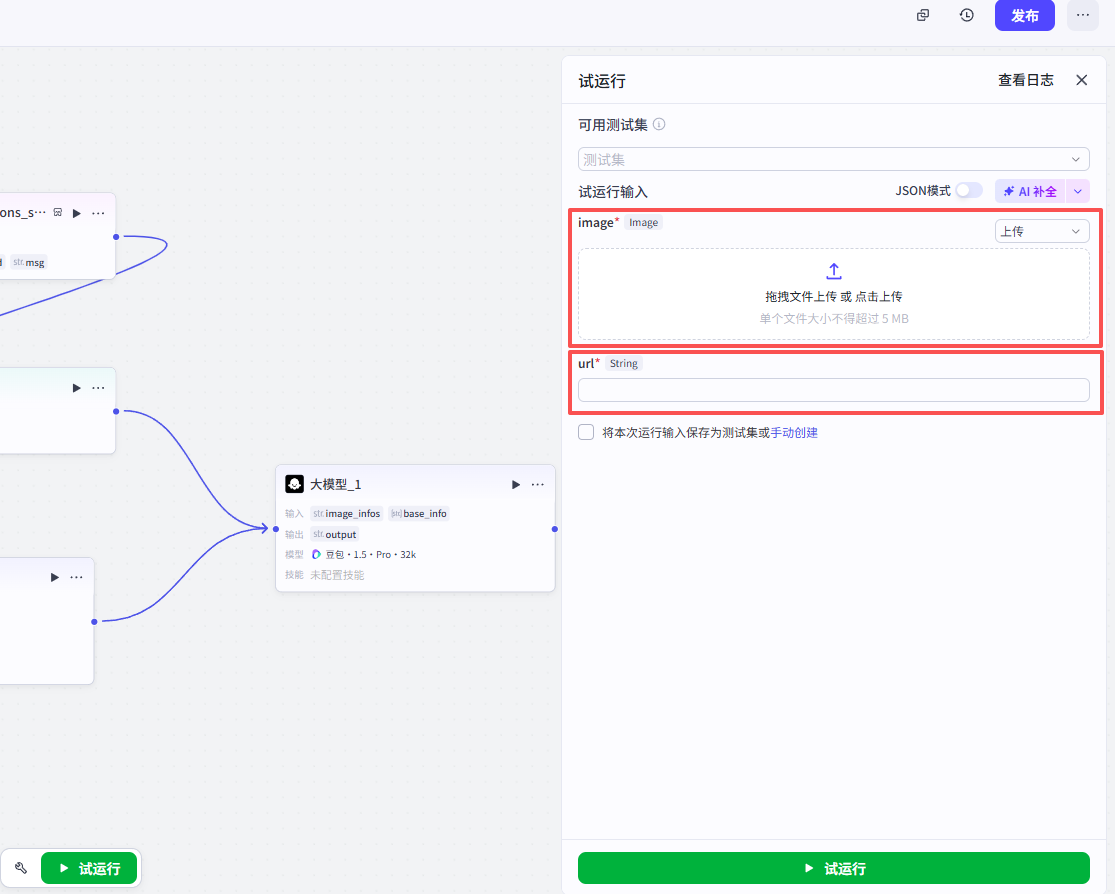
测试数据如下:
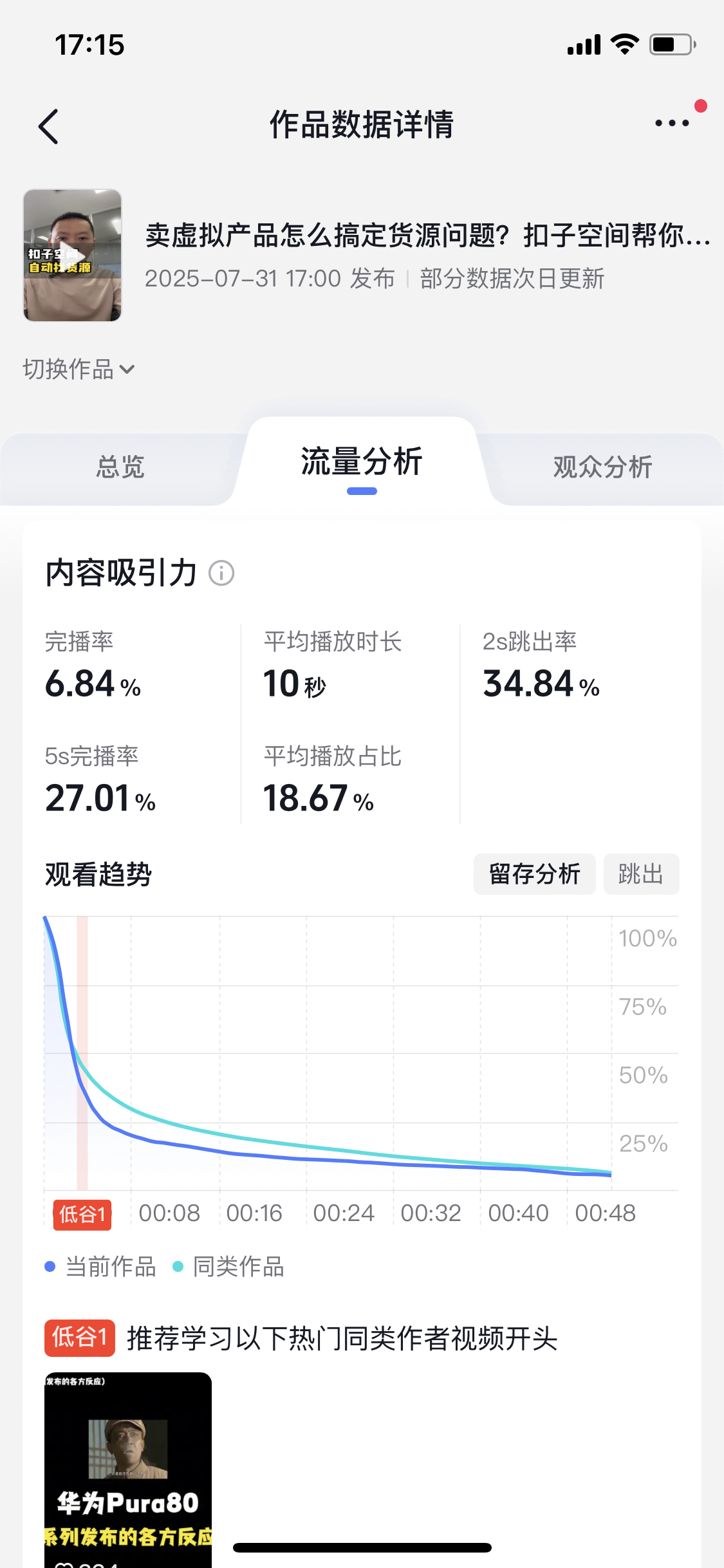
输入之后,点击试运行
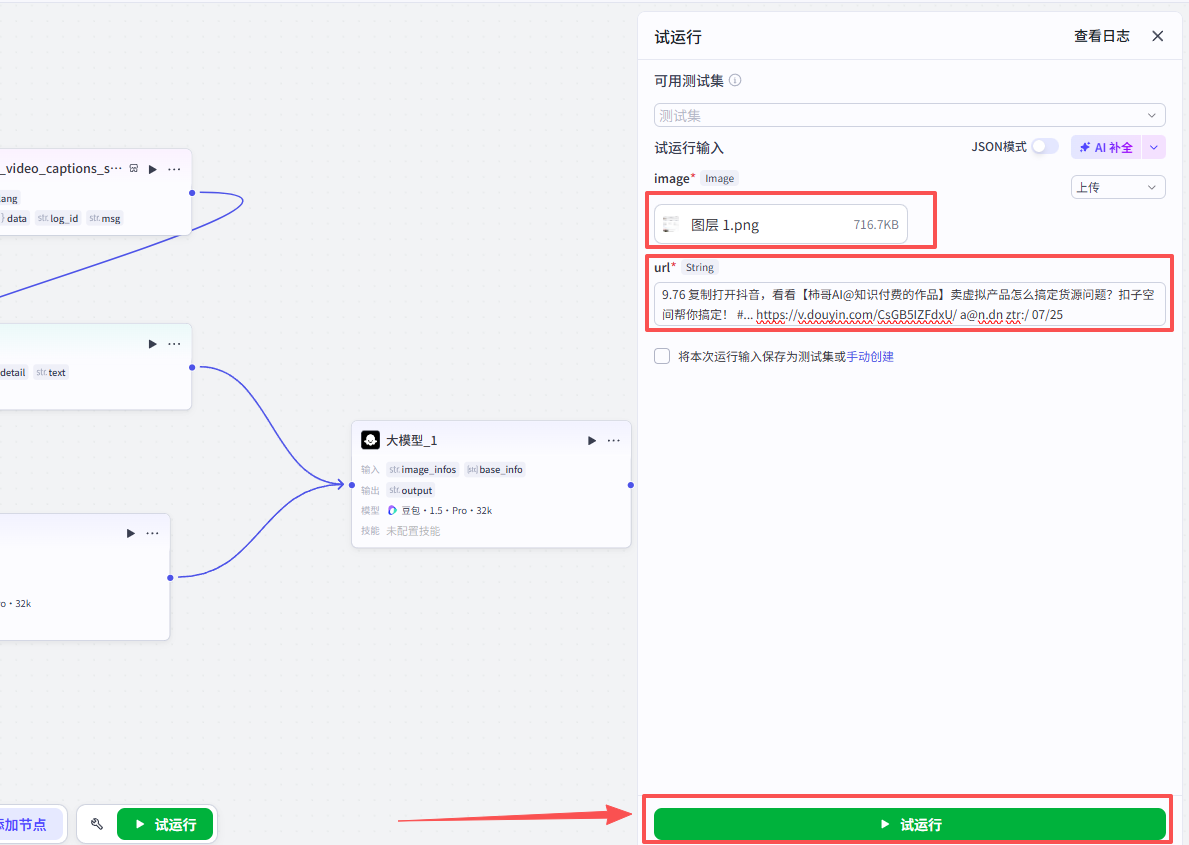
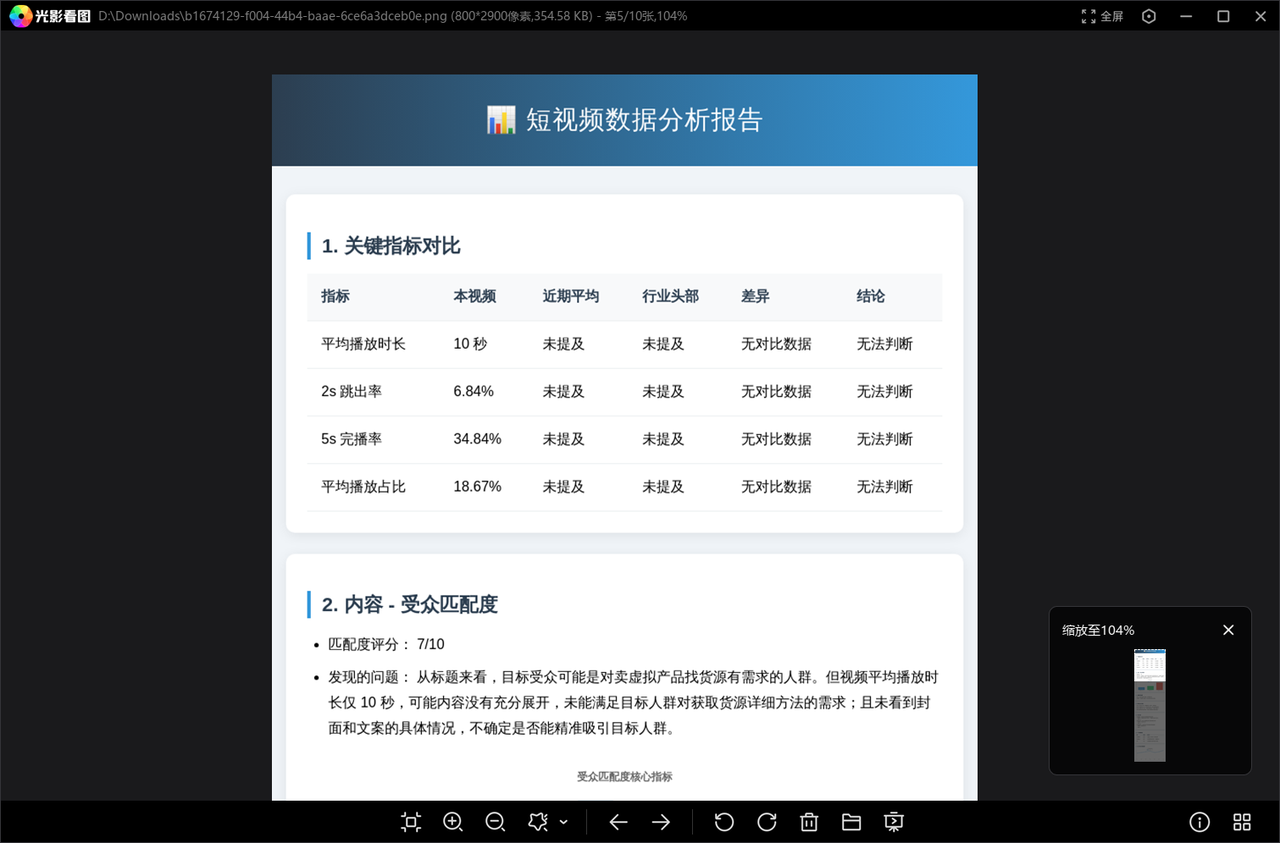
可以看到运行成功,成功输出了网页和分析报告图像,我们点击链接再检查一下
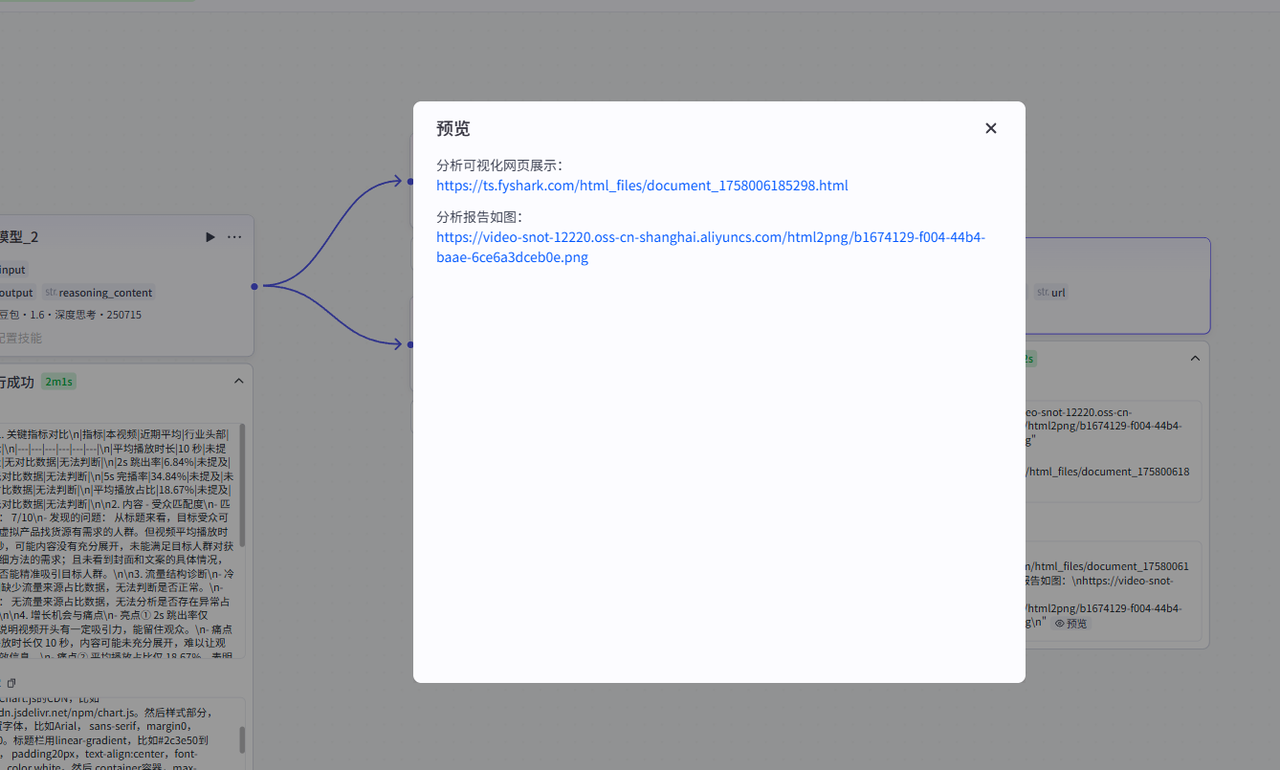
分析报告网页展示正常:
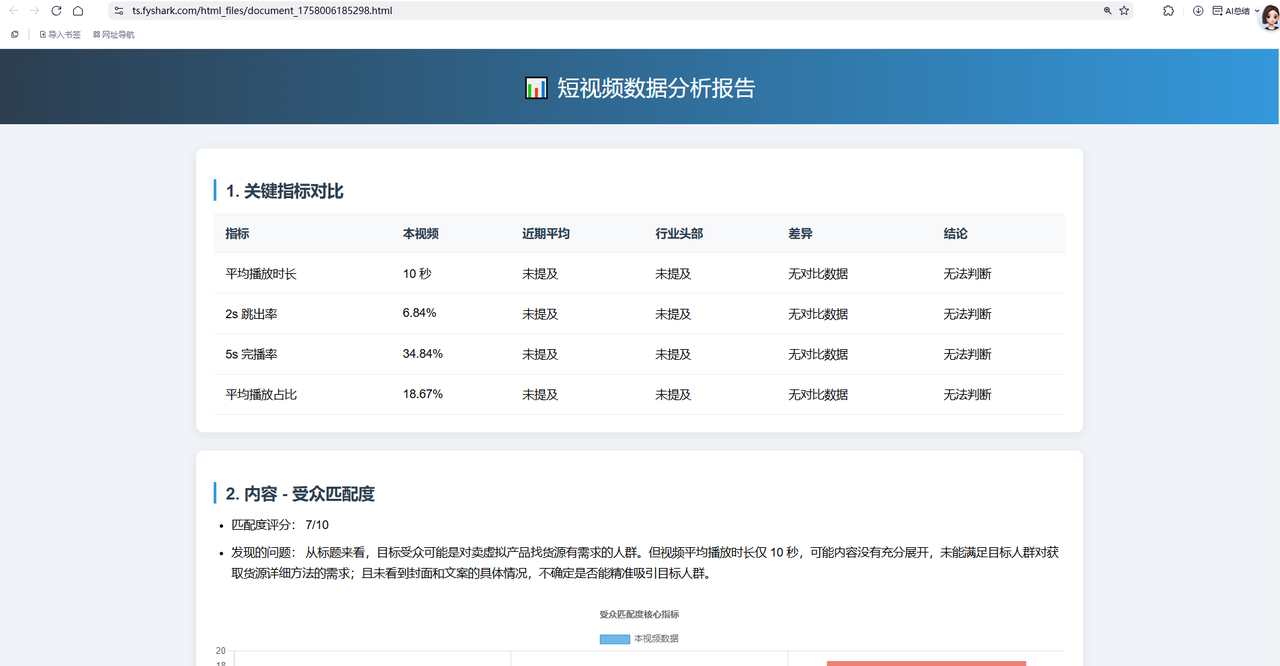
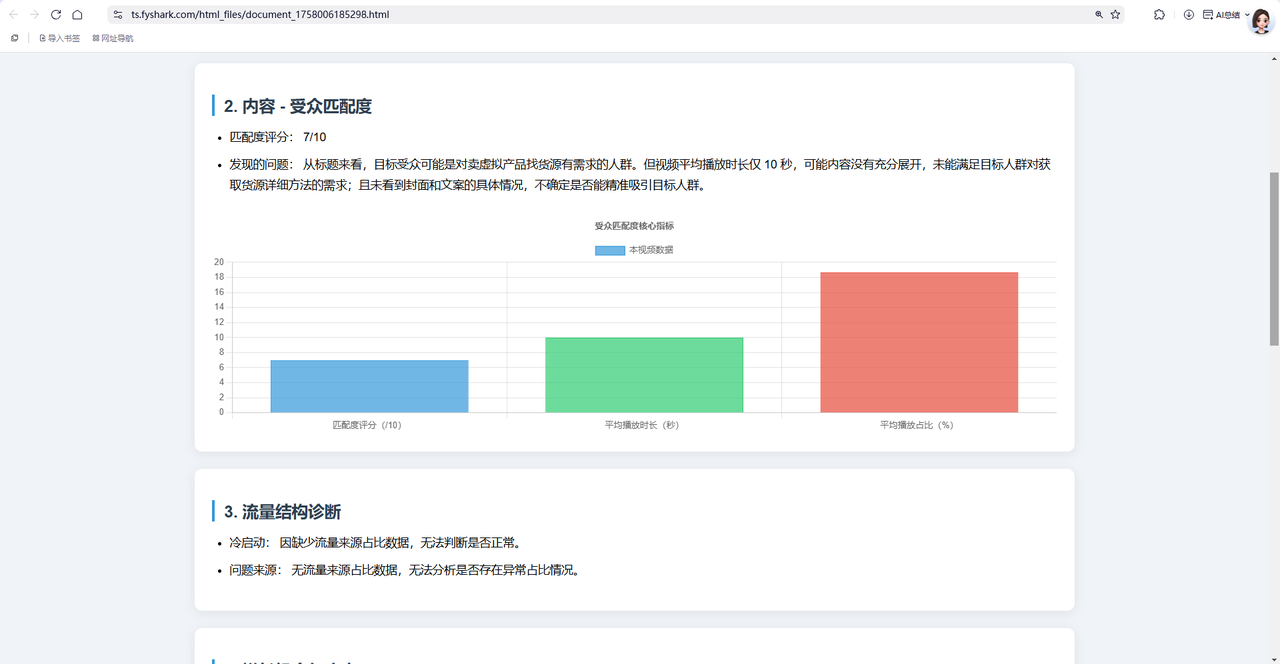
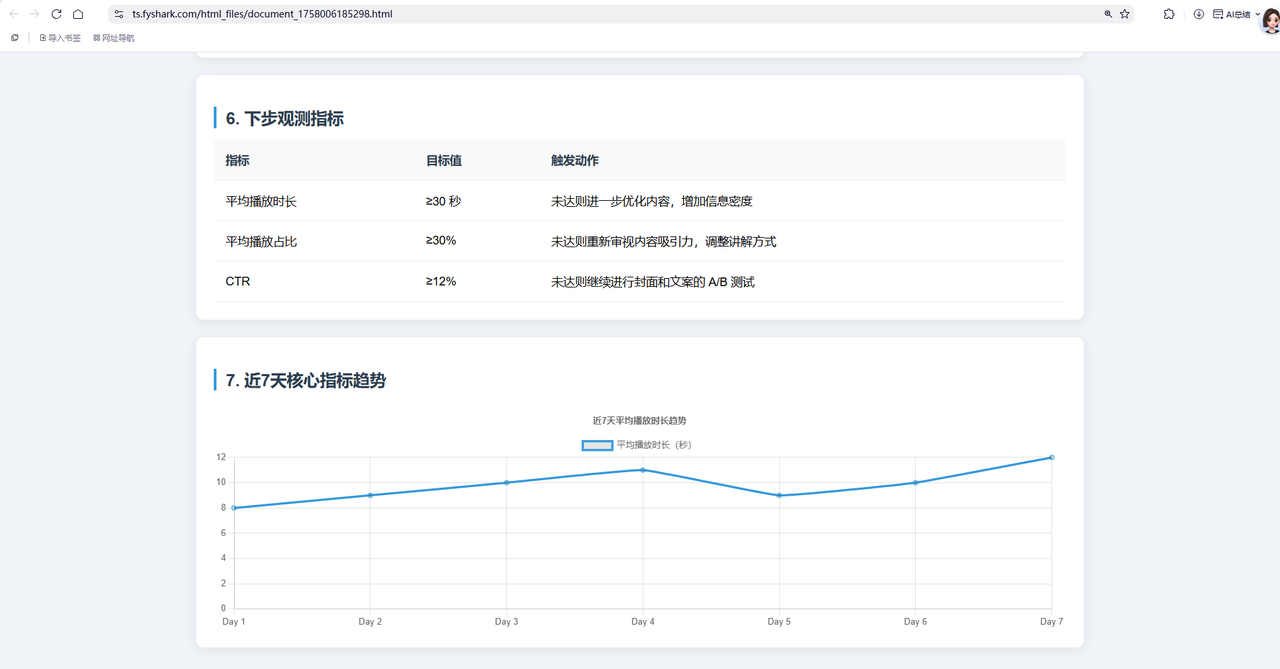
点击报告图像链接后,会直接下载分析报告:

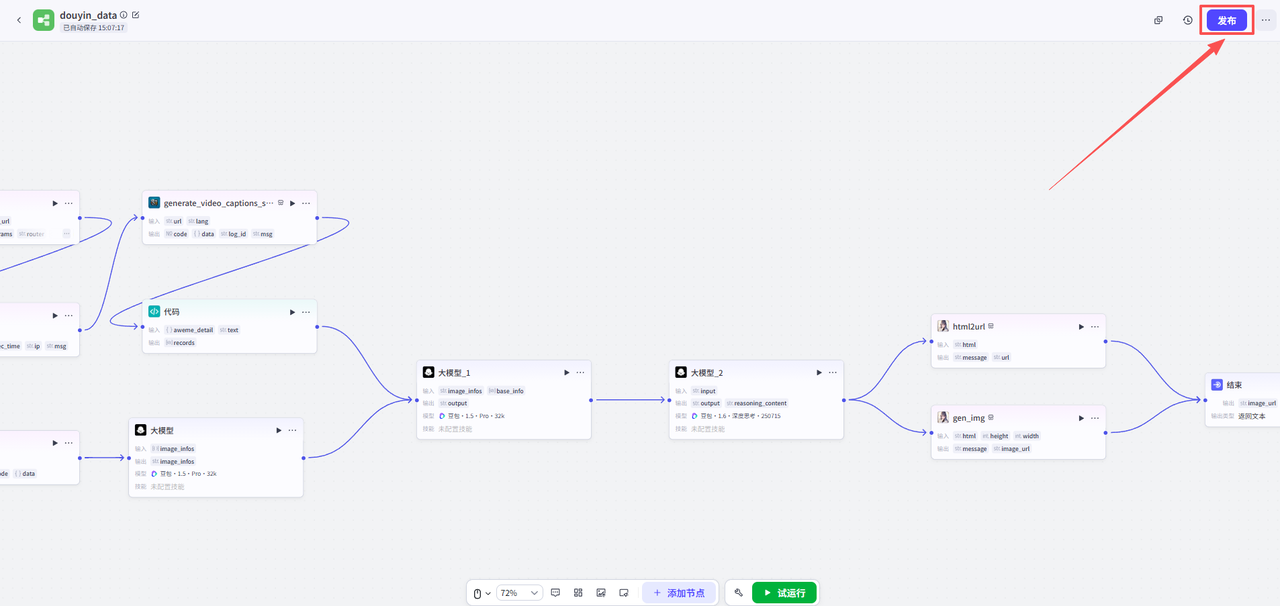
测试成功,点击右上角的发布
到这里,工作流的部分就全部完成了,接下来需要创建智能体,将工作流和智能体封装起来
🤖 创建智能体
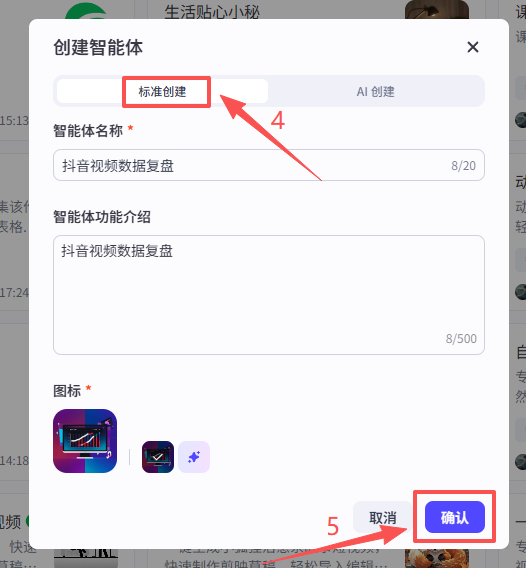
在个人空间创建一个新的智能体,命名“抖音视频数据复盘”
点击个人空间->项目开发->项目
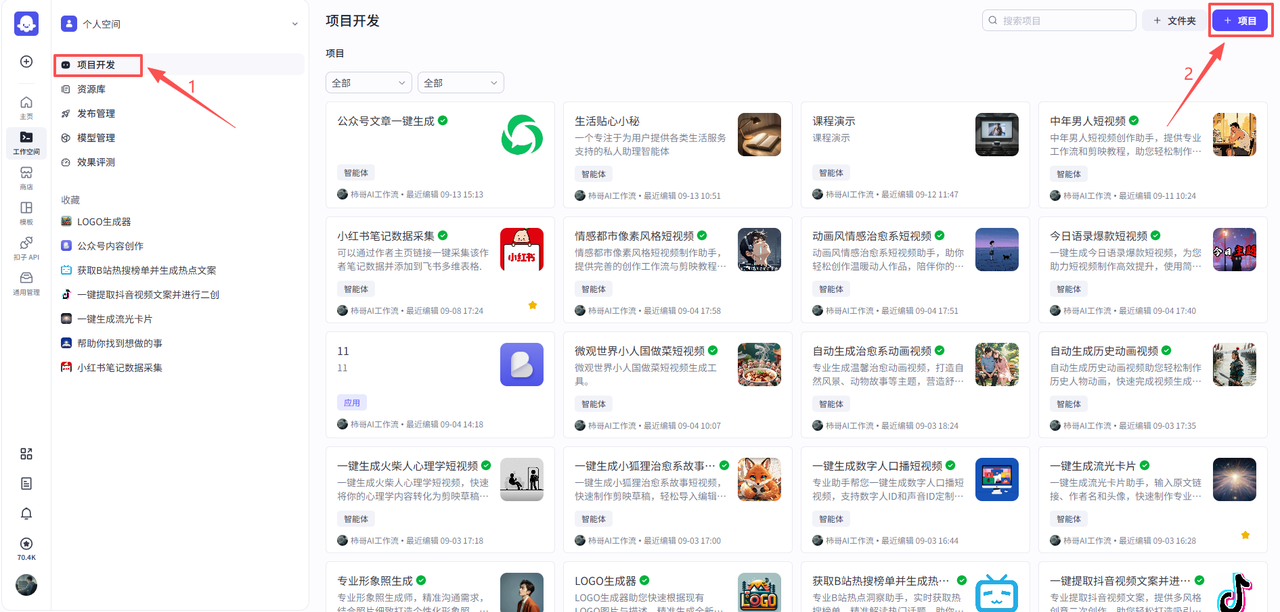
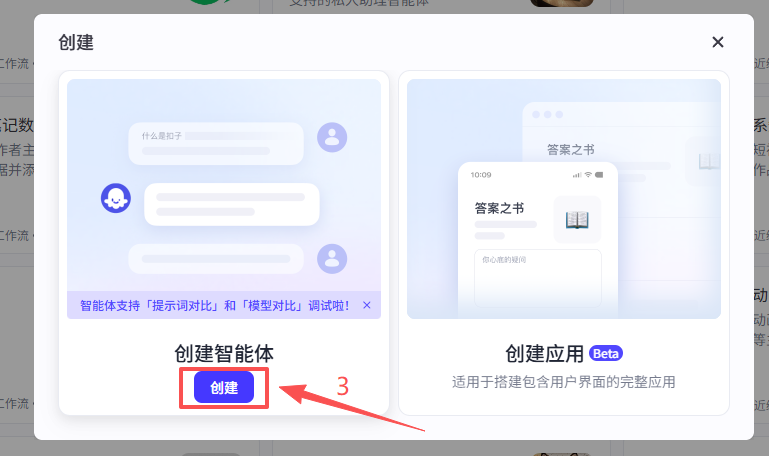
在弹窗中选择创建智能体,点击标准创建,然后输入名称和功能介绍,点击确认
创建快捷指令
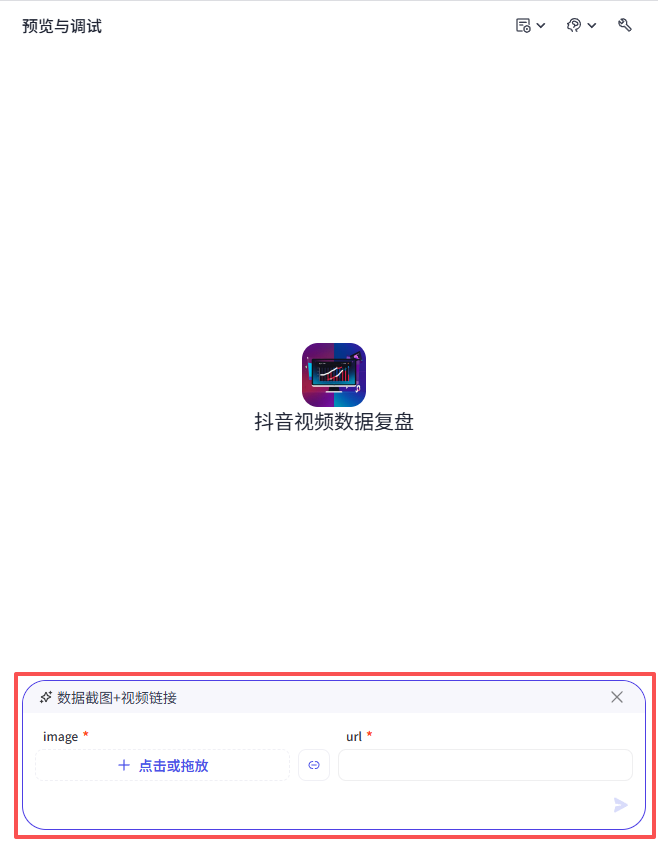
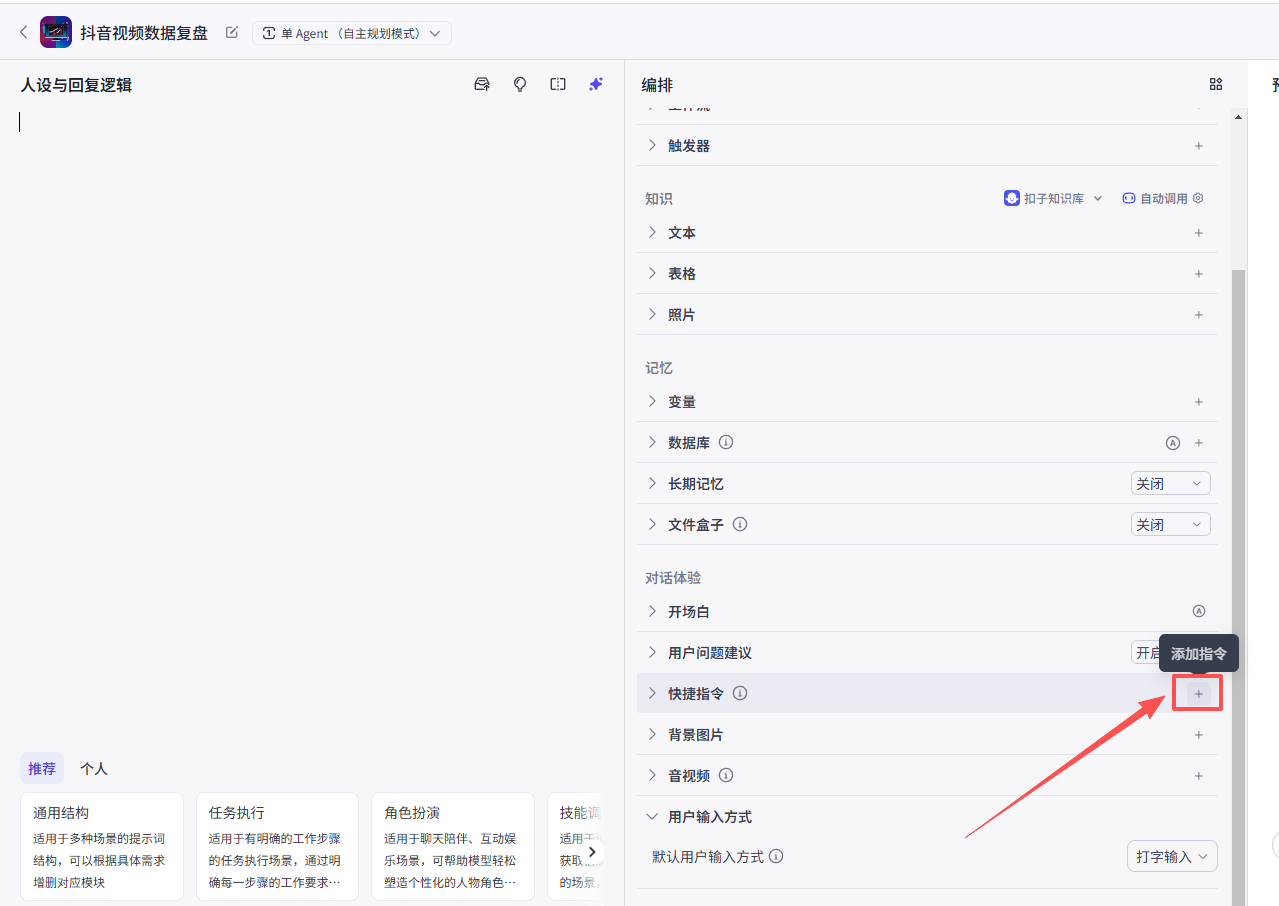
为了优化交互体验,我们创建一个快捷指令
在编排部分,点击快捷指令后面的+按钮
输入按钮名称和指令名称
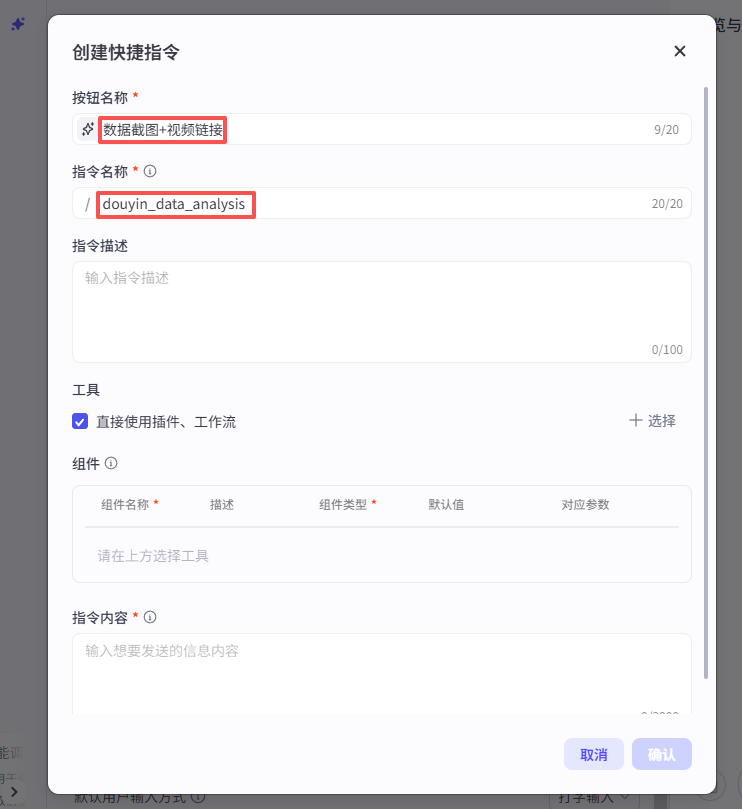
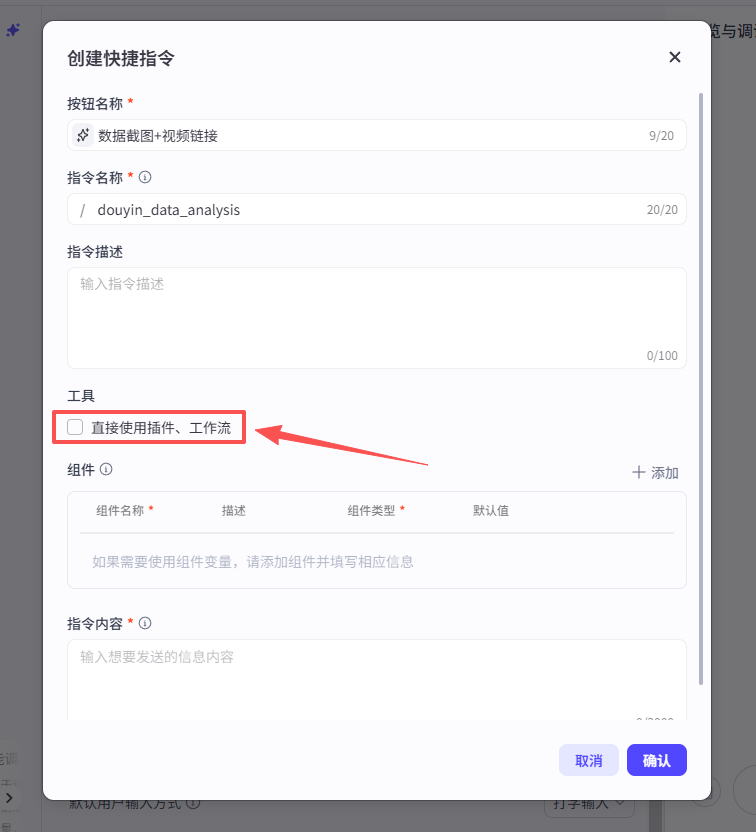
然后勾选工具部分的选项:直接使用插件、工作流
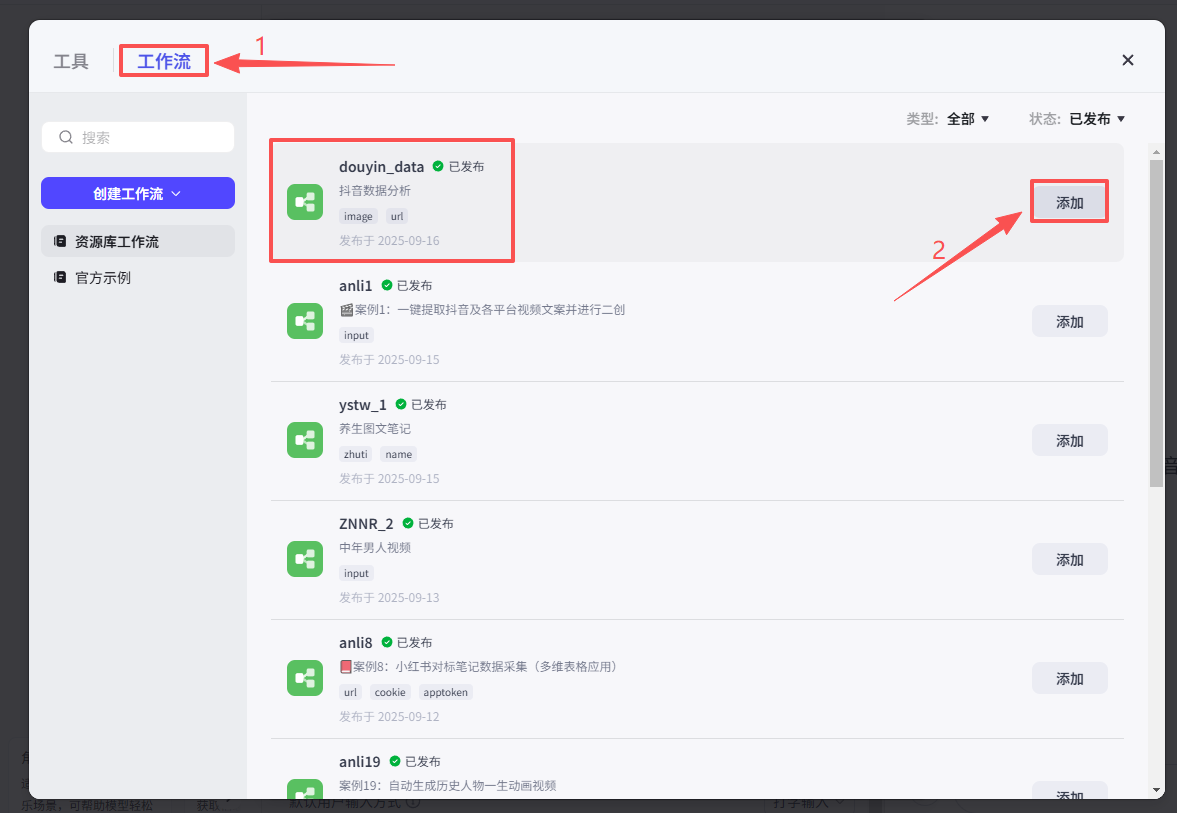
在弹窗中选择工作流,然后看到我们刚刚发布的抖音数据分析工作流,点击添加
添加成功之后,组件部分会自动填好,但是默认变量为文本,所以需要更改一下image的组件类型为上传文本-图片
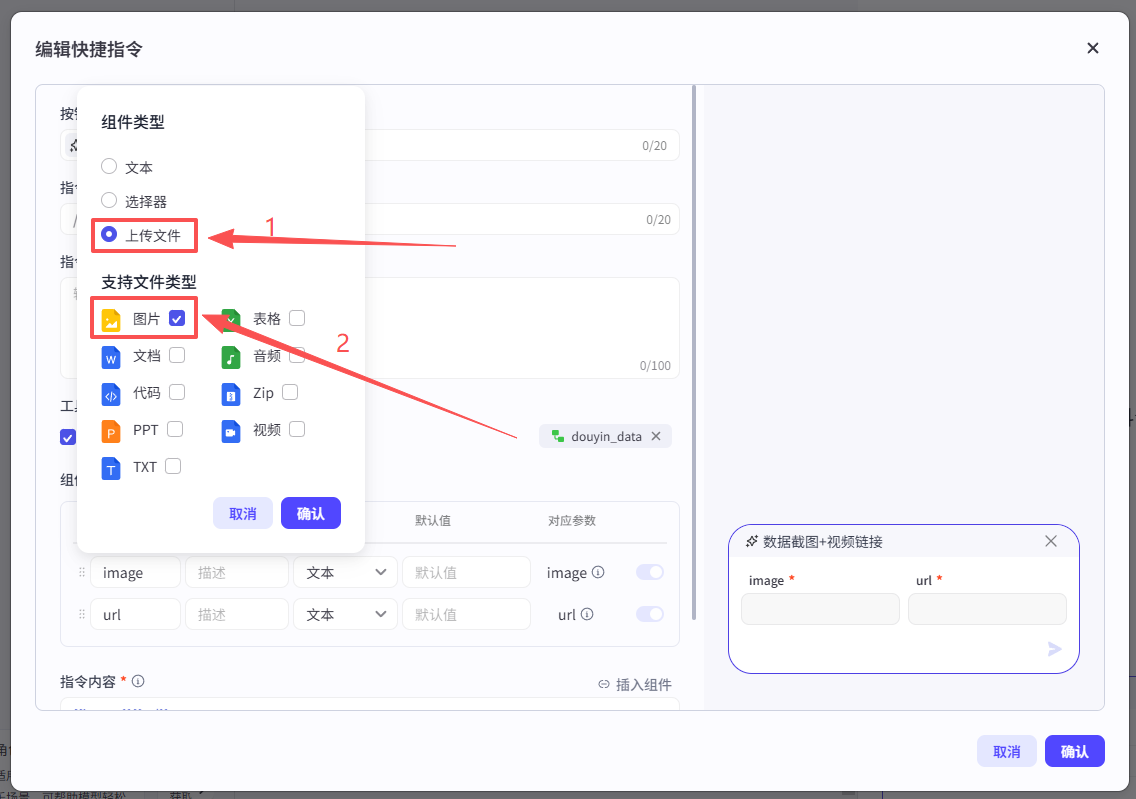
然后在指令内容部分再添加上变量名称,点击确认
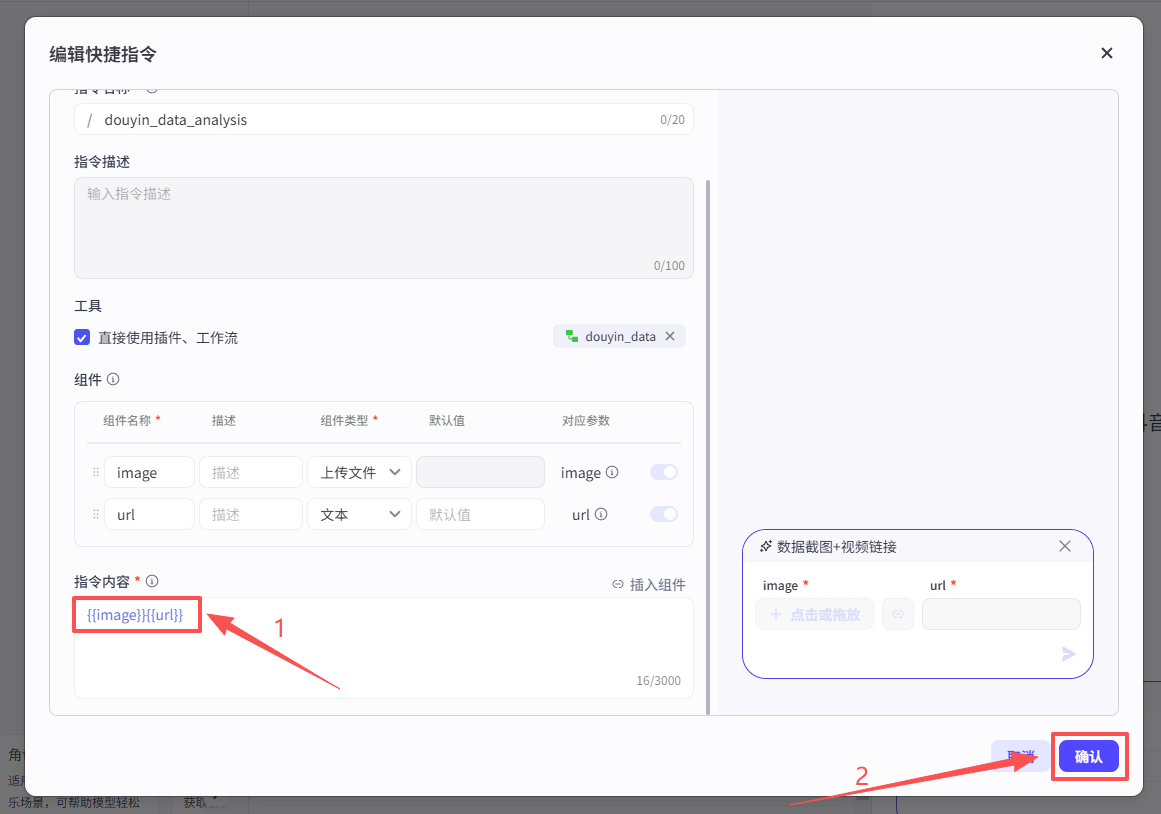
快捷指令创建好之后就是这样,用户点击之后,就会出现上传和输入的窗口