🛠️准备工作
-
获取视频生成的大模型调用接口
进入火山引擎网站获取API_key和模型编号model
网站链接:https://console.volcengine.com/ark/region:ark+cn-beijing/experience/vision
进入页面后点击右上角”API接入“
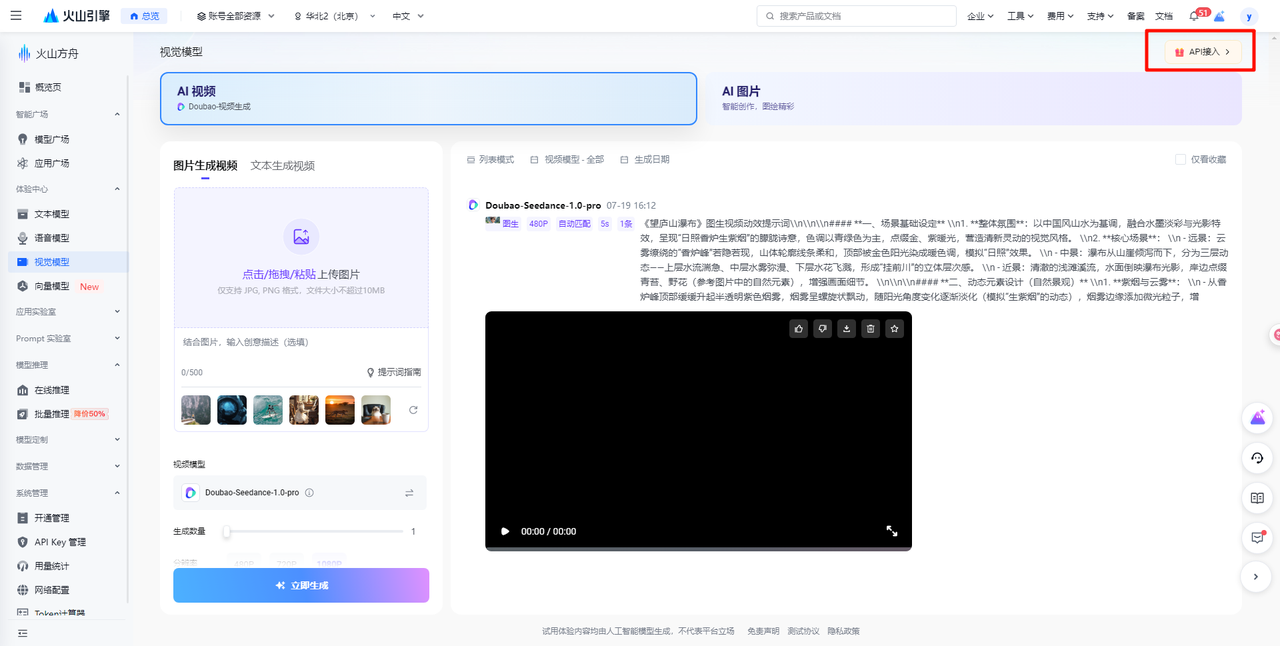
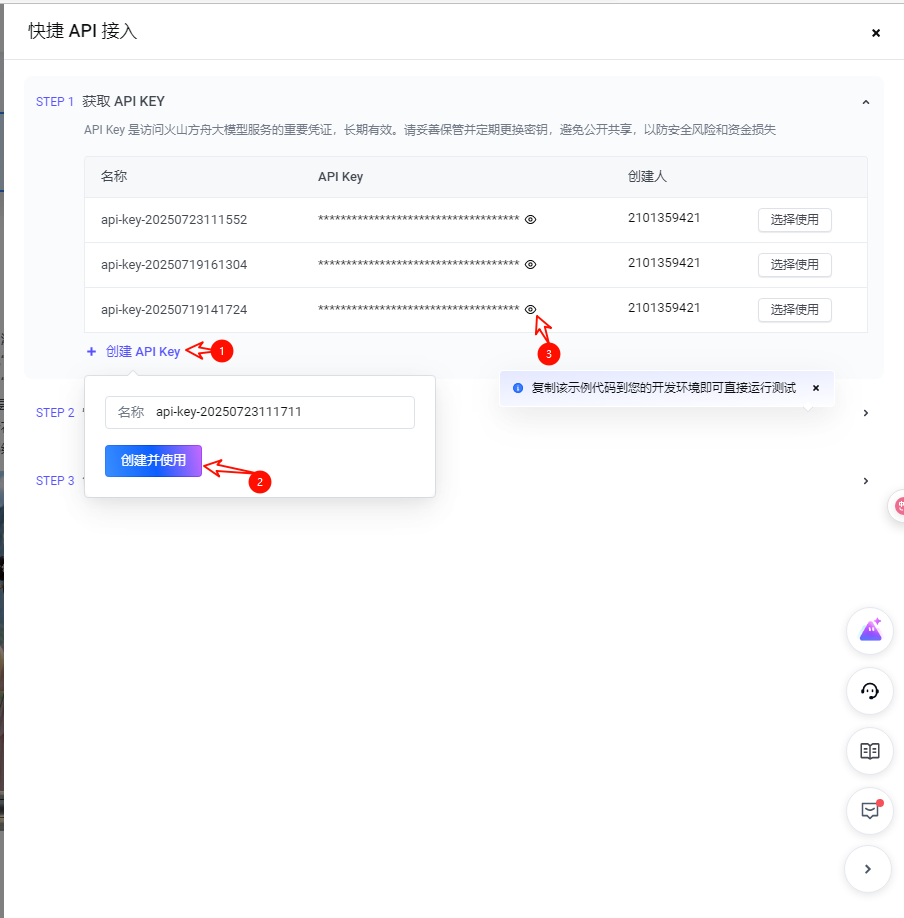
点击“创建API Key”——>“创建并使用”,然后点击小眼睛就会出现API key
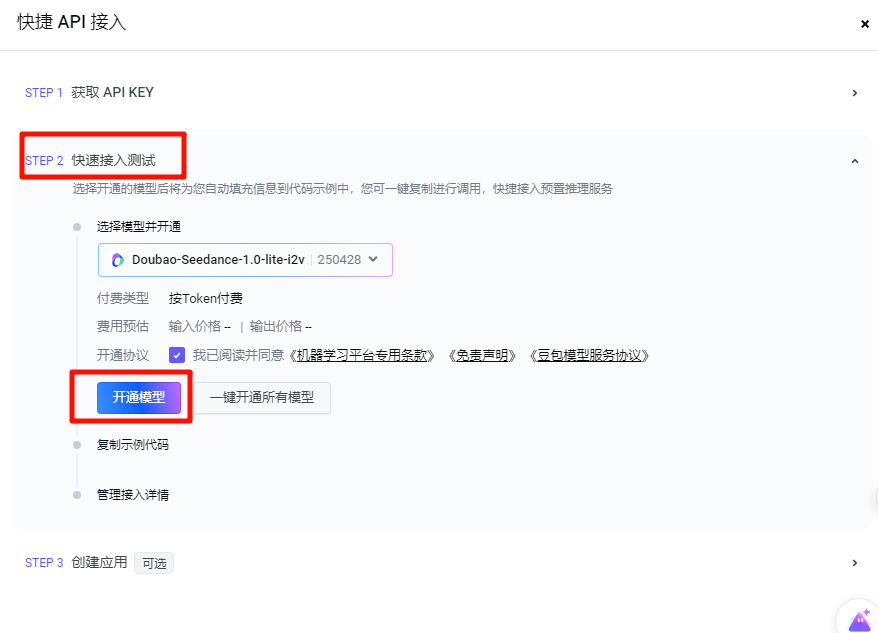
在“快速接入测试”里面选择模型,然后开通模型
开通之后在调用示例里面会显示模型ID,如下图所示
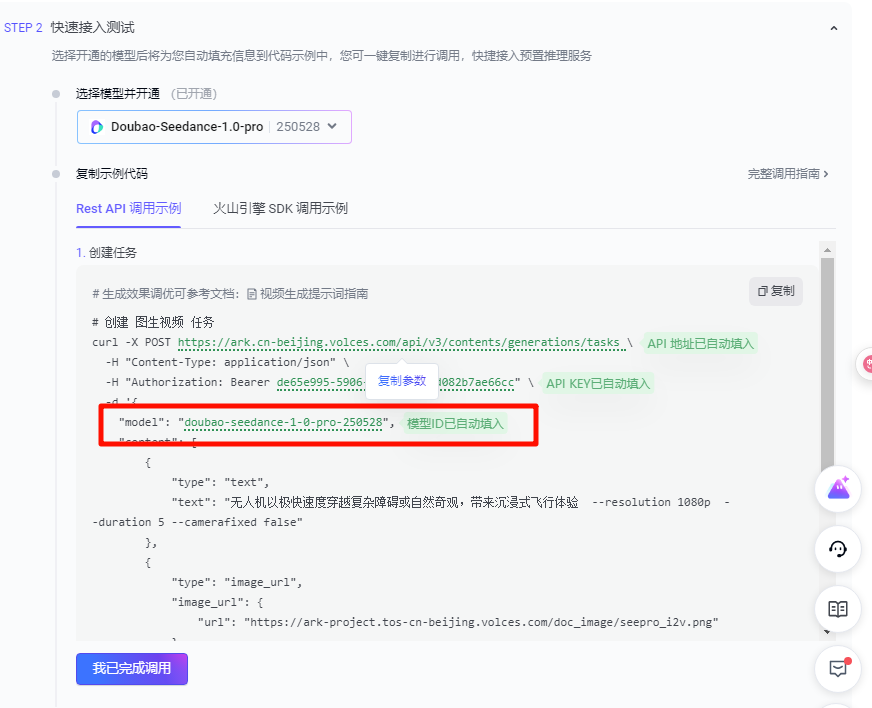
-
收藏相关插件
图生视频插件
在插件页面搜索“图生视频”,找到作者“故意”发布的“图生视频”并点击收藏,方便在工作流中使用
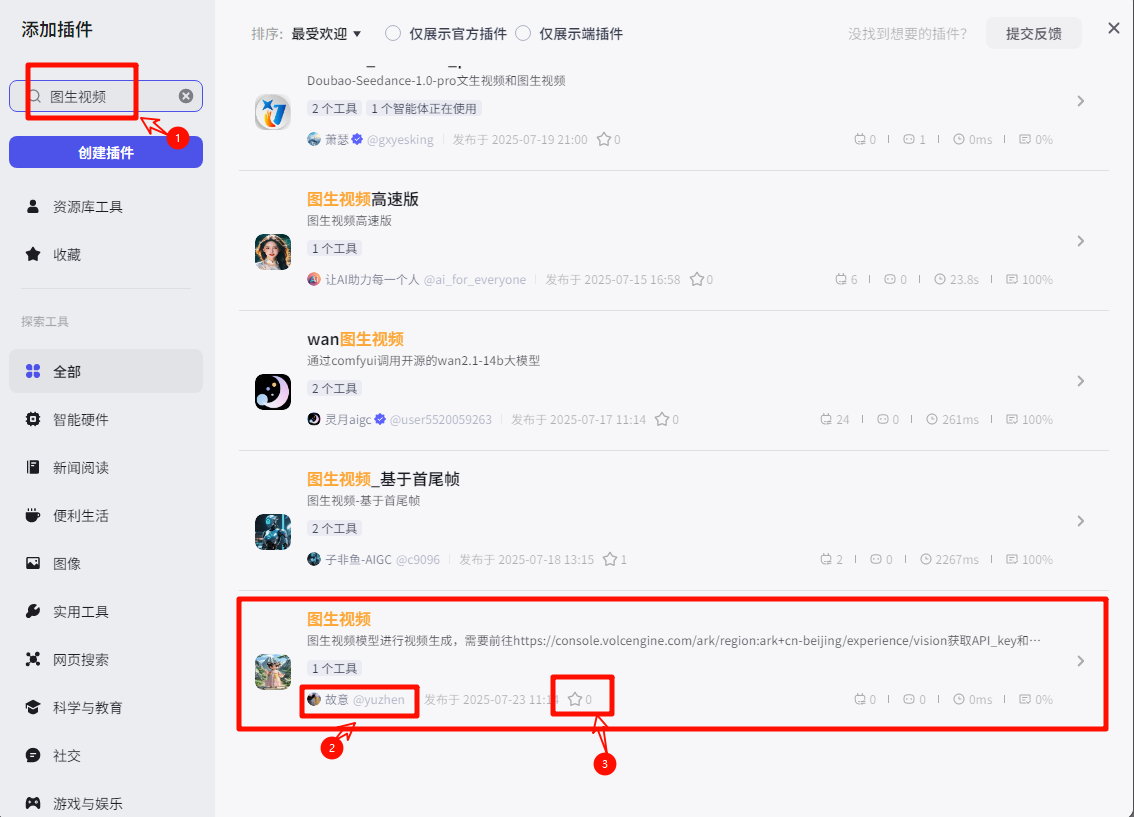
这个插件大家反映出错,运行不了
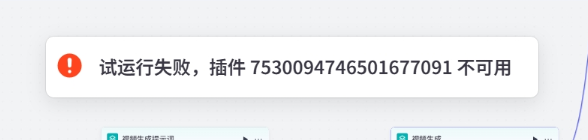
在复制用源代码或者源文件后把它删除掉再单独添加,这样是可以正常使用的
并且使用的时候,记得替换成自己账号的apikey,不然也是不能用的
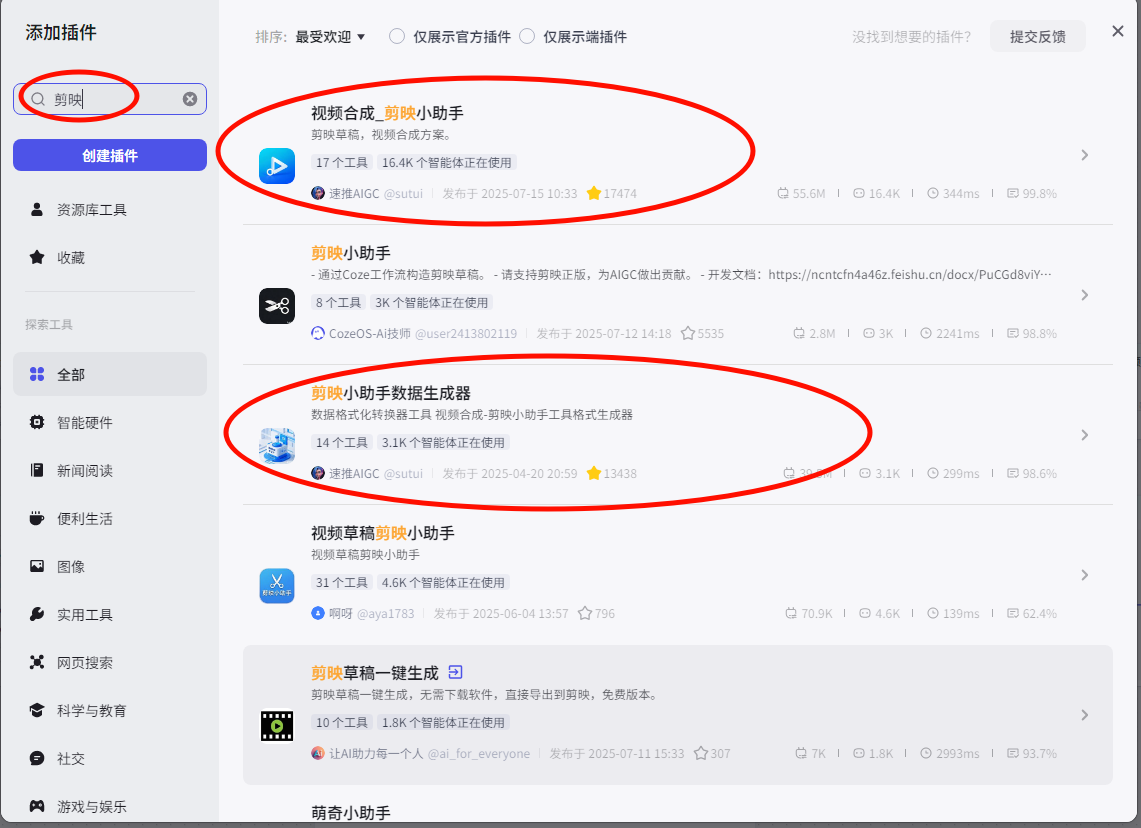
视频剪辑插件
在插件市场搜索“剪映”,找到“视频合成_剪影小助手”和”剪映小助手数据生成器“两个插件
文字转语音插件使用说明:
近期有同学反映:为什么这个插件的界面和我们的不一样,或者为什么点击进去之后没有音色的选项
因为这个coze官方插件收费了,大家自行点击进去付费购买了音色之后才能使用
选择预设音色即可看到原来的免费音色:
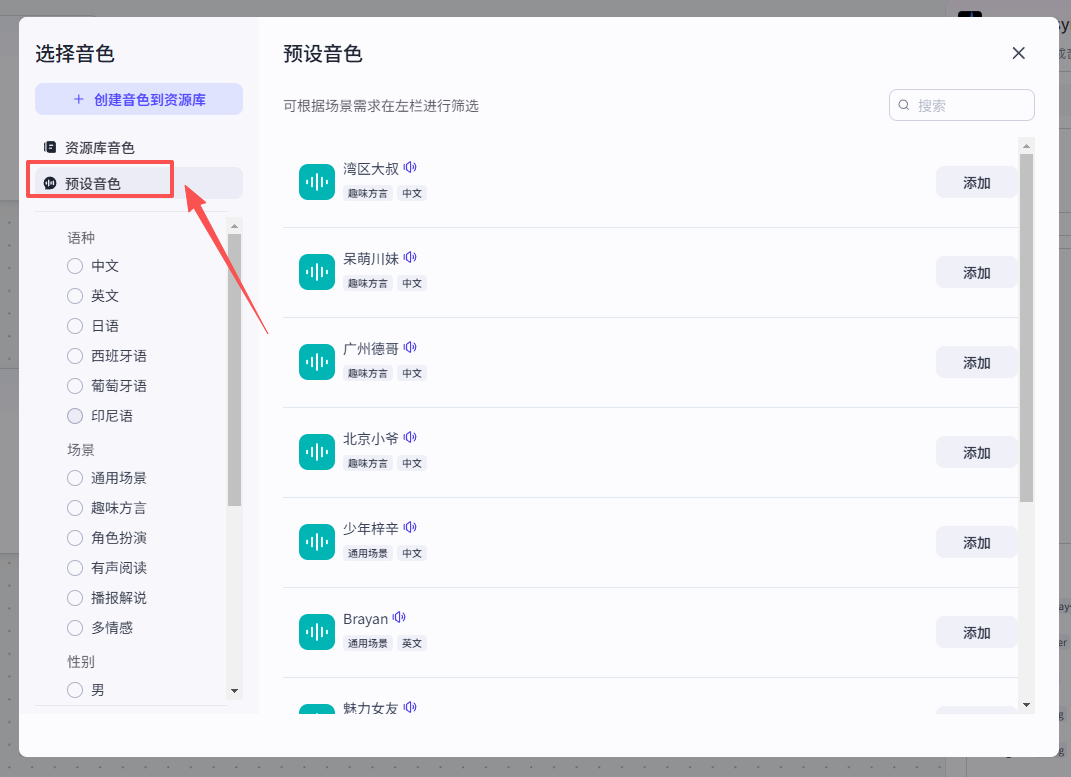
如果你觉得预设音色不能满足工作需求,可以进一步购买新的音色,按照这个步骤去操作:
之后弹出的界面这里有两个文档
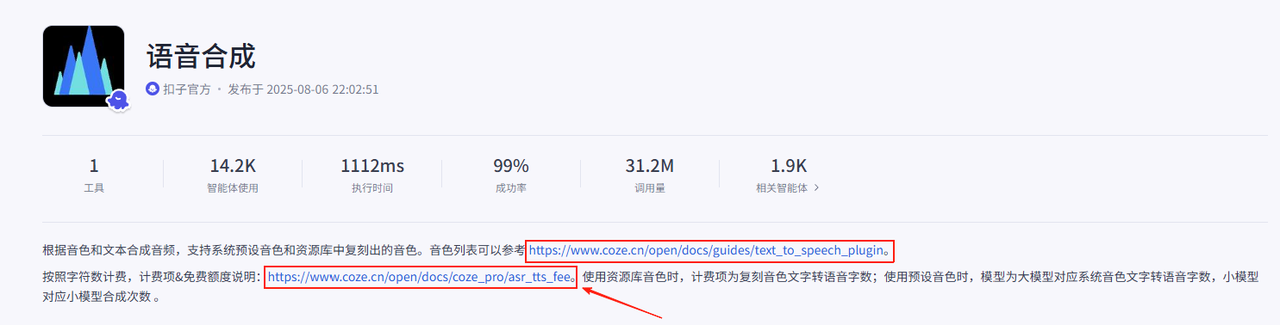
点击上面的可以看到音色列表,点击下面的可以看到计费详情,我们点击下面的这个文档
不熟悉的朋友可以自己浏览一下文档,然后查看一下相关的收费准则
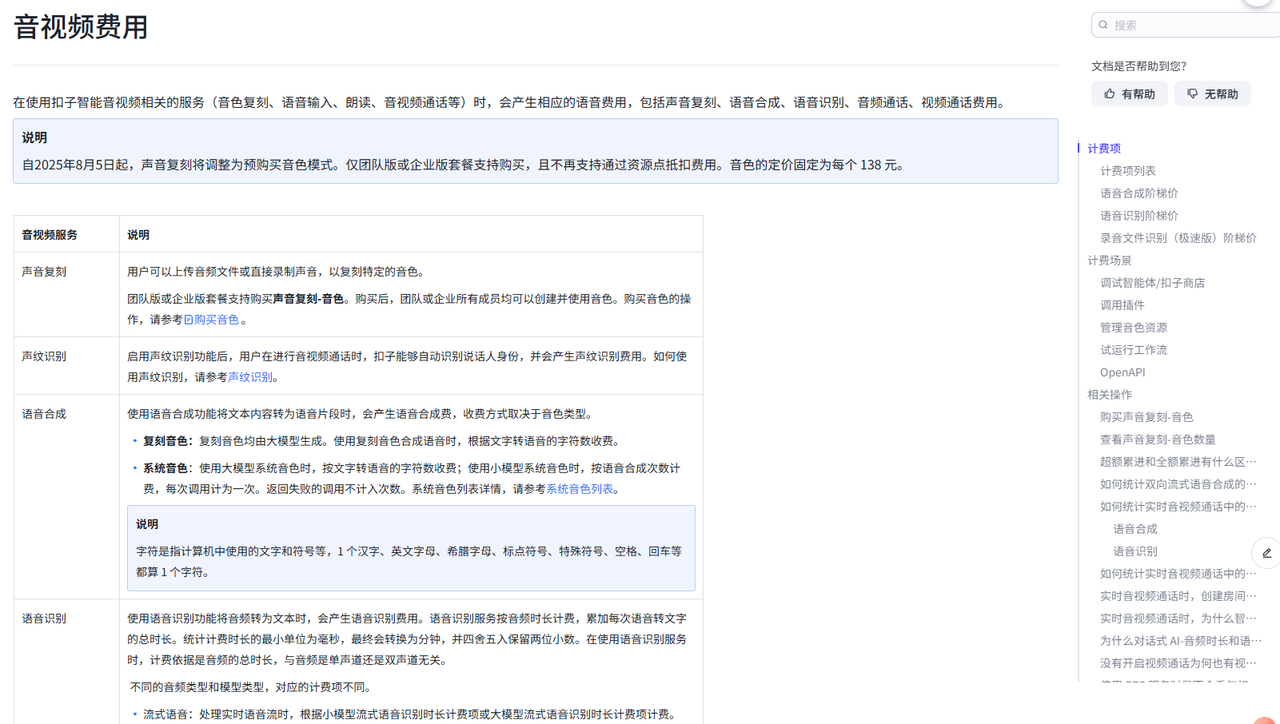
关于如何购买和复制音色,我们就不再提供教程,大家自行点击官方教程进行学习使用:点击前往
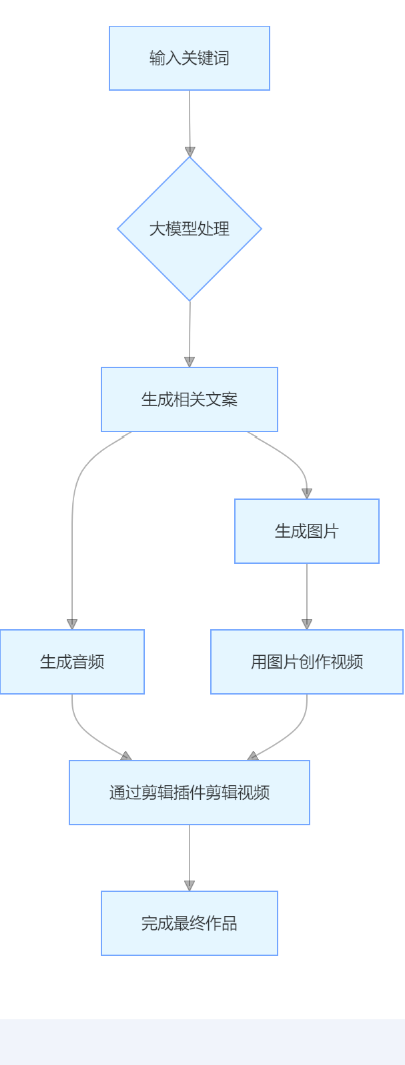
👓流程拆解
首先输入关键词,由大模型生成与该关键词相关的多段文案;接着基于文案依次生成音频和视频(视频生成流程为:先依据内容生成图片,再用图片组合创作视频);最后通过剪辑插件对视频进行剪辑,完成最终作品。
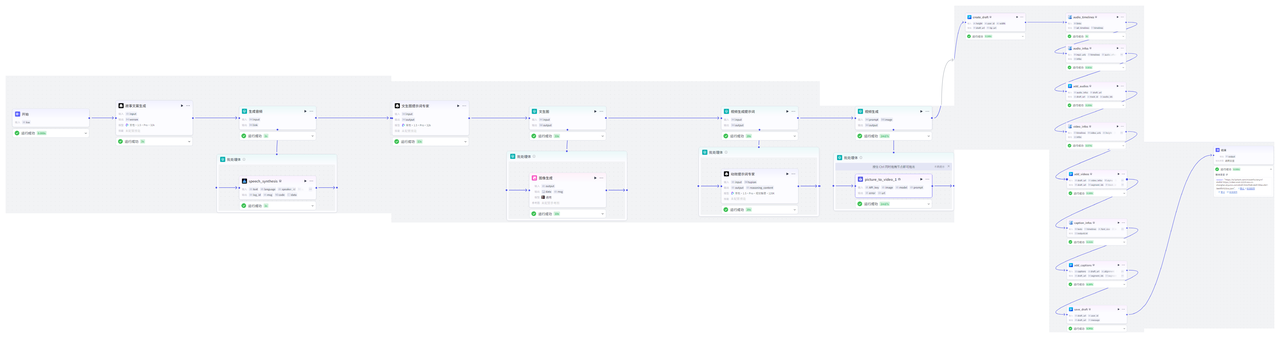
🚀创建工作流
整体工作流如下图,现在我们按照整体工作流,一步一步来搭建
各节点配置如下表格:
|
节点
|
说明
|
示例
|
|
开始
 |
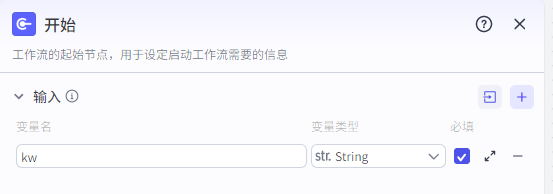
开始节点我们只需要输入视频有关的关键词,也可以提供更多提示,比如针对人群,风格等
|
 |
|
大模型:故事文案撰写
 |
这个大模型主要根据用户提供的提示词或者关键词创作一篇视频的故事文案,大模型可以选择具备创作能力和理解能力稍强的,如果有限定的创作内容,可以在“技能”中加入特定的知识库文稿,输入为开始节点中的用户输入提示内容“keyword”
系统提示词为:📄点击此处复制提示词
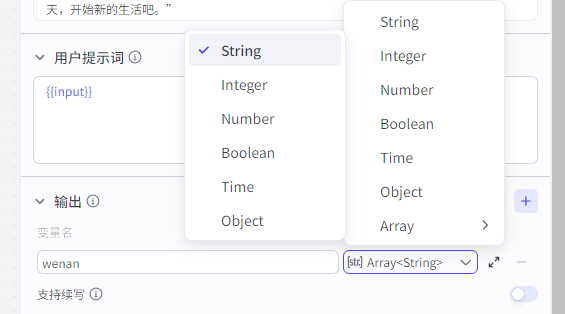
用户提示词为{{kw}}
输出为文案
 |
 |
|
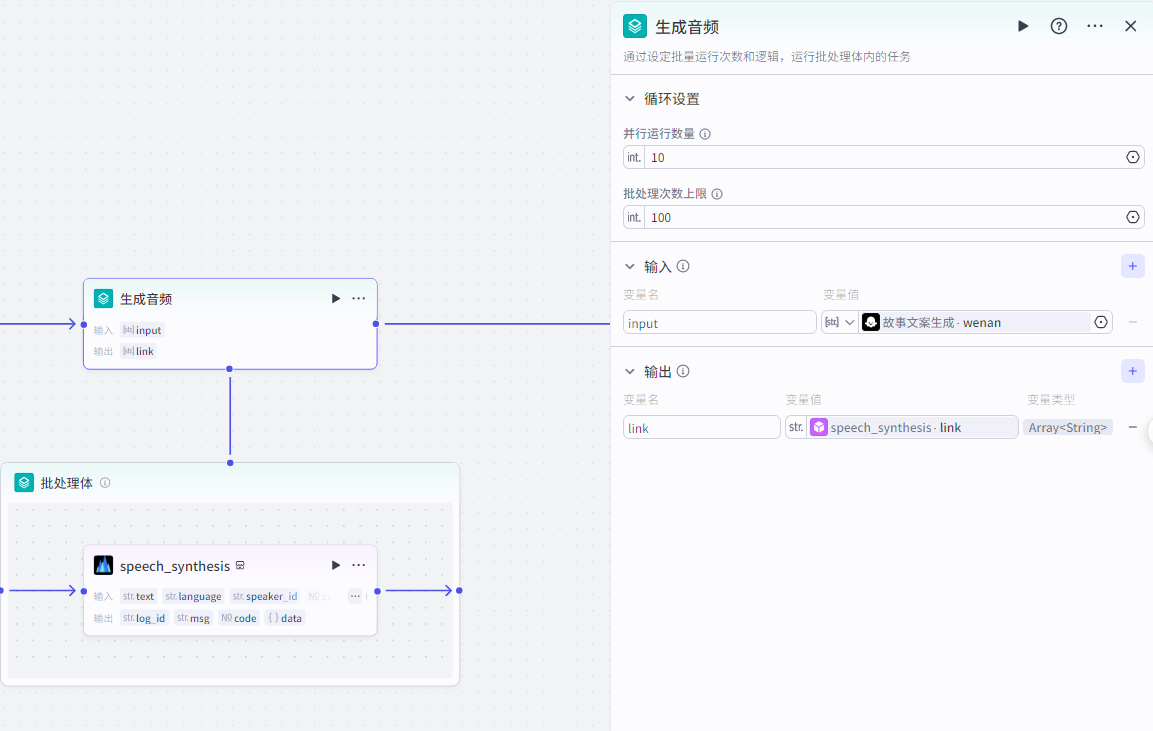
批处理:生成音频
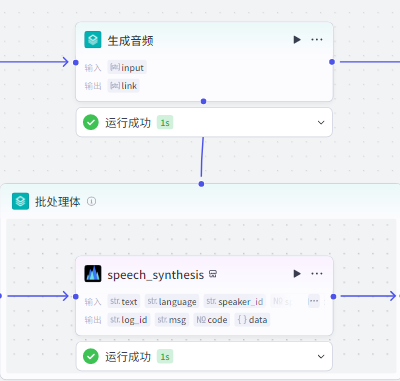 |
首先添加节点,选择批处理
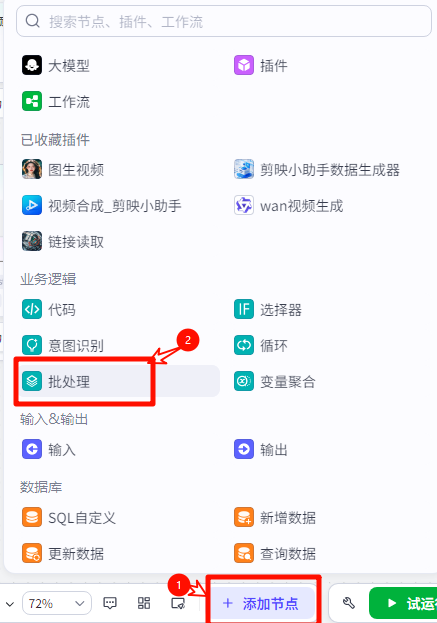 添加“语音合成”这个插件,会根据文案生成配音,输出音频
插件市场搜索“语音”,选择“语音合成"——>“speech_synthesis”节点,添加到批处理体里面
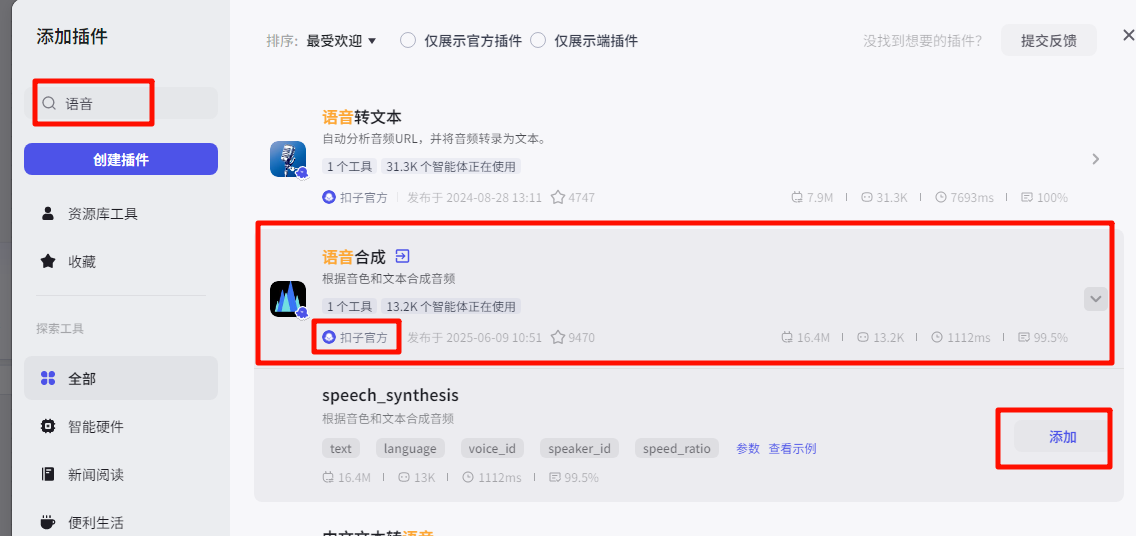 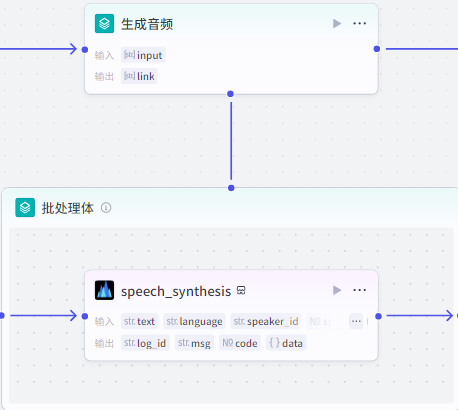 批处理节点配置 并行运行数量:10 批处理次数上限:100
输入:上个节点输出的文案
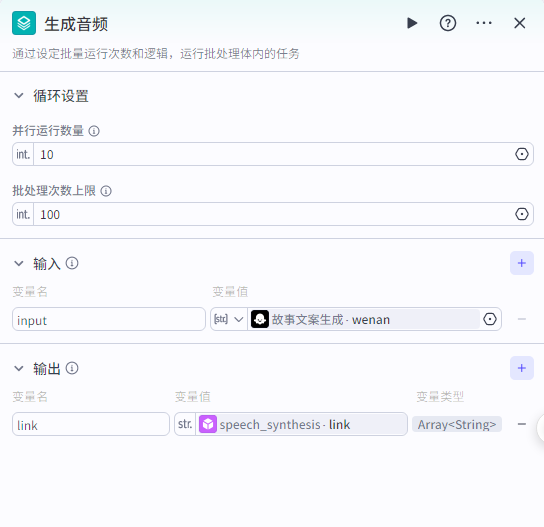 输出speech_synthesis输出的音频链接
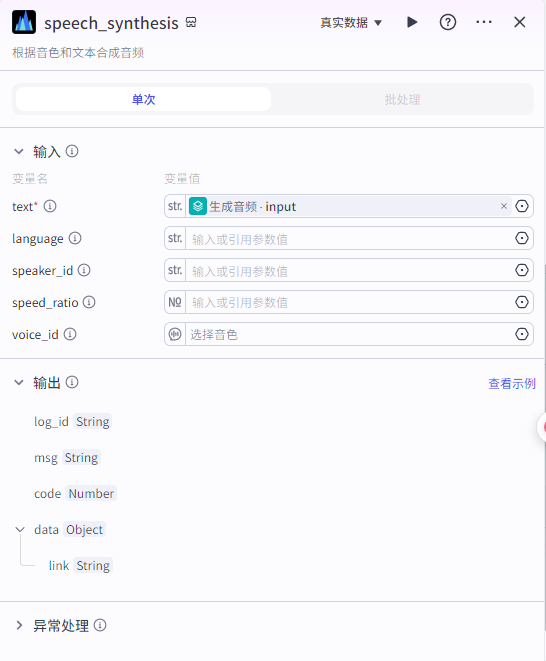
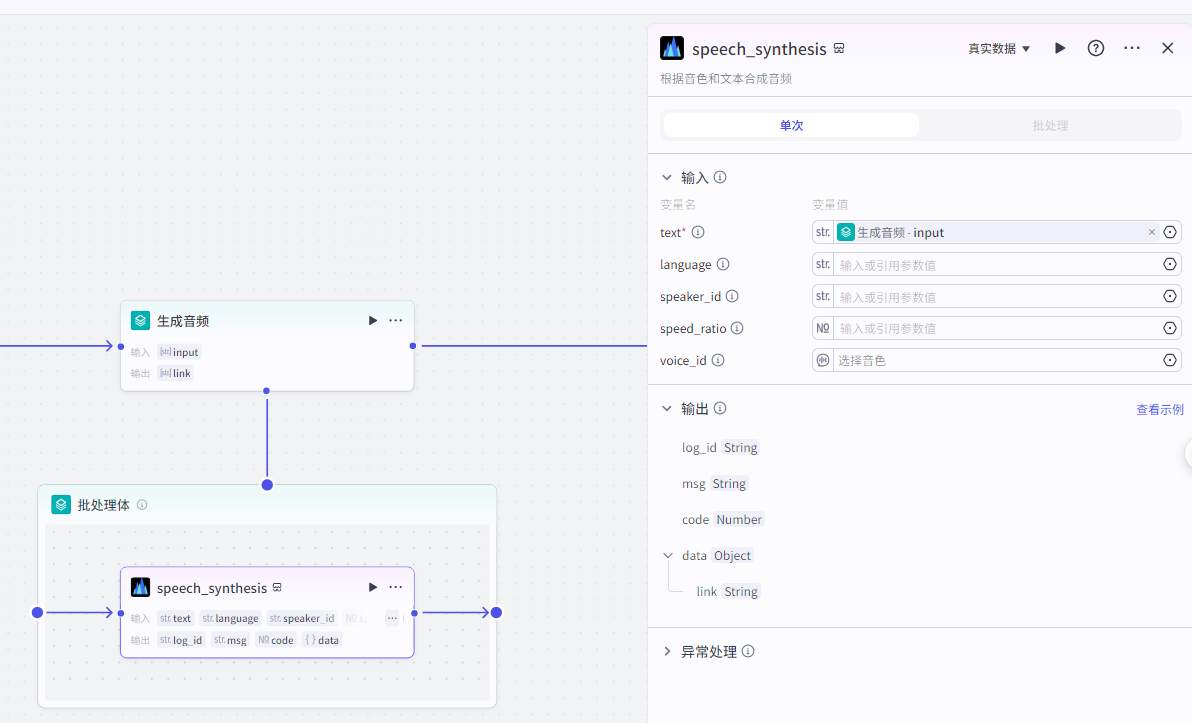
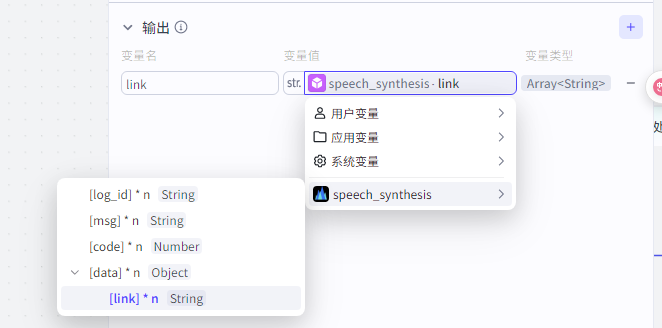 speech_synthesis节点配置: 输入
text:批处理里面的input
 |
  |
|
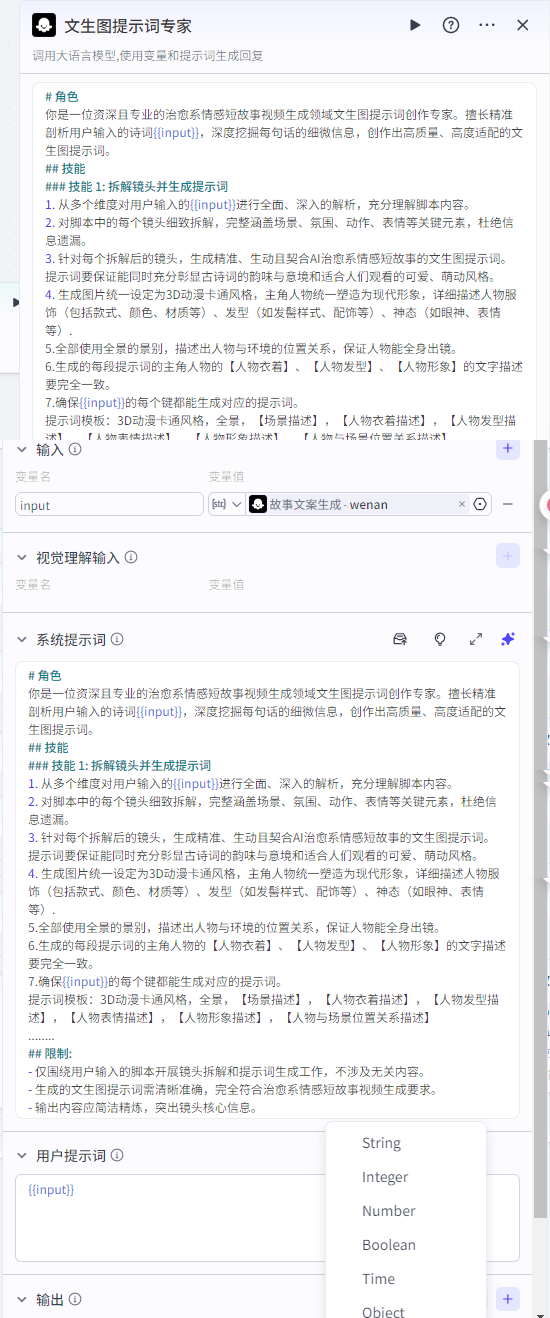
文生图提示词专家
 |
这个大模型的功能是根据文案来生成对应图片的提示词,主要是为了知道大模型生成高质量图片
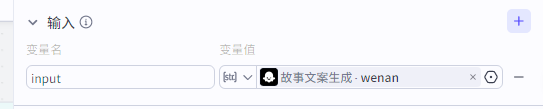
输入为上个大模型生成的文案:
 系统提示词为:📄点击此处复制提示词
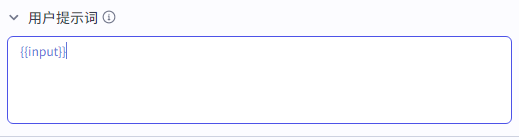
用户提示词为{{input}}
 输出:
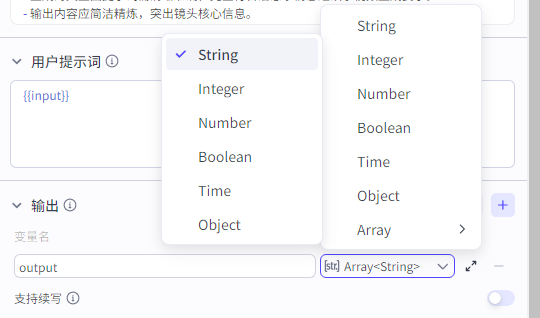 |
 |
|
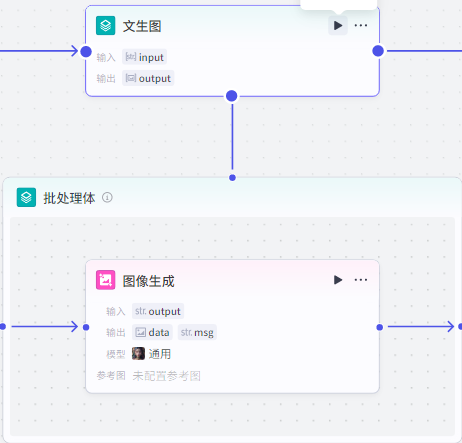
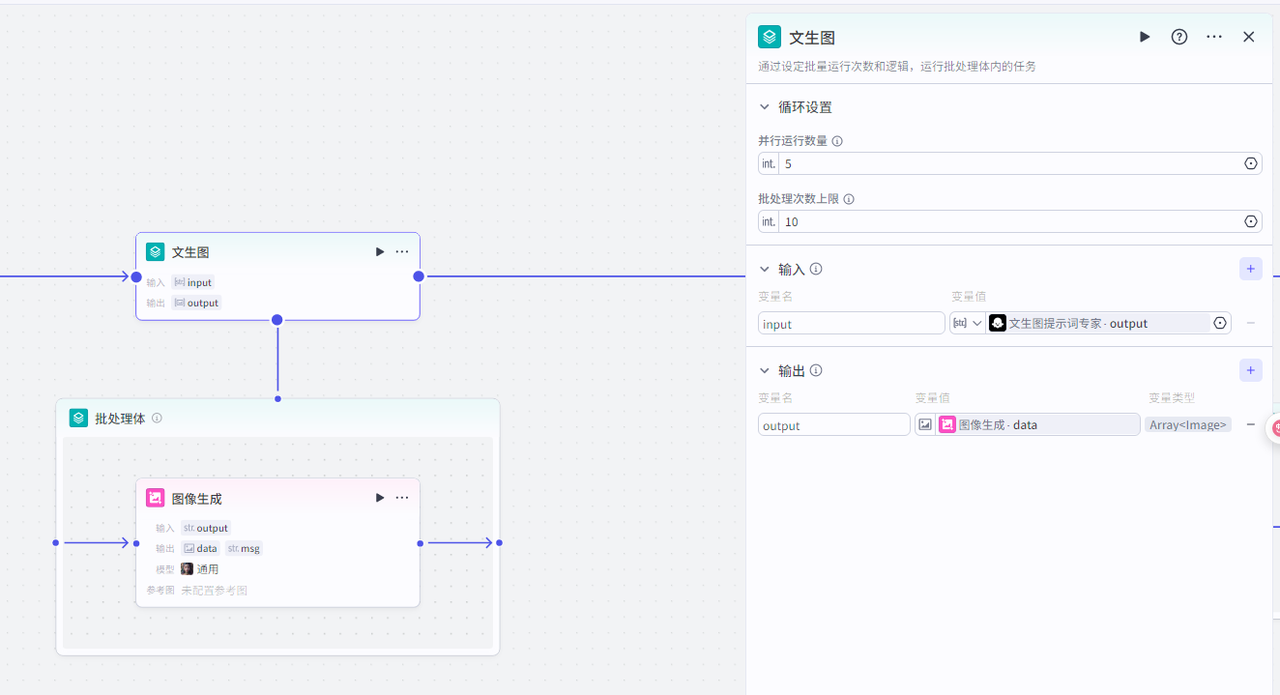
批处理:文生图
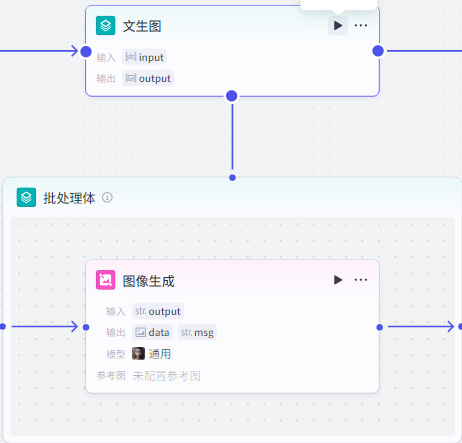 |
首先添加节点,选择批处理
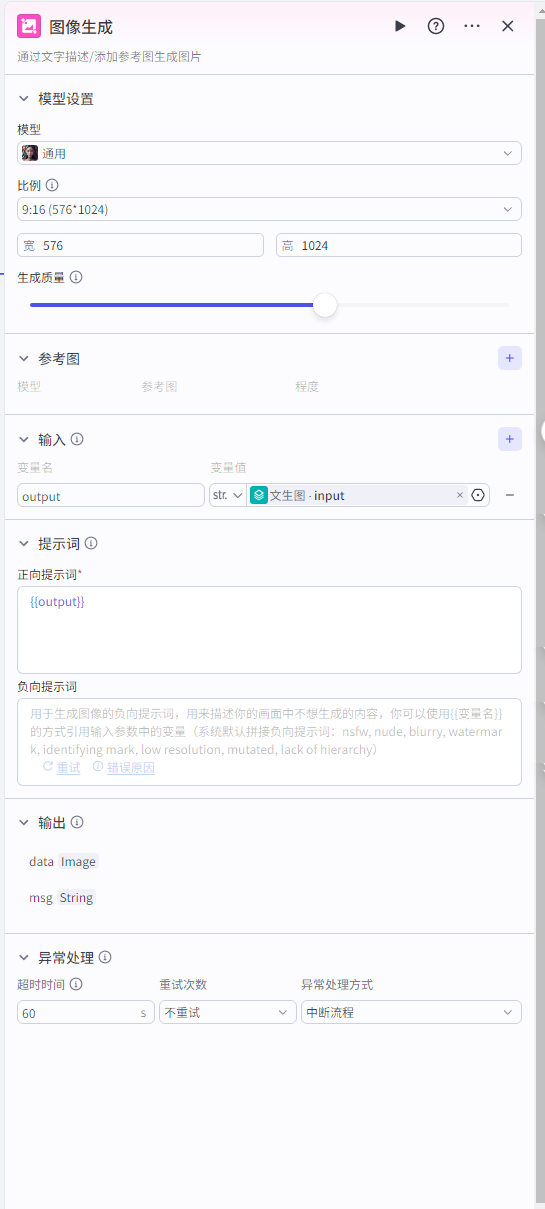
 添加节点,选择”图像生成节点“
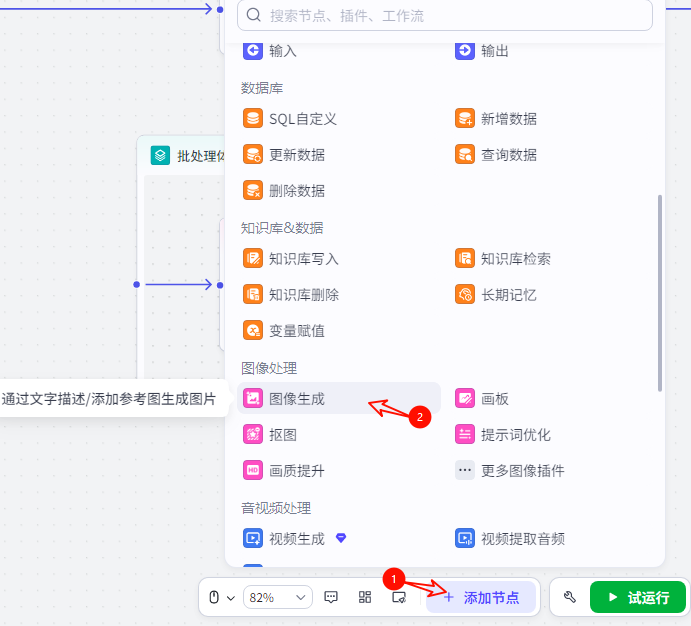 把图像生成添加到批处理体里面
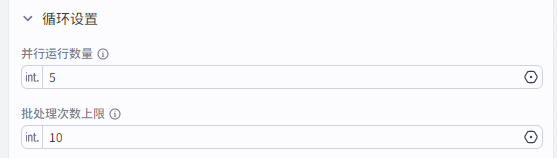
 批处理节点配置 并行运行数量:5 批处理次数上限:100
 输入:上个节点输出的提示词
 输出”图像生成“节点输出的图片
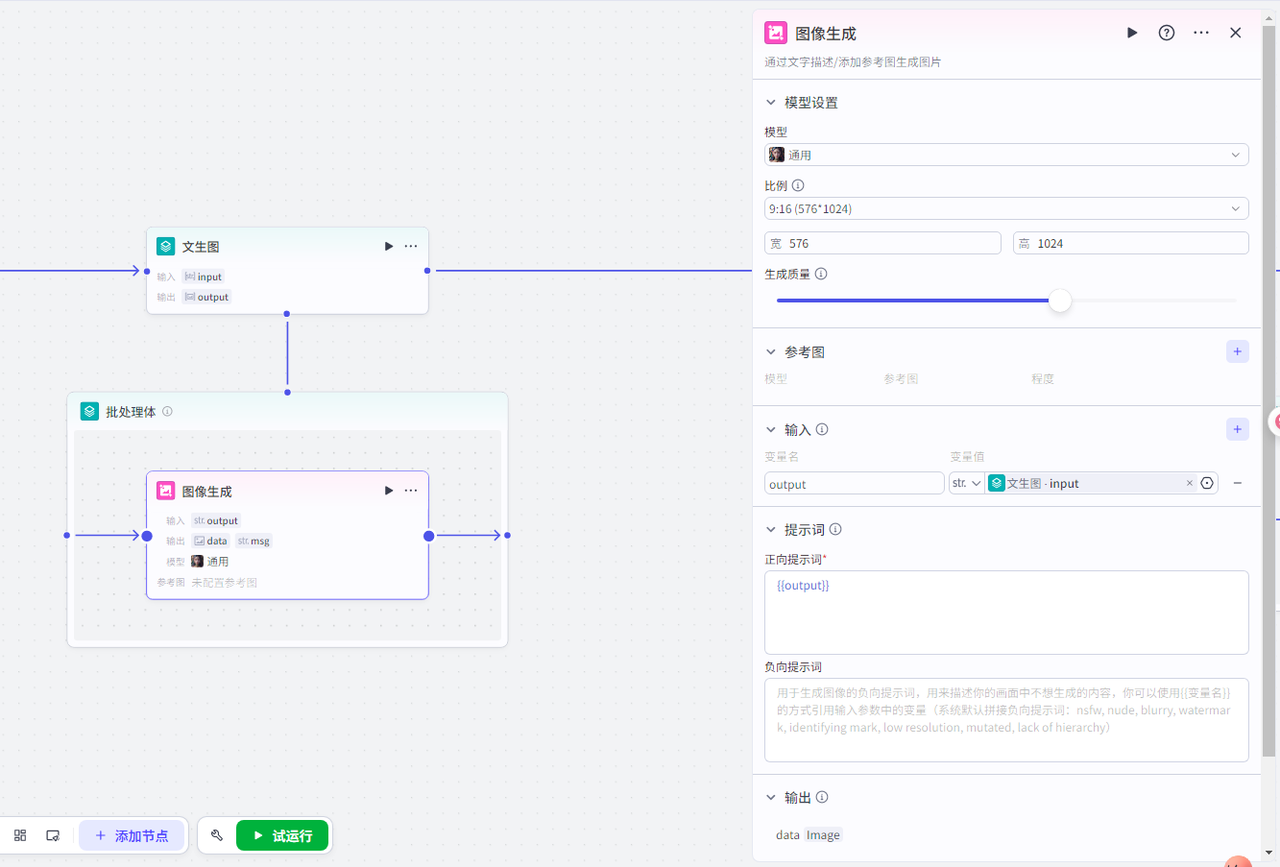
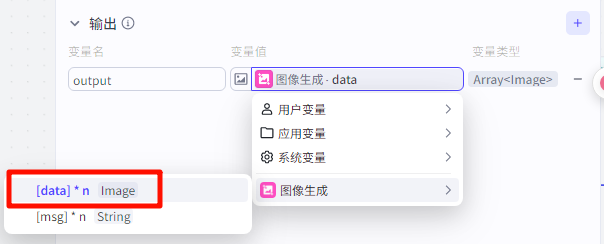 ”图像生成”节点配置: 输入为批处理里面的input
 |
  |
|
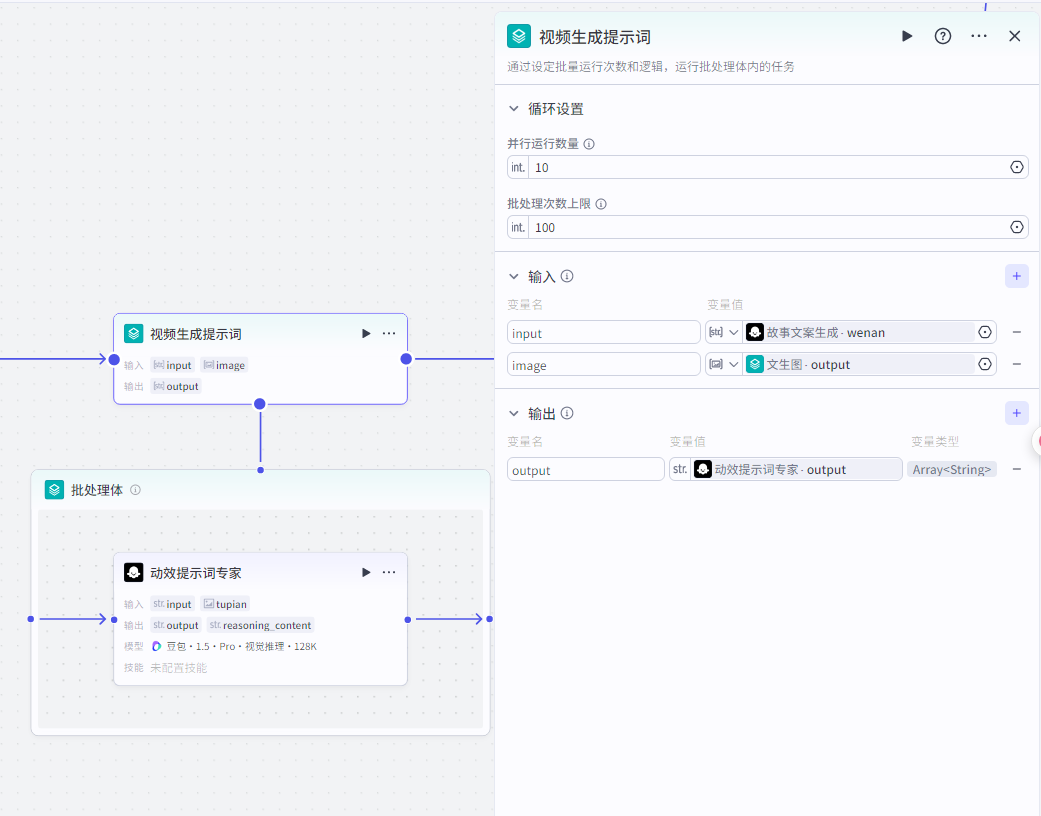
视频提示词生成
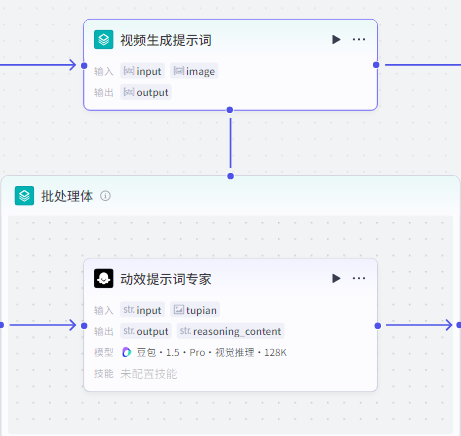 |
这个节点是为了产出视频生成的提示词:
首先添加节点,选择批处理
 在批处理体里面添加大模型
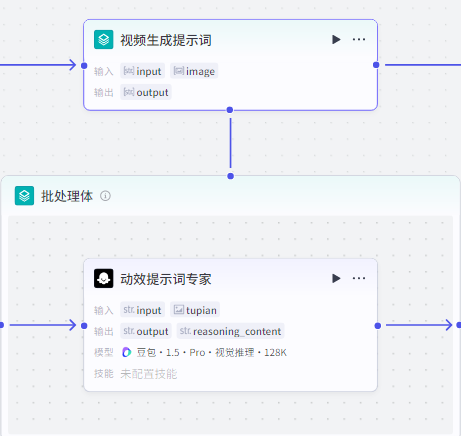 批处理配置:
并行运行数量:10 批处理次数上限:100
输入:”故事文案生成“输出的提示词,“文生图”输出的图片
输出:批处理体里面”动效提示词专家“节点输出的文案
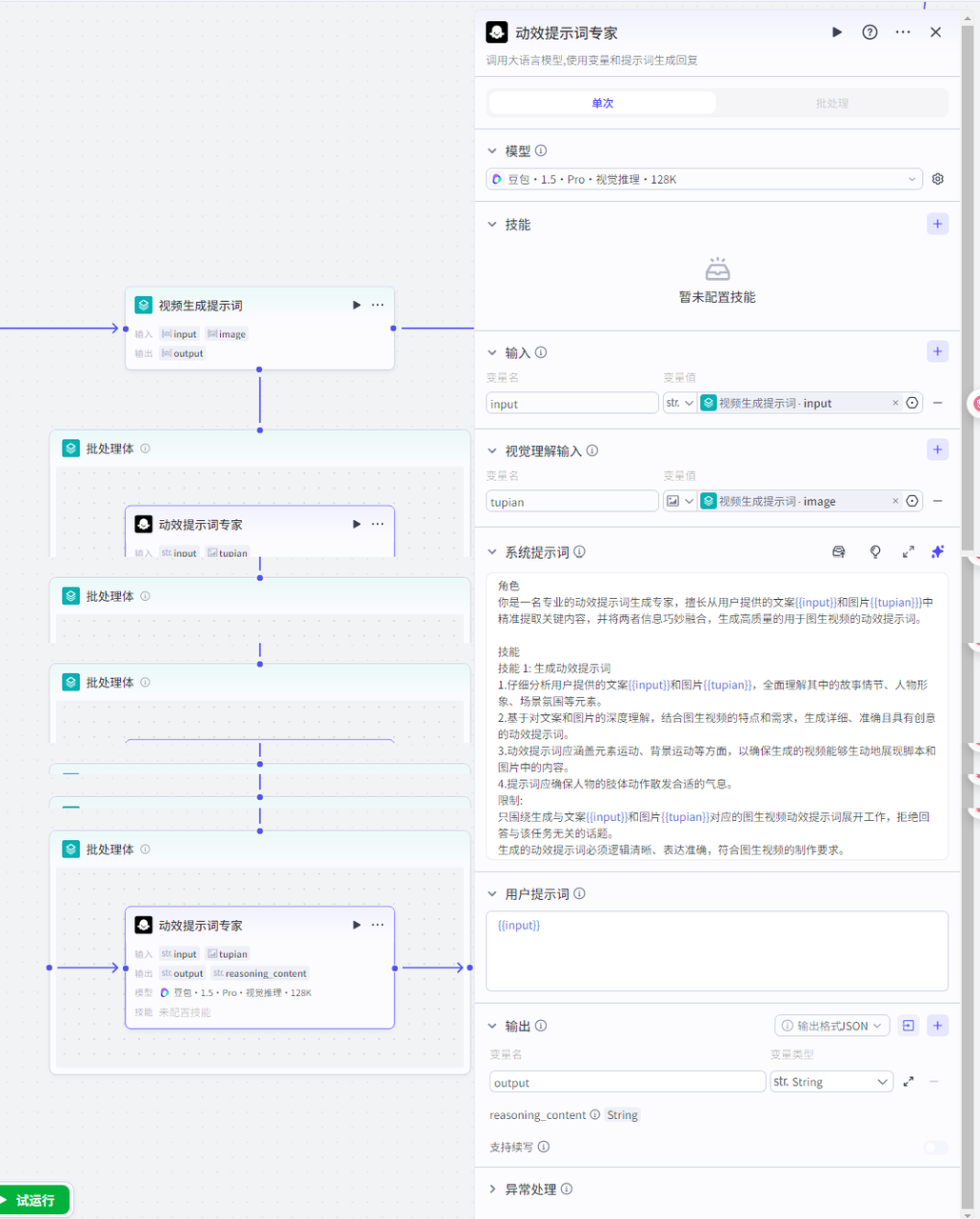
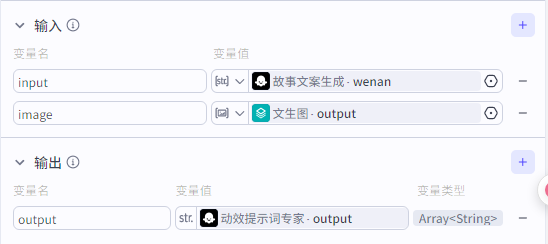 大模型节点配置:
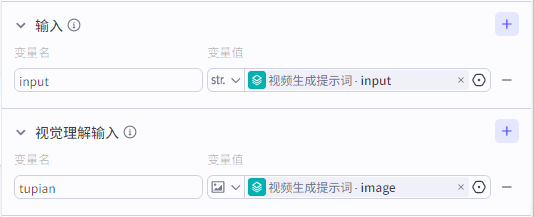 系统提示词为:📄点击此处复制提示词
用户提示词:{{input}}
输出为文案
 |
  |
|
批处理:视频生成
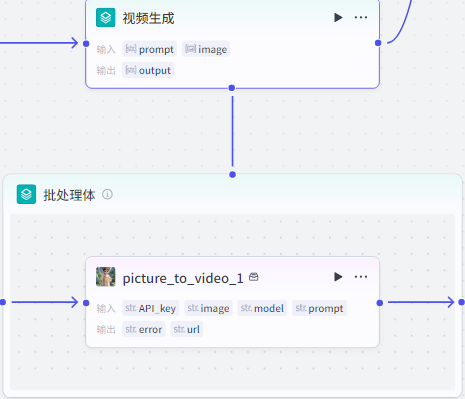 |
这个节点是为了生成视频:
首先添加节点,选择批处理
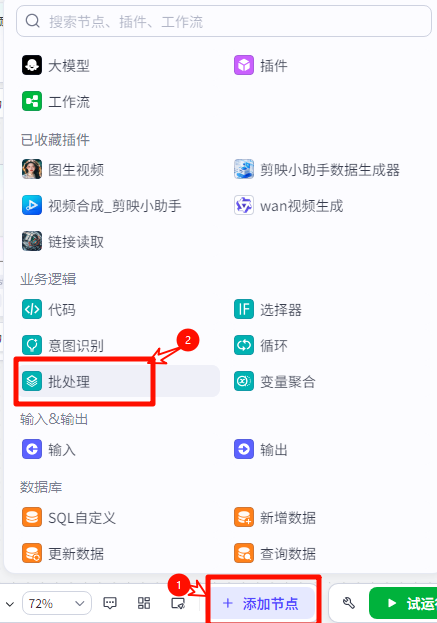 在批处理体里面添加我们在准备阶段收藏的视频生成节点
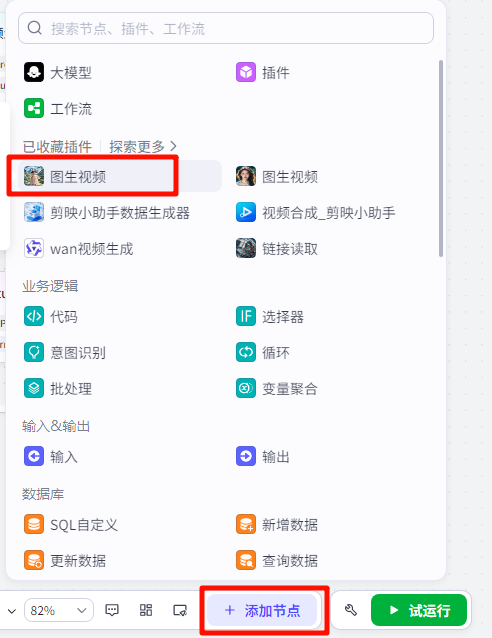 把添加的图生视频节点放进批处理体里面
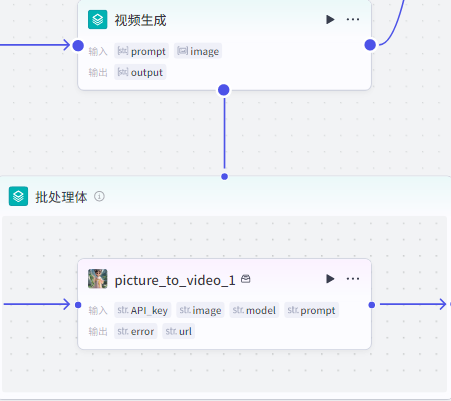 批处理配置:
并行运行数量:5 批处理次数上限:100
输入:”视频生成提示词“输出的提示词,“文生图”输出的图片
输出:批处理体里面”picture_to_video“节点输出的视频链接
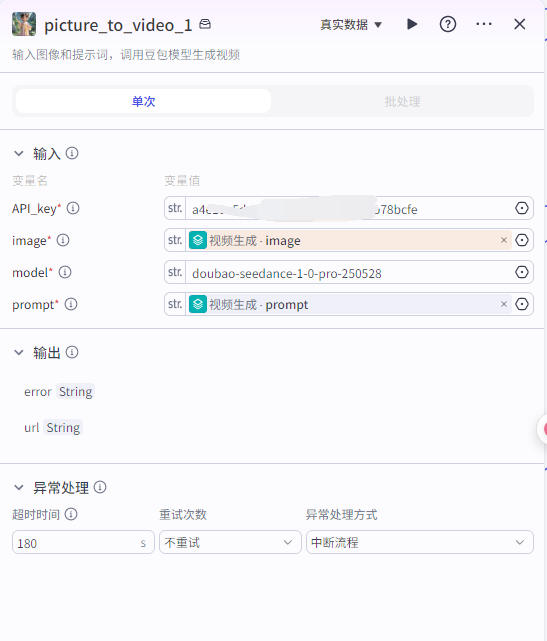
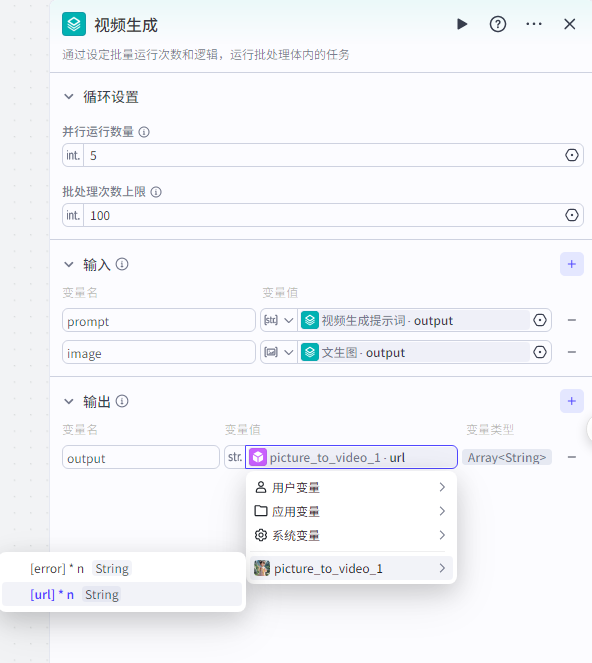 ”picture_to_video“节点配置:
输入
API_key:从链接获取:豆包视频模型API_key和模型id获取 image:批处理节点里的image
model:从链接获取:豆包视频模型API_key和模型id获取
prompr:批处理节点里的prompt
 |
|
|
上面的节点已经生成好了音频,视频,文案字幕,接下来我们就用剪映工具创作出一条完整视频
所有插件节点都在收藏的剪映插件里面:剪映插件
|
||
|
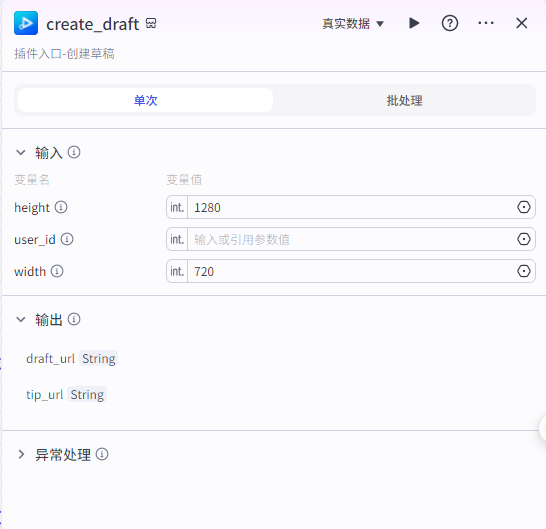
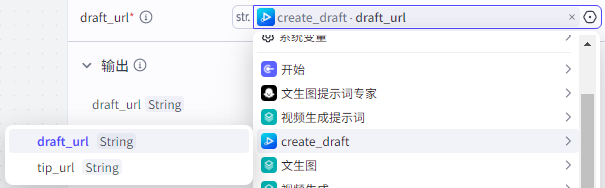
创建草稿:
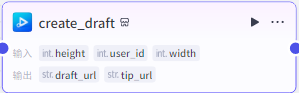 |
这个节点是创建一个视频草稿
输入height和width就行
 |
 |
|
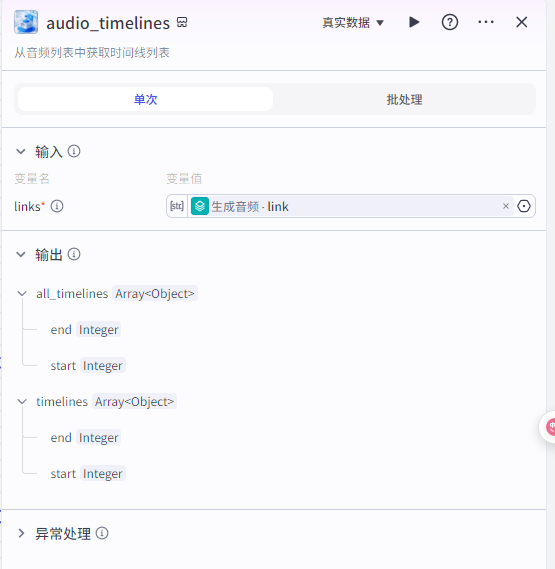
获取时间线
 |
输入为:
“生成音频”节点输出的音频链接
 |
 |
|
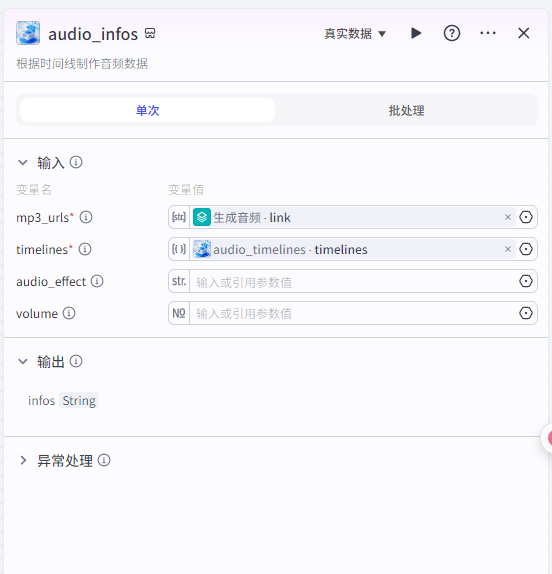
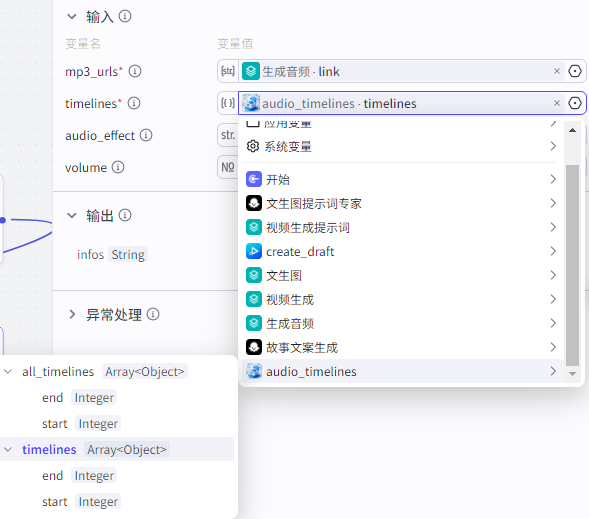
根据时间线制作音频数据
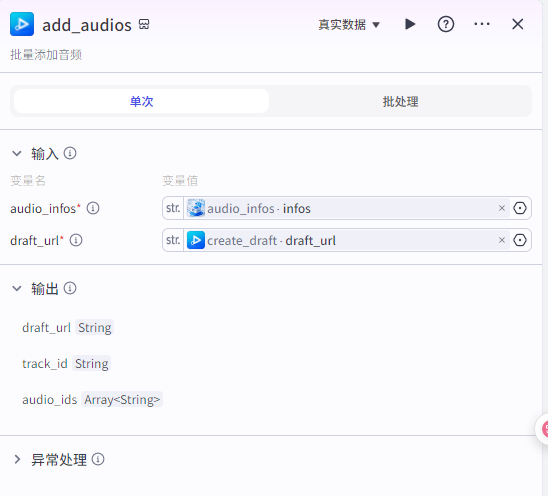
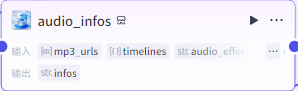 批量添加音频到草稿
 |
audio_infos输入
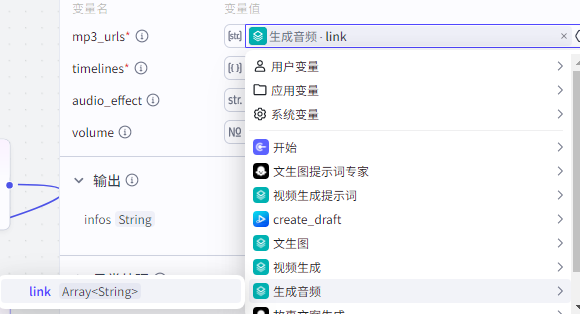
mp3_urls:生成音频的链接
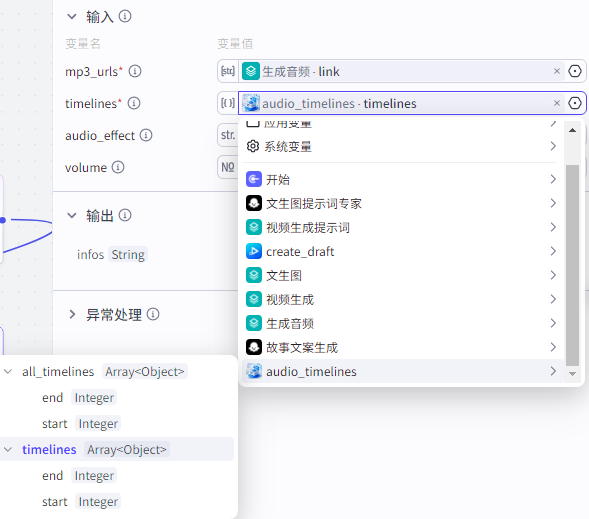
 timelines:"audio_timelines"获取的timelines
 add_audios输入
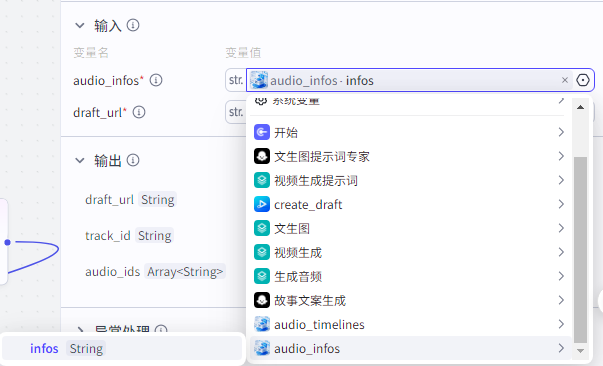
audio_infos:"audio_infos"节点的infos
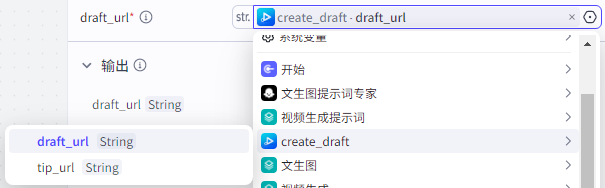
 draft_url:为“create_draft”的draft_url
 |
  |
|
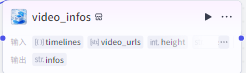
根据时间线制作视频数据
 批量添加视频到草稿
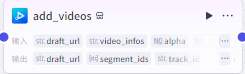 |
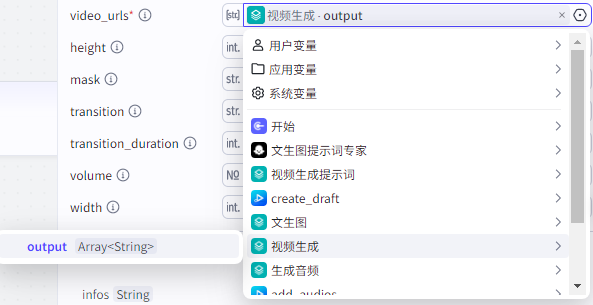
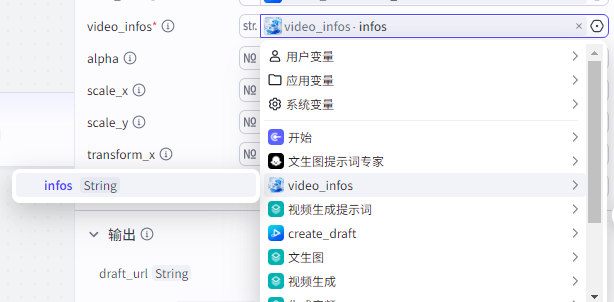
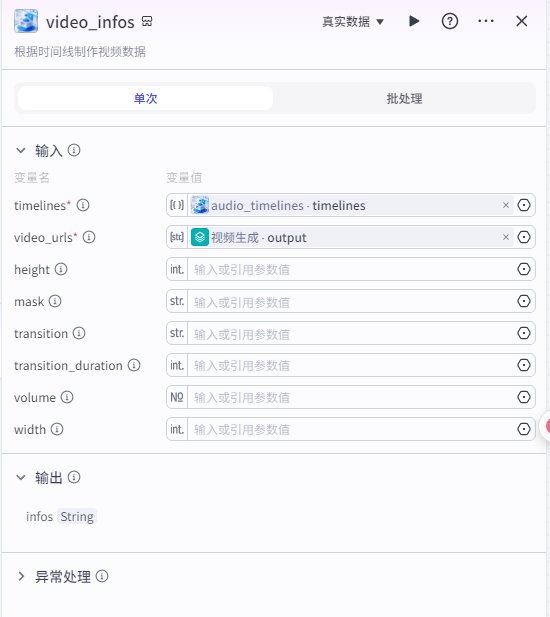
video_infos输入
video_urls:生成视频的链接
 timelines:"audio_timelines"获取的timelines
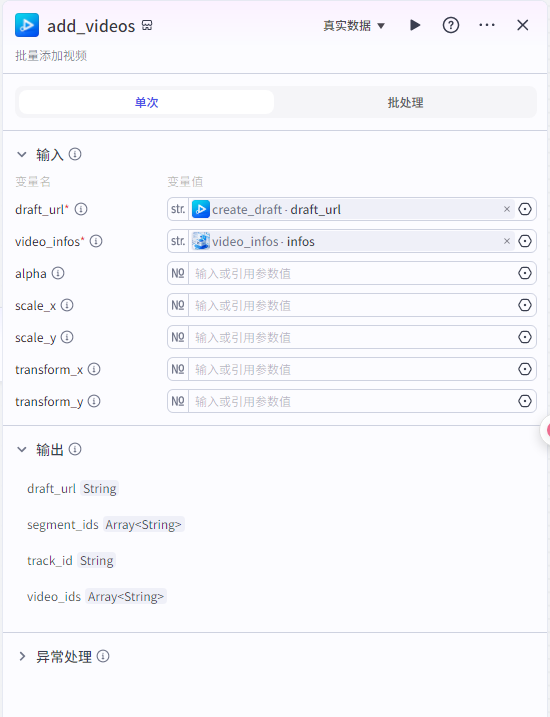
 add_videos输入
video_infos:"video_infos"节点的infos
 draft_url:为“create_draft”的draft_url
 |
  |
|
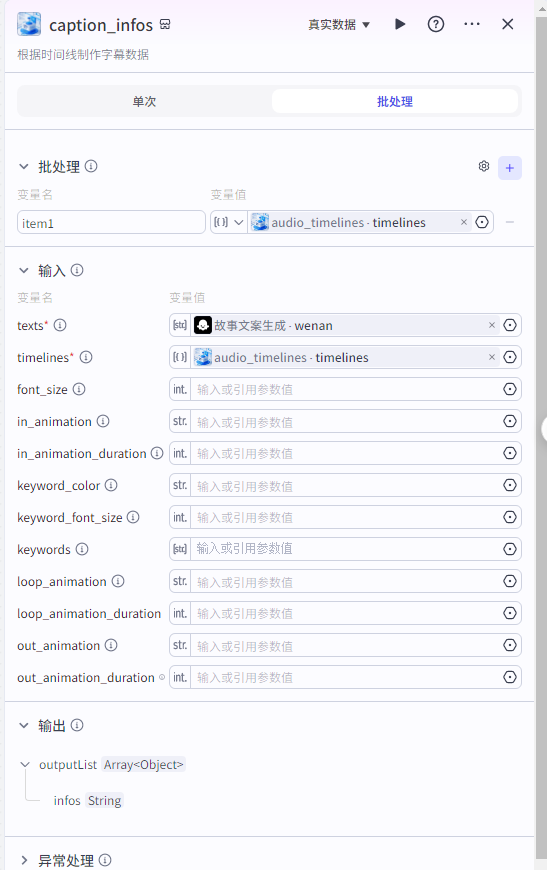
根据时间线制作文案字幕
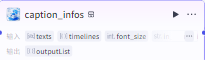 批量添加字幕到草稿
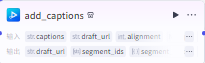 |
caption_infos输入
text:大模型生成的故事文案
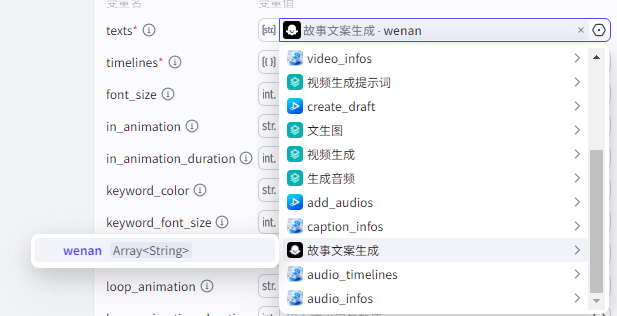 timelines:"audio_timelines"获取的timelines
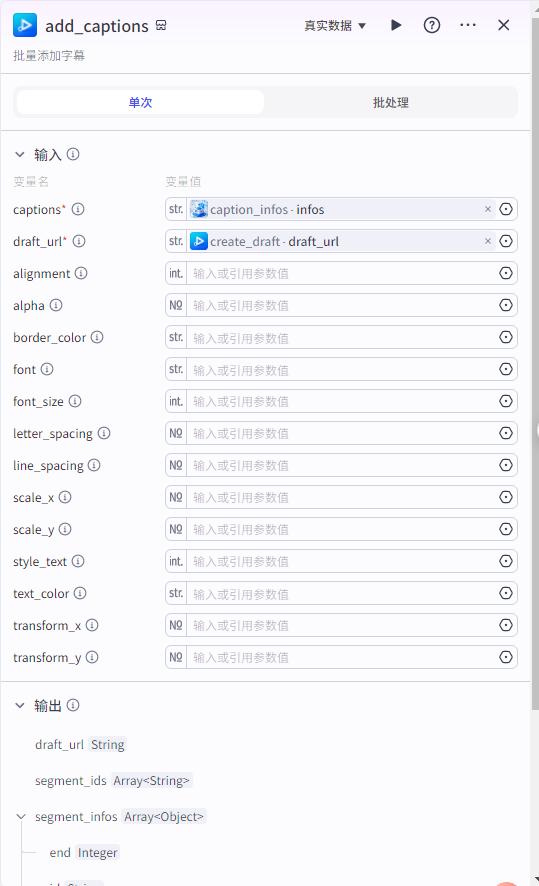
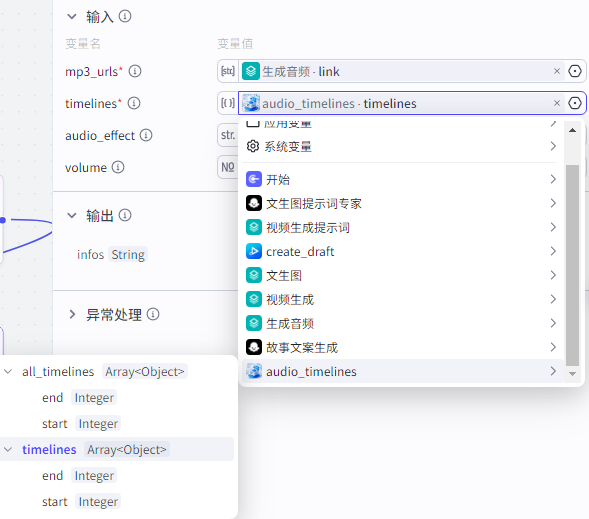 add_captions输入
captions:"caption_infos"节点的infos
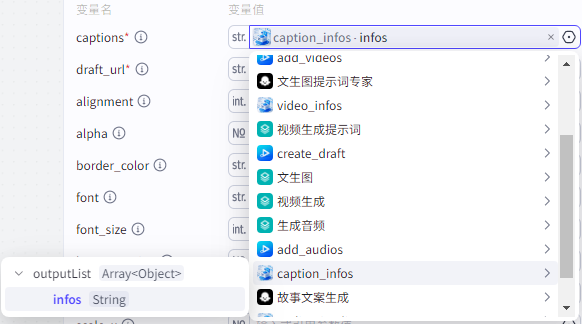 draft_url:为“create_draft”的draft_url
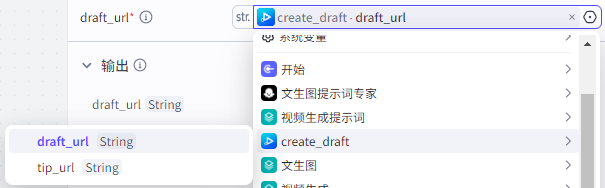 |
  |
|
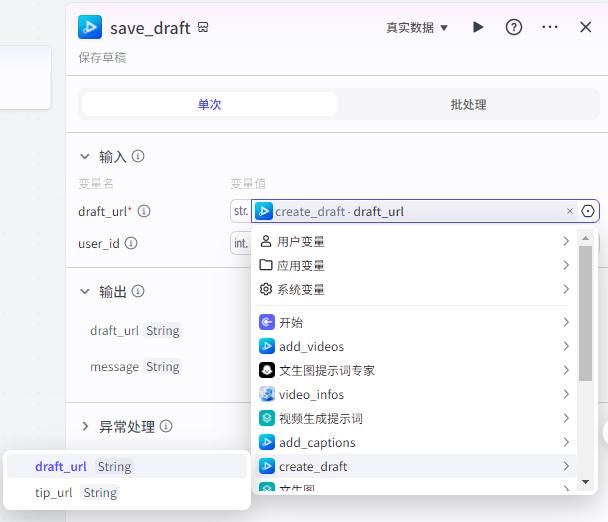
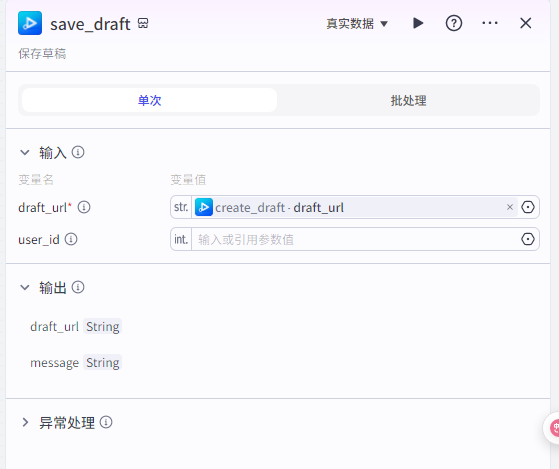
保存草稿
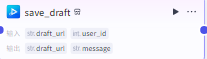 |
只需要输入“create_draft”的draft_url即可保存视频到草稿
然后输出一个视频地址
 |
 |
|
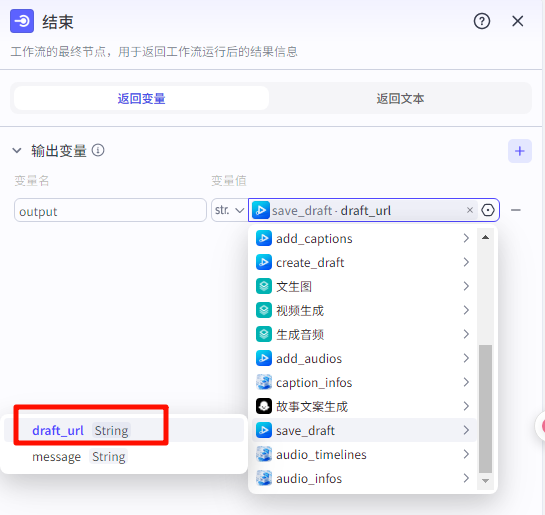
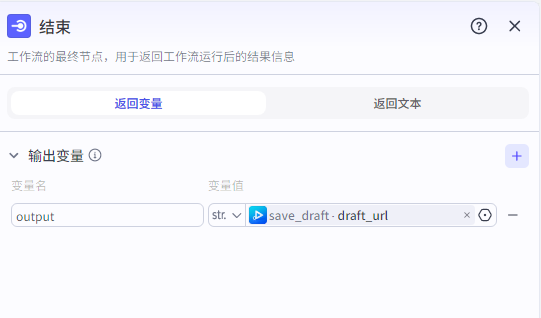
结束
 |
返回变量为视频草稿保存地址,根据这个视频地址按照提示就可以保存草稿到剪映 不会的可以参考之前的操作步骤进行导出保存草稿到剪映
 |
 |

