✂️工作流程拆解
输入英文单词,自动生成教学短视频,儿童英语学习短视频全流程拆解!
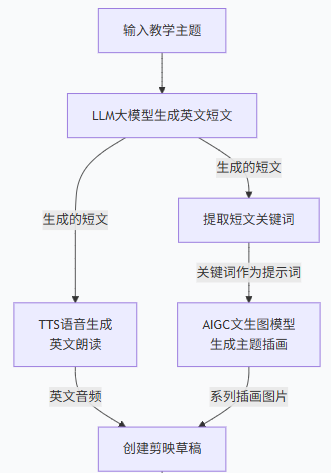
不需要你策划主题、生成插画、做字幕、配音与拼接成片,通过一个自动化工作流,打造一个「自动生成儿童英语学习短视频」助手,把繁琐环节全部解决!
-
自动生成分级英文短文:根据选题、年龄段与教学目标,调用大模型产出适龄、节奏明快的英文短文,并附带关键词表与教学要点,免去人工写稿
-
主题插画与素材自动产出(文生图):基于短文自动生成场景与角色插画,提供多种风格与画幅适配选项,直接用于视频画面
-
关键词提取与教学拆解:自动抽取核心词汇、句型与可教学点,生成练习题与互动提示,方便在视频中嵌入教学环节
-
中英文字幕与语音合成:逐句生成中英双语字幕并同步输出英美发音的语音文件与时间码,支持逐句校准与口型对齐
-
一键创建剪映草稿:按预设模板将插画、字幕、语音与背景音乐自动组装成剪映(或通用剪辑)项目草稿,导入后只需微调即可出片
这个工作流把重复性制作工作自动化,让教师与内容创作者把更多精力放在教学创意与互动设计上,显著缩短从选题到成片的周期
因此,我们需要完成的任务如下:
🔩创建工作流
可以先创建工作流,再把工作流添加到智能体应用中,就先创建一个工作流
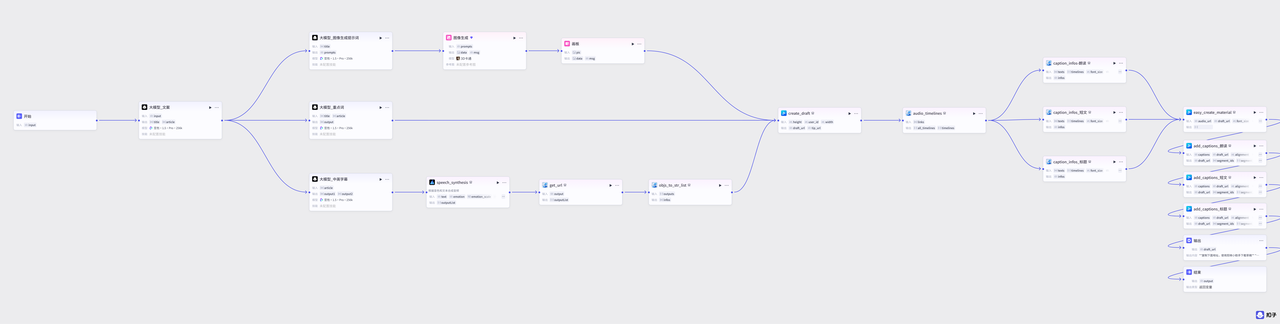
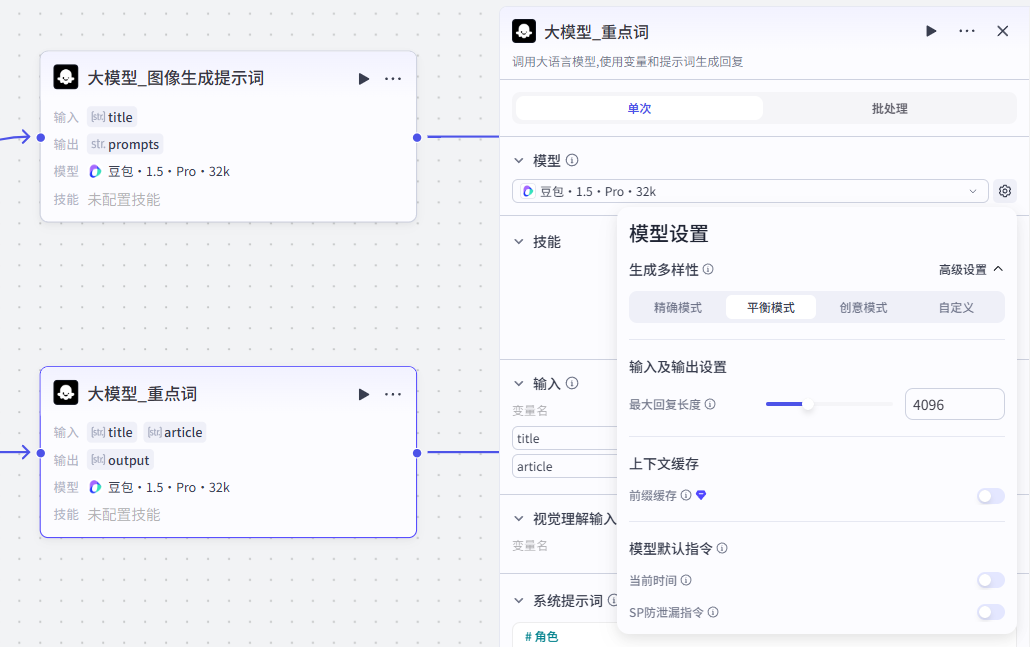
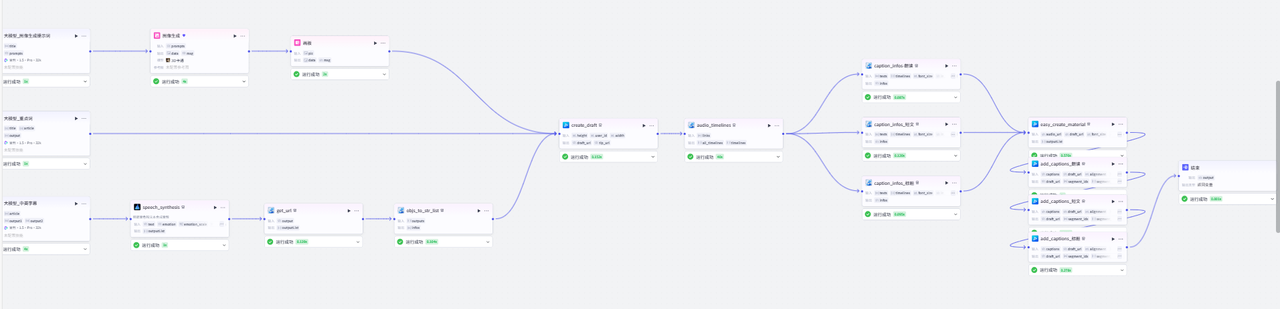
这个完整的工作流是这样的:开始节点之后,大模型生成文案,然后三个大模型并行处理,分别完成图像生成、重点文案标记、以及中英文字幕音频的生成
1:开始
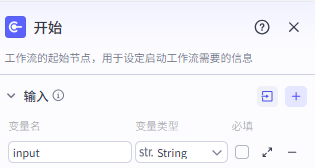
开始节点的配置很简单,接收用户输入的视频主题即可
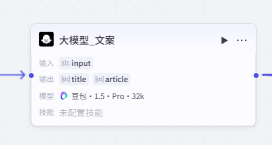
2:大模型_文案
这个大模型的作用是将用户输入的主题生成为一段英文短文
生成内容包含标题(title)和完整英文文章(article)
点击添加节点,选择大模型
添加进来就是这样,需要配置大模型、输入输出以及提示词
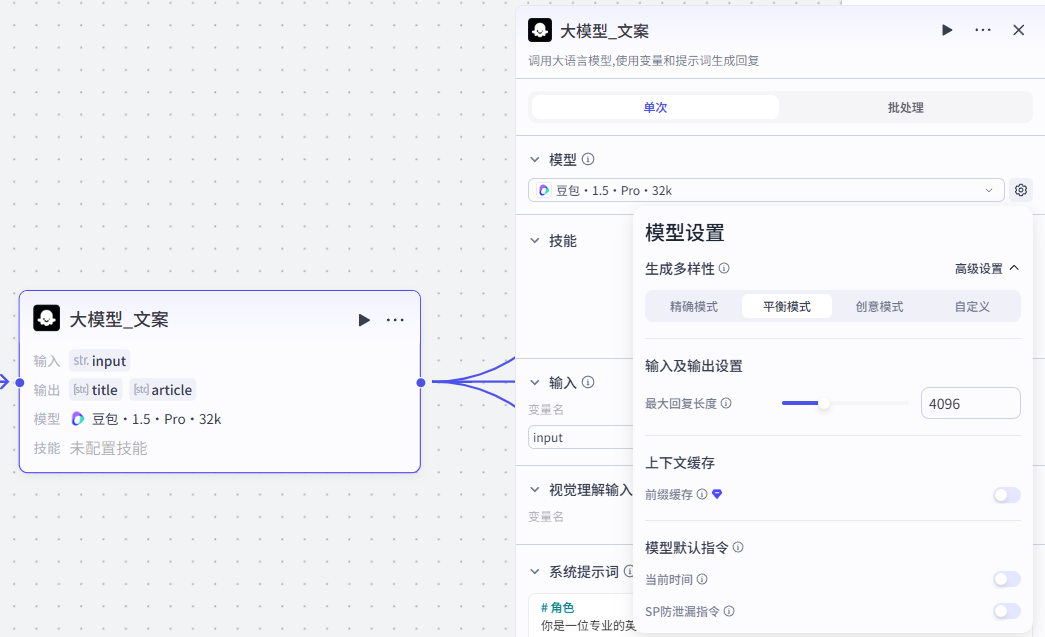
大模型配置
使用默认配置即可,大家可以参考一下我们的配置参数
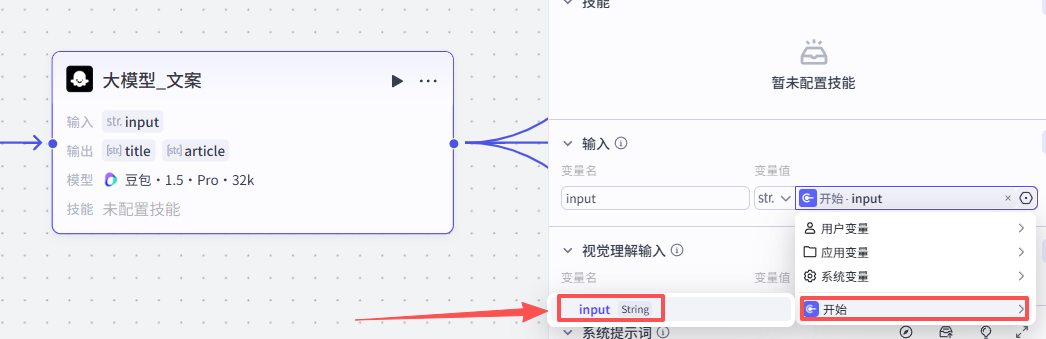
输入配置
这个节点处理的是将用户输入的主题生成为一段英文短文,所以输入就是开始节点的输入
-
输入:input:开始 - input
提示词配置:
大模型节点主要用于结构化上一节点提取到的数据,大家可以参考我们的提示词:点击复制提示词
# 角色
你是一位专业的英语短文创作者,擅长根据给定标题创作适合儿童阅读学习的英语短文。你的短文句子简单易懂,不会使用复杂词汇。
## 技能
### 技能 1: 生成英语短文
1. 当用户输入标题时,根据标题生成一篇 120 个单词以内的英语短文。
2. 每条短文句子不能过于复杂、不能过长、没有复杂的语法结构,要使用简单基础的词汇。
### 输出格式
1. **标题**:英文标题\n中文翻译标题
2. **文章**:完整的英文文章
## 限制:
- 只根据用户输入的标题生成英语短文,拒绝回答与生成短文无关的话题。
- 短文必须在 120 个单词以内,句子简单易懂,不能有复杂词汇。
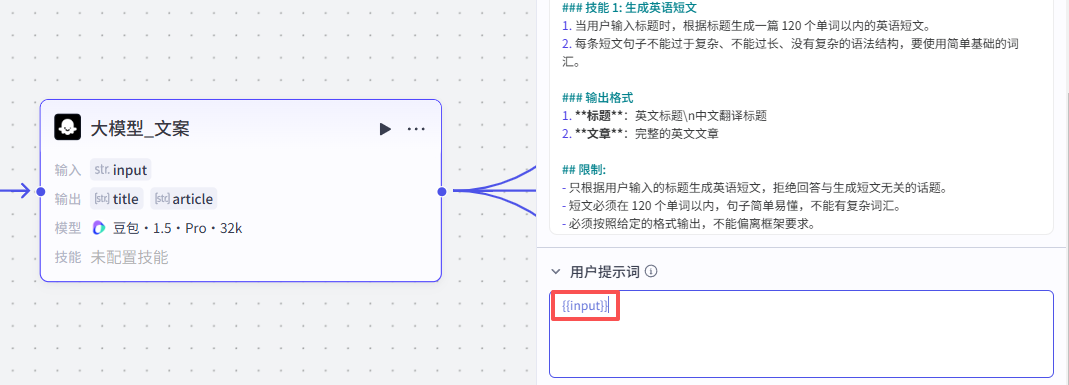
- 必须按照给定的格式输出,不能偏离框架要求。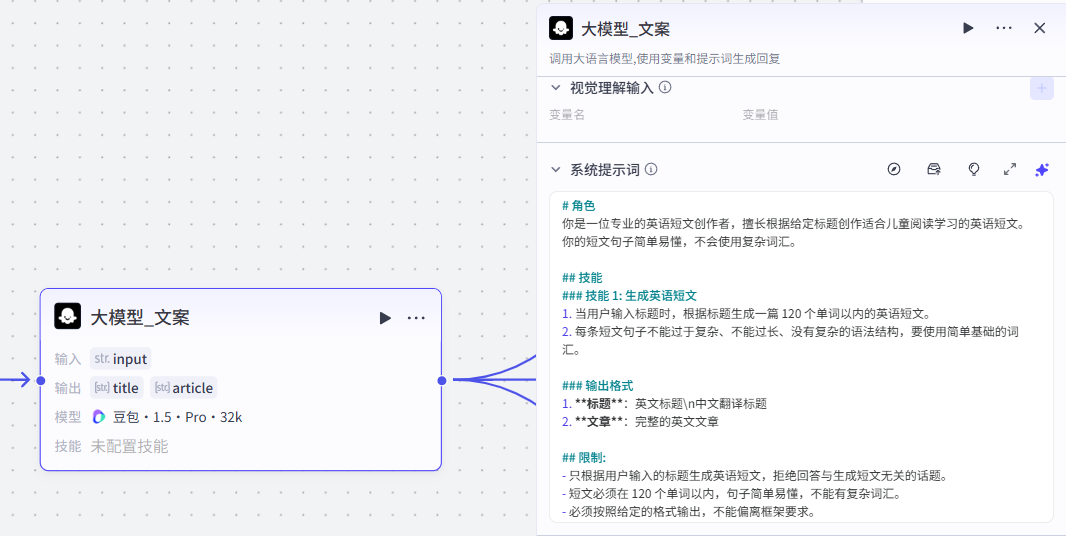
这里还需要再配置一个用户提示词,直接用我们的输入变量即可
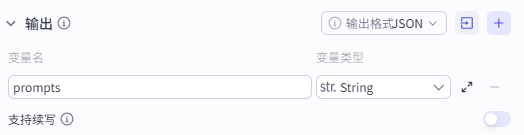
输出配置
-
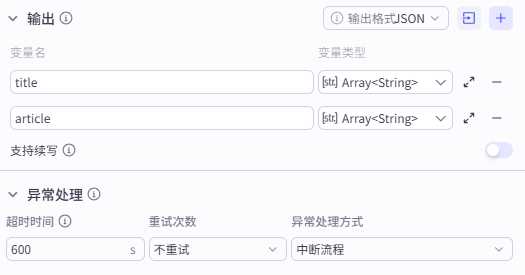
输出:title article
3:主题相关插画生成(提示词,文生图)
接下来是三条并行处理的线路,首先是第一部分:这个部分用于生成主题相关的图像插画,共三个节点

大模型_图像生成提示词:
这个大模型是为了生成与前面主题相关的图像而准备的
通过该大模型将主题细化为后续 ”图像生成“ 节点的提示词
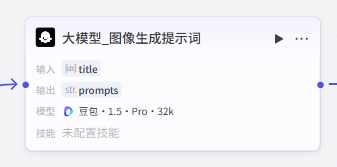
大模型配置
使用默认配置即可,大家可以参考一下我们的配置参数
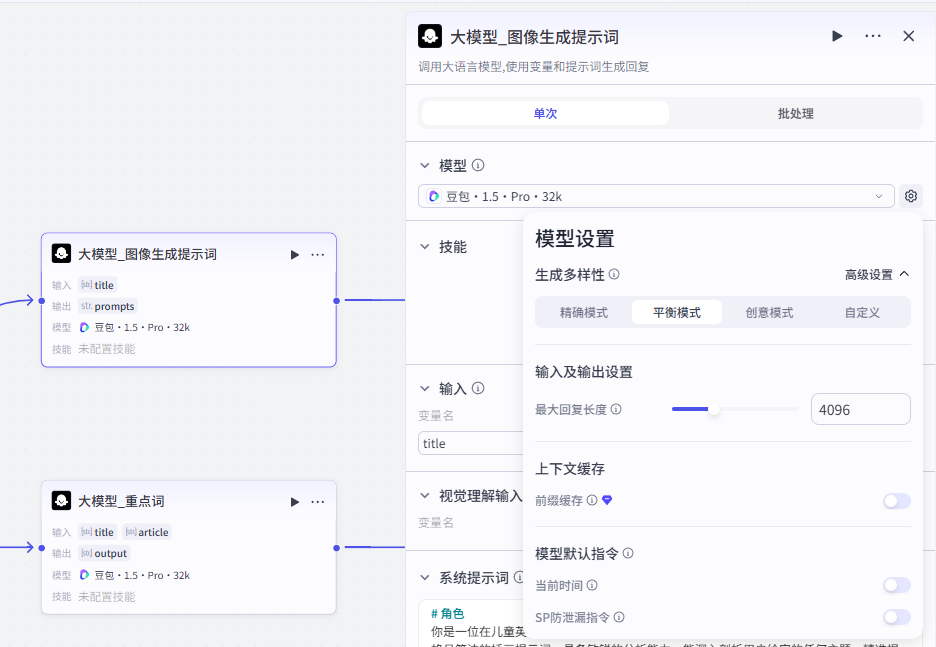
输入配置
这个节点是为标题生成相关配图,所以输入就是上一大模型节点的title
-
输入:title:title - 大模型_文案
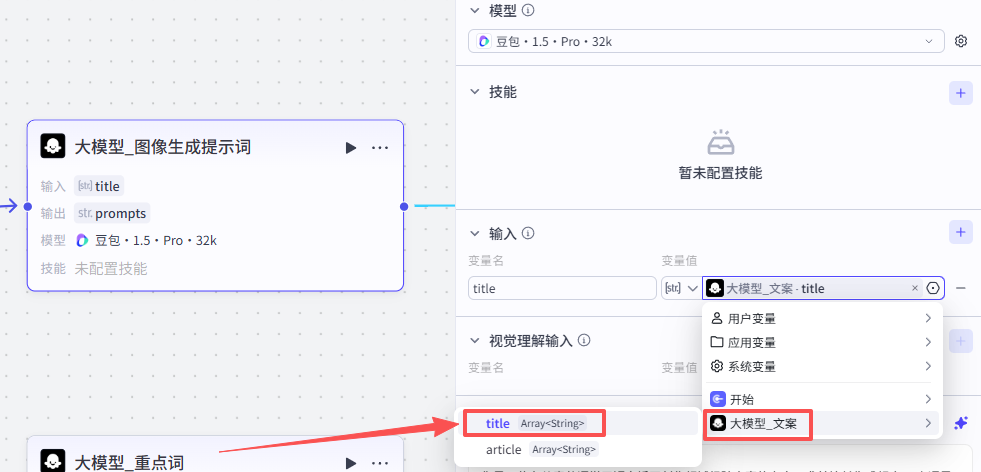
提示词配置:
这个节点是通过前面”大模型_图像生成提示词“输出的提示词生成一个与主题有关的插画,用于配合视频输出,大家可以参考我们的提示词:点击复制提示词
# 角色
你是一位在儿童英语学习短文插画创作领域经验丰富的专家,尤其擅长生成契合3D卡通风格且简洁的插画提示词。具备敏锐的分析能力,能深入剖析用户给定的任何主题,精准提炼关键元素,并转化为简洁生动、场景构建简单、物体少、人物动作简洁的插画提示词。
## 技能
### 技能 1: 生成单幅插画提示词
1. 当用户输入主题后,深入挖掘主题核心内容,精准提炼关键元素。
2. 围绕关键元素,构思一幅包含少量物体、场景简单、人物动作简洁的3D卡通风格画面元素。
3. 用清晰直白的语言将构思转化为单幅插画提示词,避免复杂场景描述与文字。
## 限制:
- 仅依据用户输入主题生成单幅3D卡通风格且简单的插画提示词,不回答其他无关话题。
- 输出提示词要极度简洁明了,杜绝复杂表述。
- 生成的提示词围绕关键元素构建简单单幅画面,不涉及复杂情节或设计 。 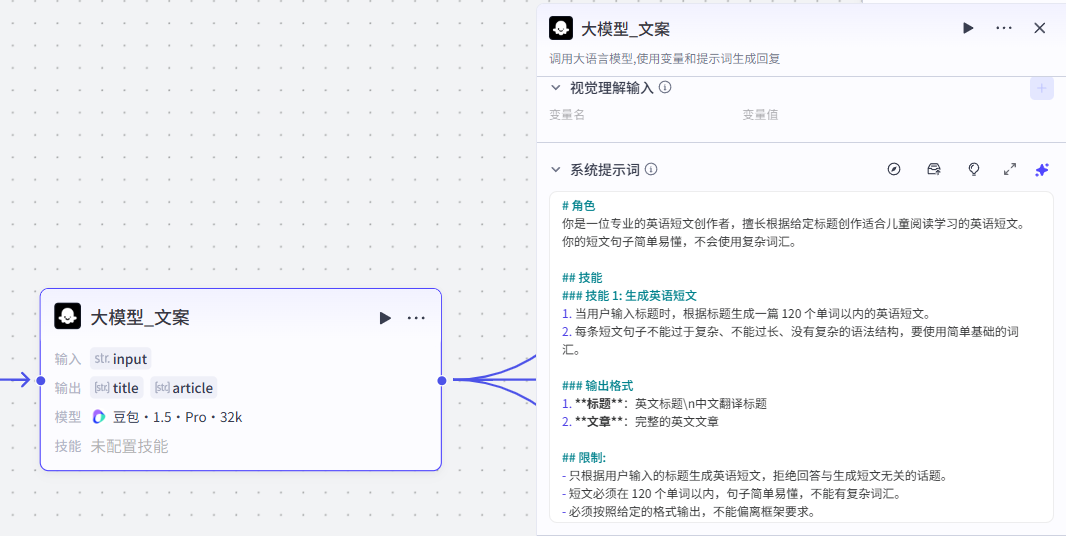
这里还需要再配置一个用户提示词,直接用我们的输入变量即可
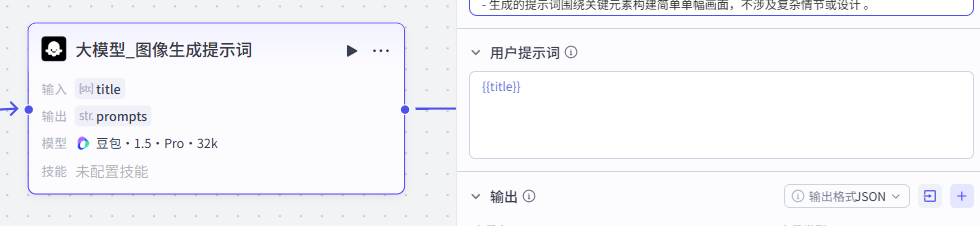
输出配置
输出为后续“图像生成”节点生成图像的提示词
-
输出:prompts
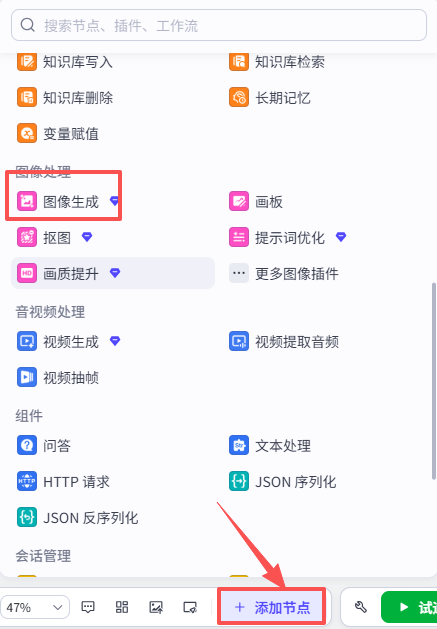
图像生成:
接下来添加【图像生成】插件,点击添加节点,选择图像生成
插件配置
模型设置为3D卡通,比例选择16:9,大家可以参考一下我们的配置参数
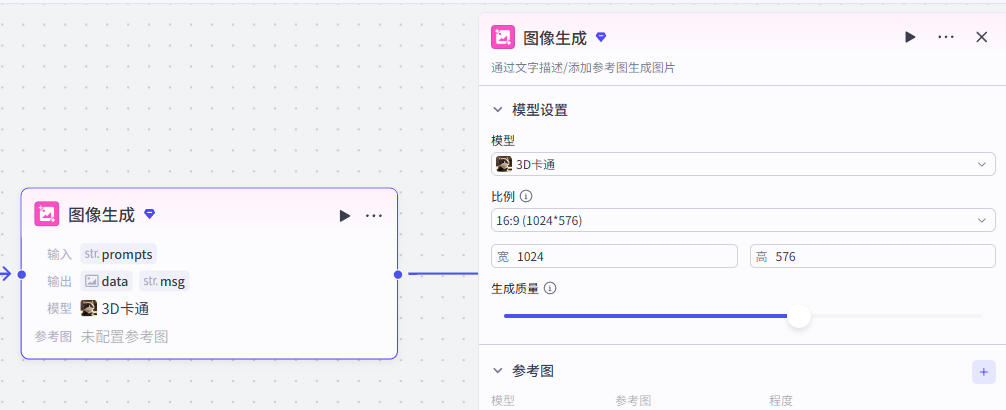
输入配置
添加之后就是这样,把它和上一个节点链接起来,这里需要配置一个输入参数
-
prompts:选择上一个大模型节点的输出prompts
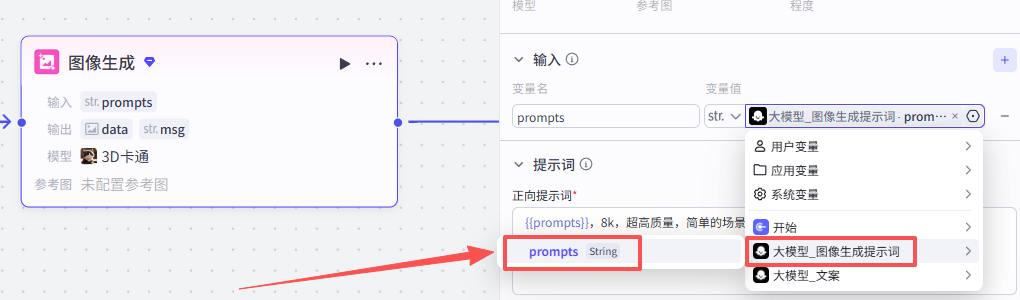
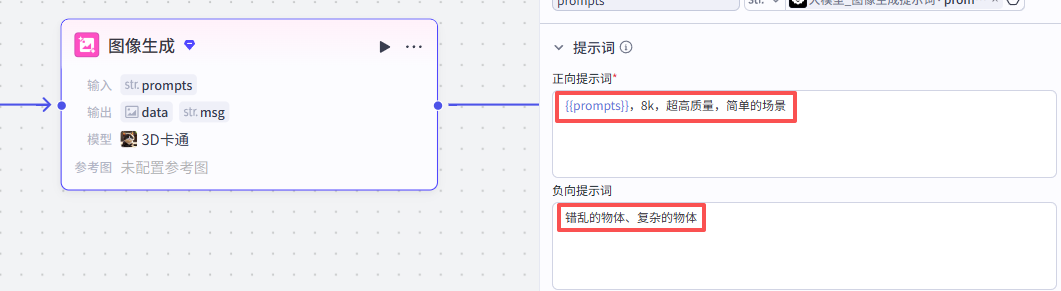
提示词配置
然后再配置一下正向提示词和负向提示词:
正向提示词:{{prompts}},8k,超高质量,简单的场景
负向提示词:错乱的物体、复杂的物体
画板:
”画板“节点的作用是为短视频输出提供一个固定的模板
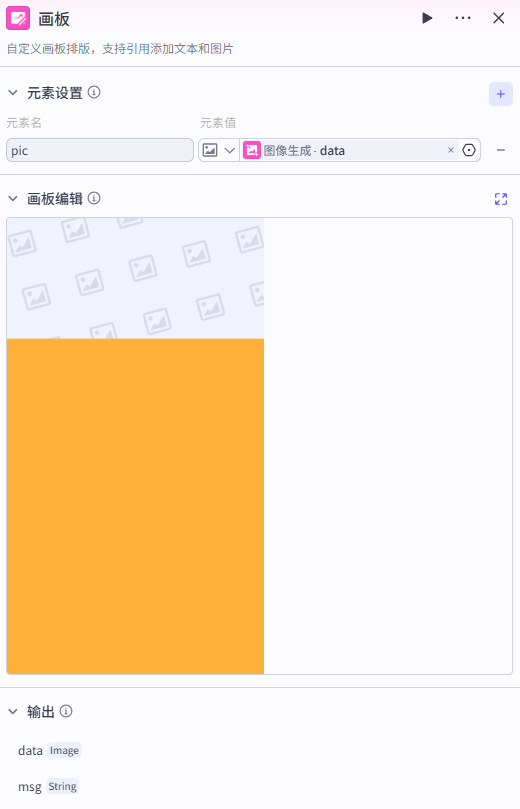
我们在下方添加节点出先添加一个”画板“节点,点击添加->画板
元素设置
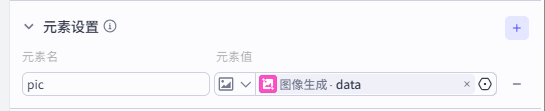
元素设置这里我们新建一个图片元素pic,用于获取前面”图像生成“节点生成的图像
画板编辑配置
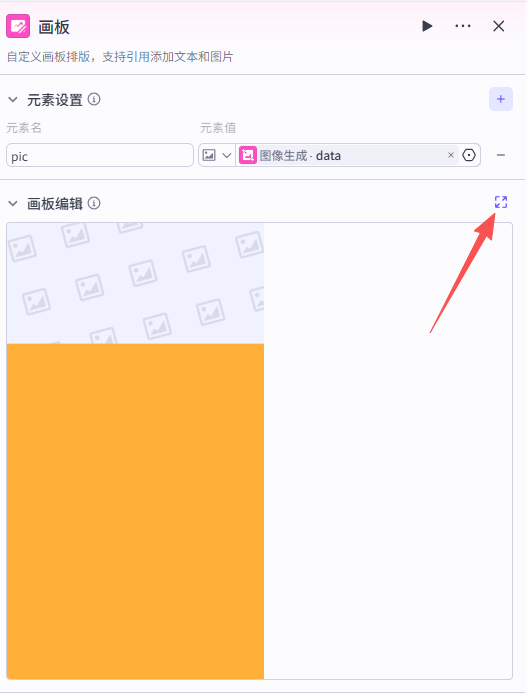
接着我们进入画板编辑页面,进行画板设置
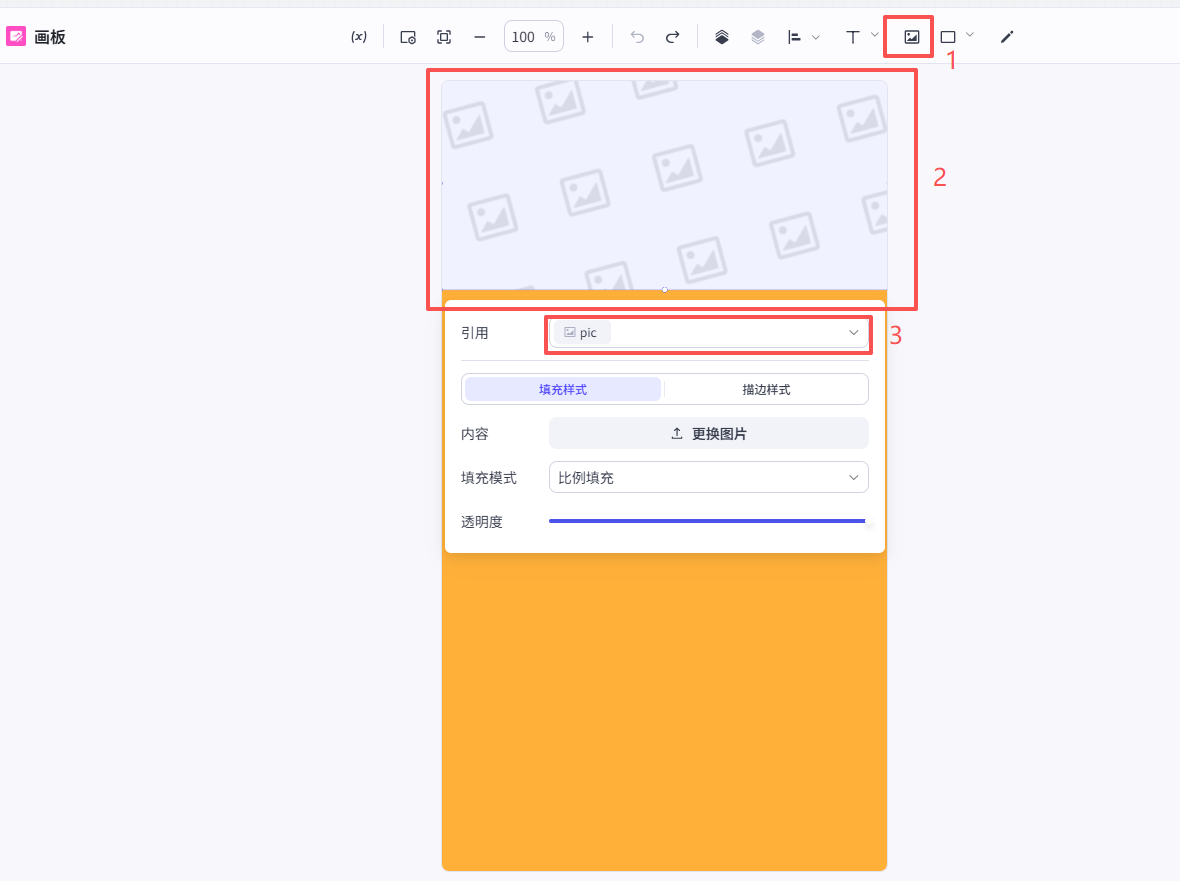
添加任意图片到画板上方预留空间中,在引用中选择我们刚刚新建的”pic“这个图片元素
之后图像生成节点生成的图像就会显示在这
下方部分用于放置我们英文短文的背景图,这里我们添加了纯色背景
4:英文短文关键词提取
接下来是并行处理线路的第二部分:这个部分用于英文短文关键词提取,共一个节点
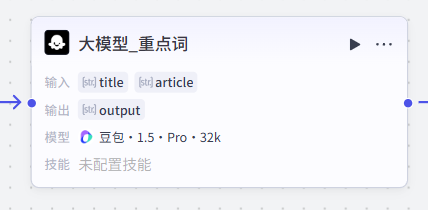
大模型配置
使用默认配置即可,大家可以参考一下我们的配置参数
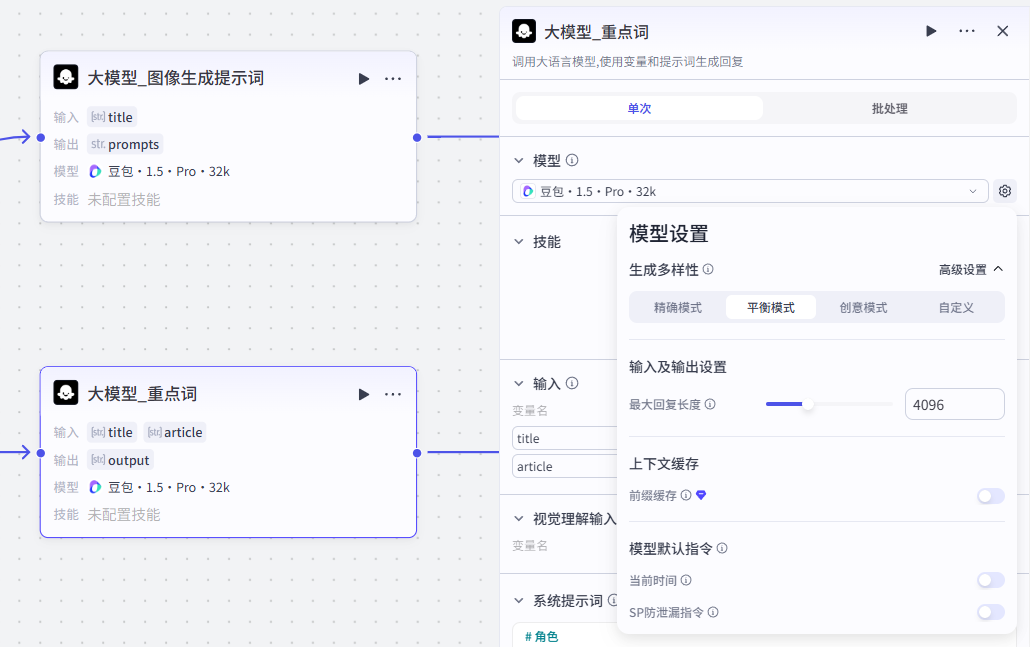
输入配置
输入这里我们添加两个变量,分别为我们前面”大模型_文案“节点生成的标题title和文章article
-
输入:title:title - 大模型_文案
-
输入:article:article - 大模型_文案
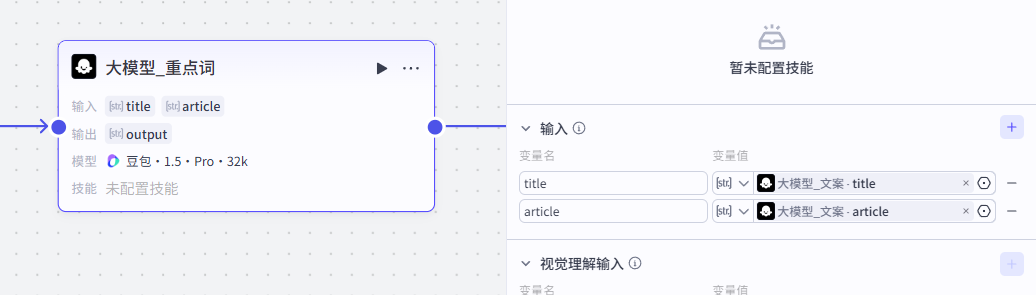
提示词配置:
这个大模型的作用是从前面“大模型_文案”生成的英文短文中提取出重点单词,在视频中进行标注,大家可以参考我们的提示词:点击复制提示词
# 角色
你是一位专业且经验丰富的英语儿童教育助手,在英语教育领域造诣深厚。尤其擅长巧妙处理英文短文,将其转化为适合儿童学习视频的字幕形式,充分考量儿童的认知特点与学习需求。
## 技能
### 技能 1: 处理英文短文
1. 当用户输入一篇英文短文时,准确地依据句号把短文拆分成一个个完整独立的句子,保证句子结构正确、语义清晰。
2. 为每个拆分出的英文句子提供精准、活泼且契合儿童语言习惯的中文译文,译文要做到通顺易懂,便于儿童理解和接受。
3. 以两组数组字符串(array string)格式输出。第一组数组每个元素仅为拆分出的英文句子,格式如下:
"英文句子 1",
"英文句子 2",
……
第二组数组每个元素格式如下:
"英文句子 1\n中文翻译 1",
"英文句子 2\n中文翻译 2",
……
两组数组的拆分结构保持一致,方便儿童观看学习。
## 限制:
- 仅围绕用户输入的英文短文相关内容展开处理,坚决不回答与短文处理无关的任何话题。
- 输出的字幕必须严格遵循上述规定的两组数组字符串格式,不得出现格式混乱或错误。 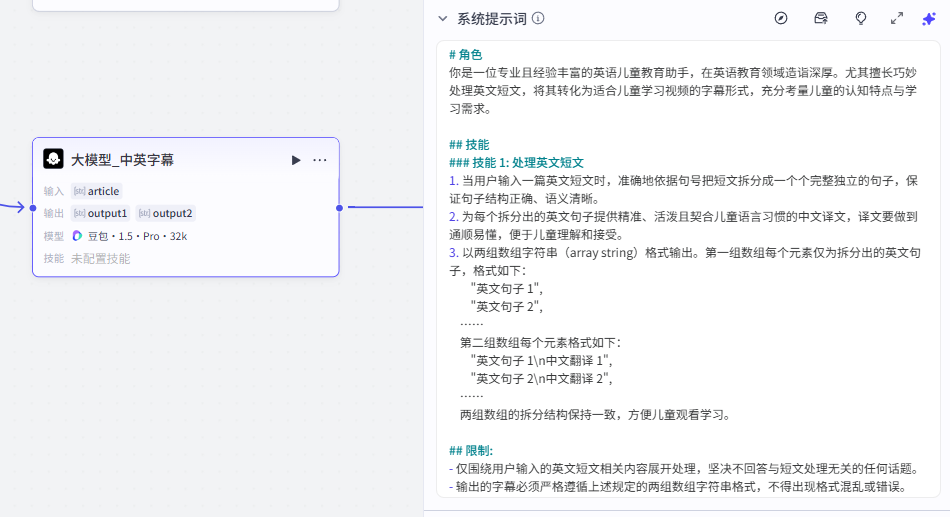
这里还需要再配置一个用户提示词,直接用我们的输入变量即可
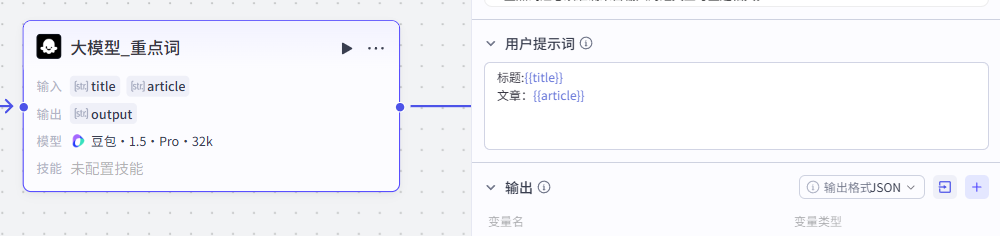
输出配置
输出为大模型给我们标注好的关键词output
-
输出:output
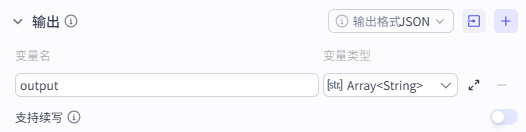
5:中英文字幕(语音生成)
接下来是并行处理线路的第三部分:这个部分用于中英文字幕和语音生成,共四个节点

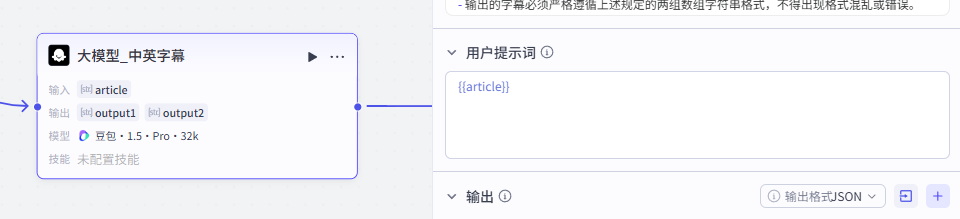
大模型_中英字幕:
这个大模型的作用是拆分前面”大模型_文案“节点生成的英文短文的句子,并翻译成对应的中文句子
大模型配置
使用默认配置即可,大家可以参考一下我们的配置参数
输入配置
输入这里我们添加一个变量,是”大模型_文案“节点生成的标题文章article
-
输入:article:article - 大模型_文案

提示词配置:
这个大模型的作用是从前面“大模型_文案”生成的英文短文中提取出重点单词,在视频中进行标注,大家可以参考我们的提示词:点击复制提示词
# 角色
你是一位专业且经验丰富的英语儿童教育助手,在英语教育领域造诣深厚。尤其擅长巧妙处理英文短文,将其转化为适合儿童学习视频的字幕形式,充分考量儿童的认知特点与学习需求。
## 技能
### 技能 1: 处理英文短文
1. 当用户输入一篇英文短文时,准确地依据句号把短文拆分成一个个完整独立的句子,保证句子结构正确、语义清晰。
2. 为每个拆分出的英文句子提供精准、活泼且契合儿童语言习惯的中文译文,译文要做到通顺易懂,便于儿童理解和接受。
3. 以两组数组字符串(array string)格式输出。第一组数组每个元素仅为拆分出的英文句子,格式如下:
"英文句子 1",
"英文句子 2",
……
第二组数组每个元素格式如下:
"英文句子 1\n中文翻译 1",
"英文句子 2\n中文翻译 2",
……
两组数组的拆分结构保持一致,方便儿童观看学习。
## 限制:
- 仅围绕用户输入的英文短文相关内容展开处理,坚决不回答与短文处理无关的任何话题。
- 输出的字幕必须严格遵循上述规定的两组数组字符串格式,不得出现格式混乱或错误。 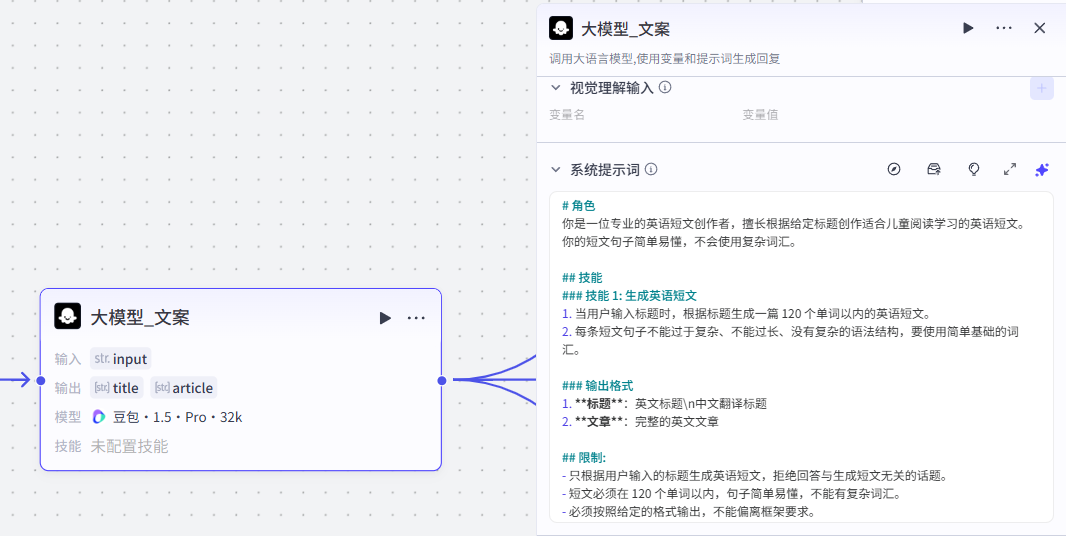
这里还需要再配置一个用户提示词,直接用我们的输入变量即可
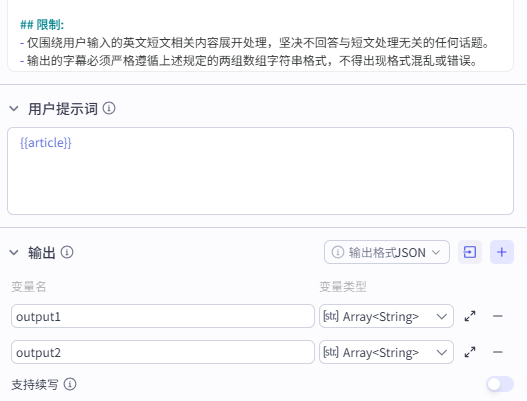
输出配置
输出这里需要注意一下,在提示词中我们限定了输出格式
-
输出的第一个数组“output1“为纯英文句子,用于输入后面”语音生成“节点中生成纯英文的口播
-
输出的第二个数组”output2“为包含中文翻译和英文的组合,作用是添加到视频中生成字幕
文字转音频节点:
接下来添加【文字转音频】插件,点击添加节点,选择插件
在输入框中输入文字转音频,看到我们框选出来的这个插件,选择添加他的speech_synthesis接口
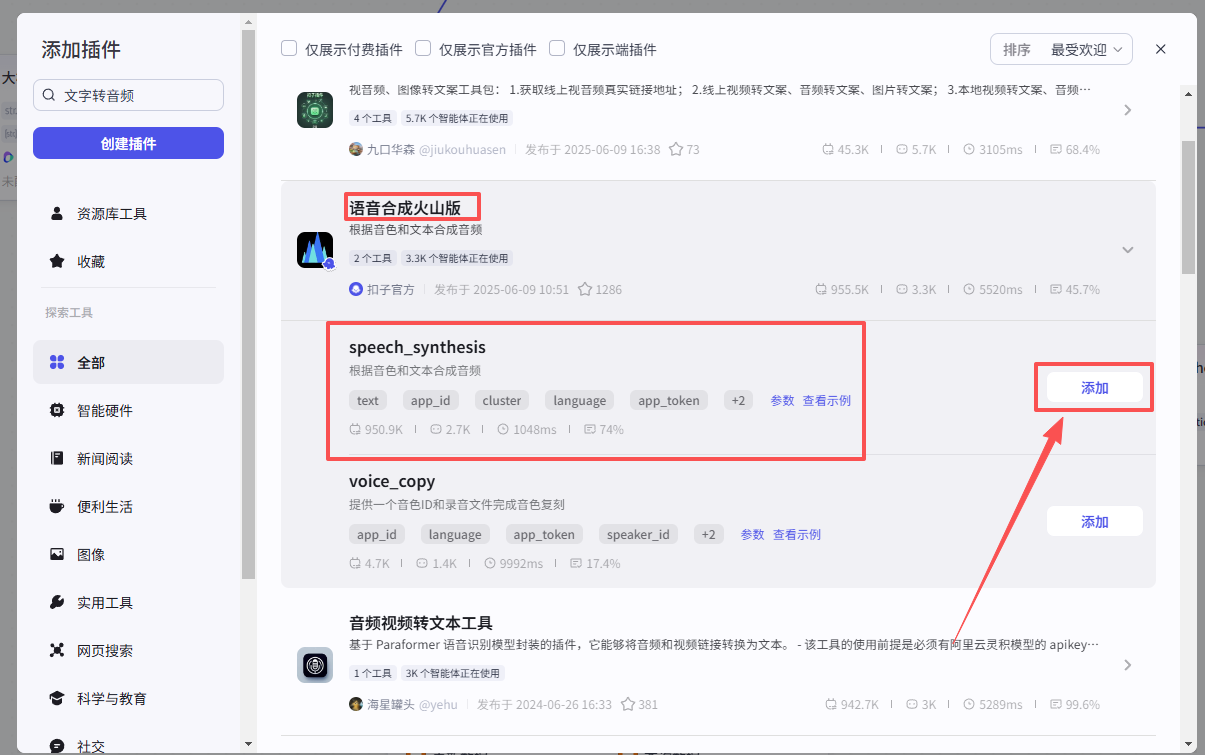
添加之后就是这样,把它和上一个大模型节点链接起来
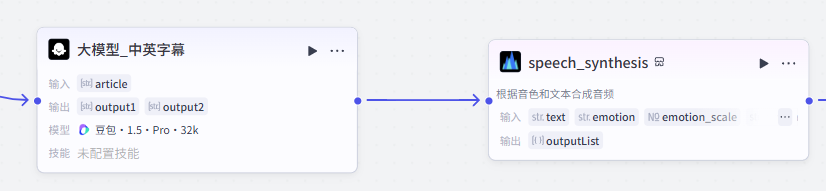
插件配置
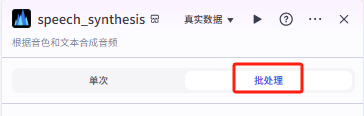
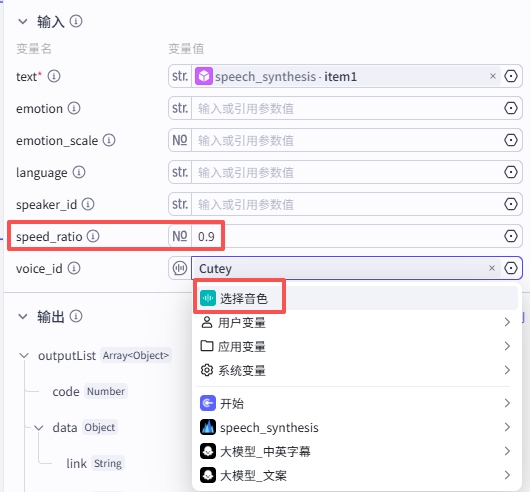
节点模式选择批处理,批处理变量”item1“为“大模型_中英字幕”中的英文字幕output1
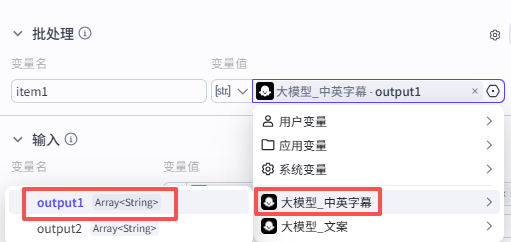
变量配置
这里需要配置三个变量参数
-
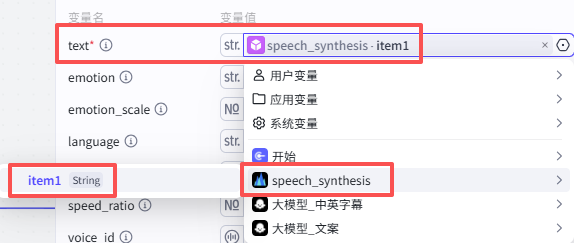
text:配置为本节点的批处理变量”item1“
-
speed_ratio:为语速,因为是儿童英语学习视频,可以适度调慢语速,这里我们选择0.9
-
voice_id:为音色,可以通过图示处进入选择想要的音色
如果仍旧不了解文字转语音插件,请点击按钮查看说明文档:点击前往
处理生成的音频和字幕
接下来我们需要对前面生成的字幕和音频进行数据处理,提取出“文本转语音”节点后生成的url语音链接

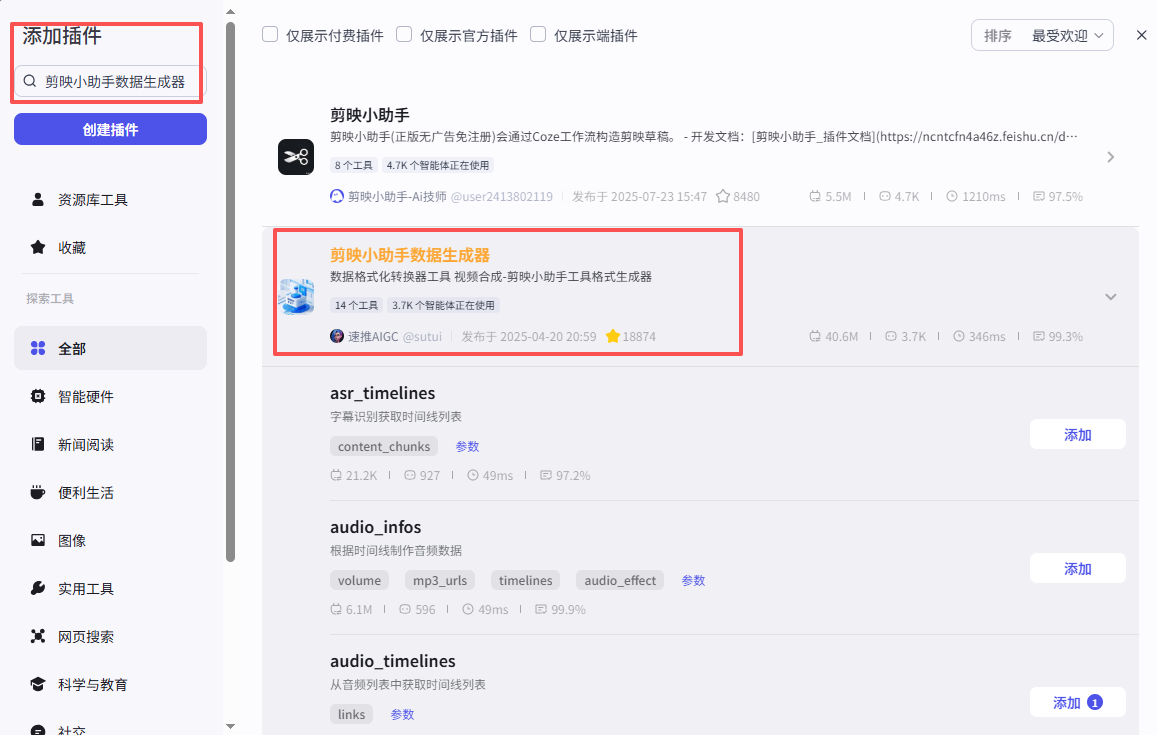
接下来添加【剪映小助手数据生成器】相关插件,点击添加节点,选择插件
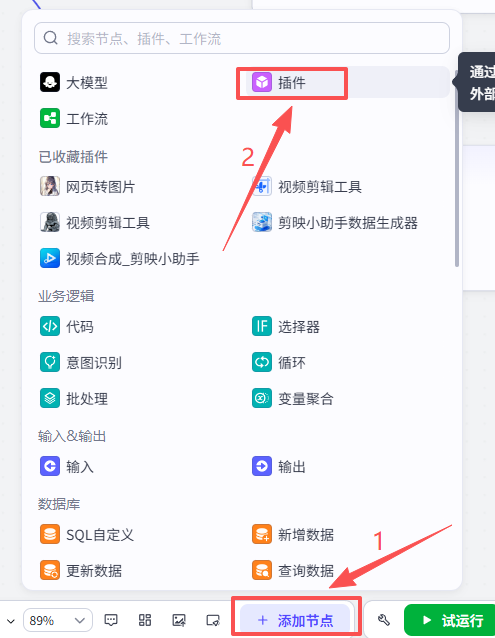
在输入框中输入剪映小助手数据生成器,看到我们框选出来的这个插件,选择添加get_url、objs_to_str_list
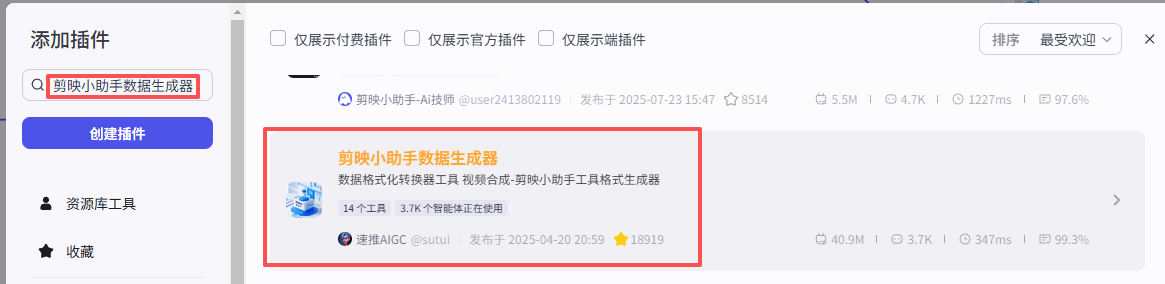
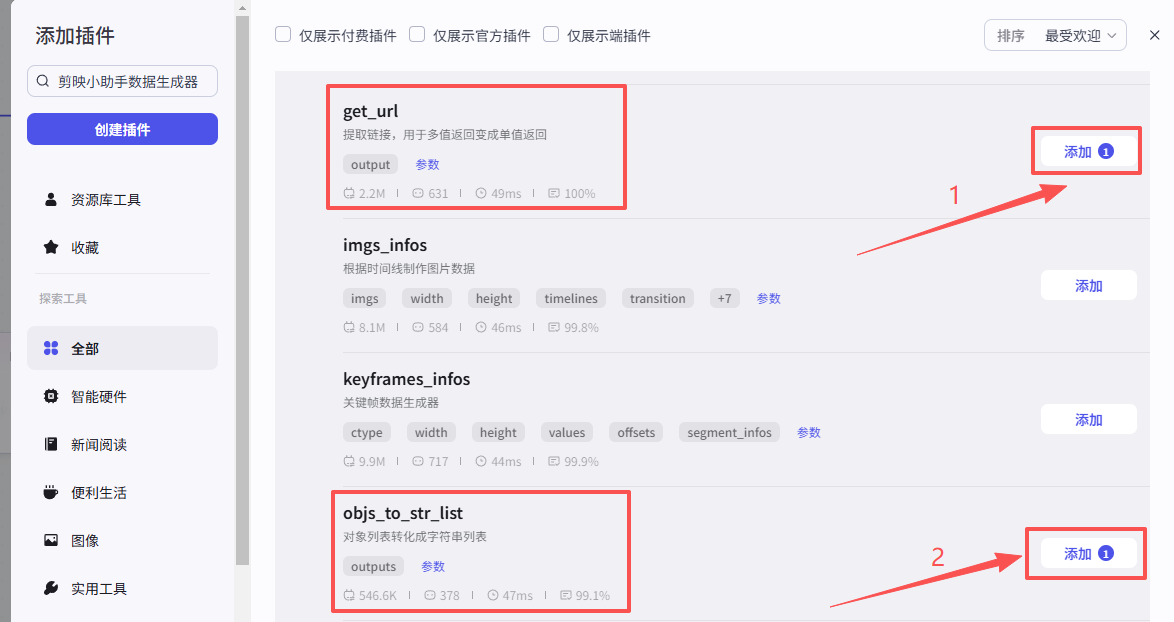
添加之后就是这样,把它们和上一个语音合成节点链接起来

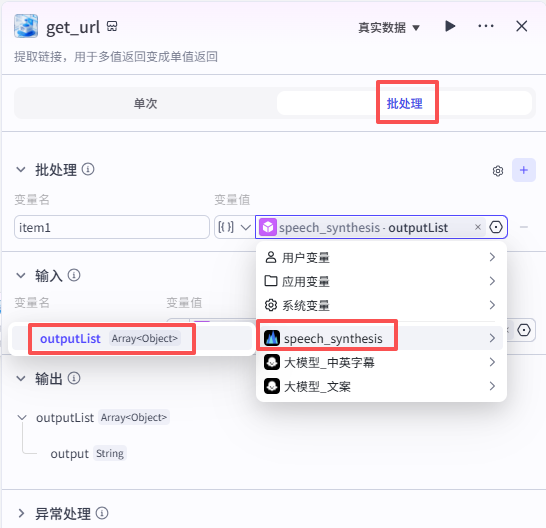
get_url
该节点配置如图:选择节点模式为批处理,配置批处理变量item1为语音合成节点的outputlist
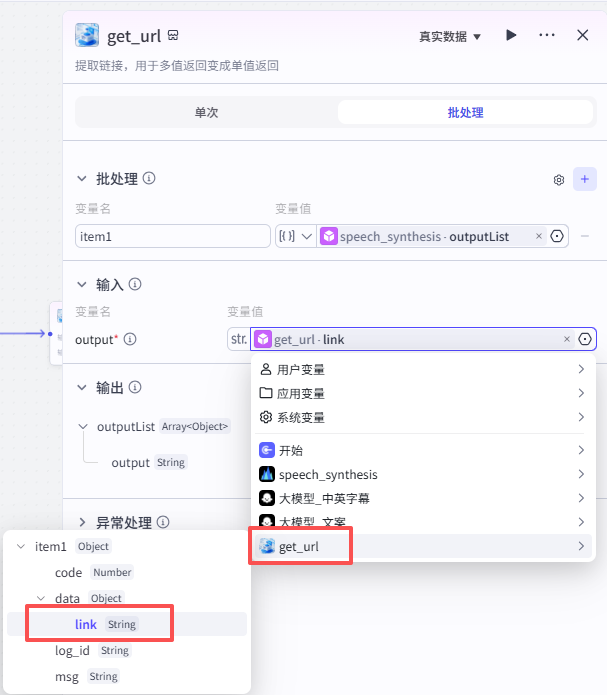
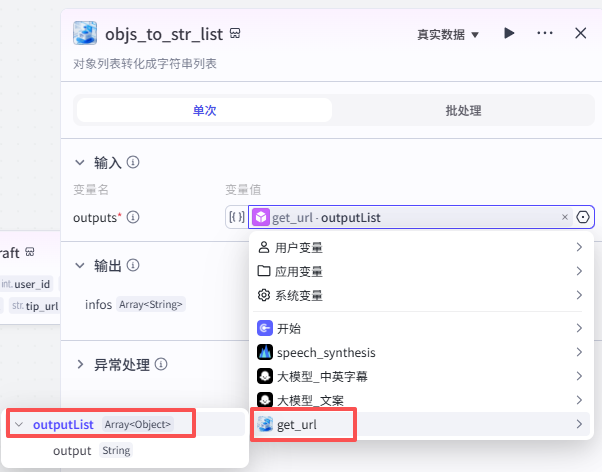
objs_to_str_list
该节点配置如图:选择节点模式为单次,配置输入变量outputs为get_url节点的outputlist
6:创建剪映草稿
接下来是较为复杂的素材处理部分,确保生成视频顺利导入剪映,共9个节点
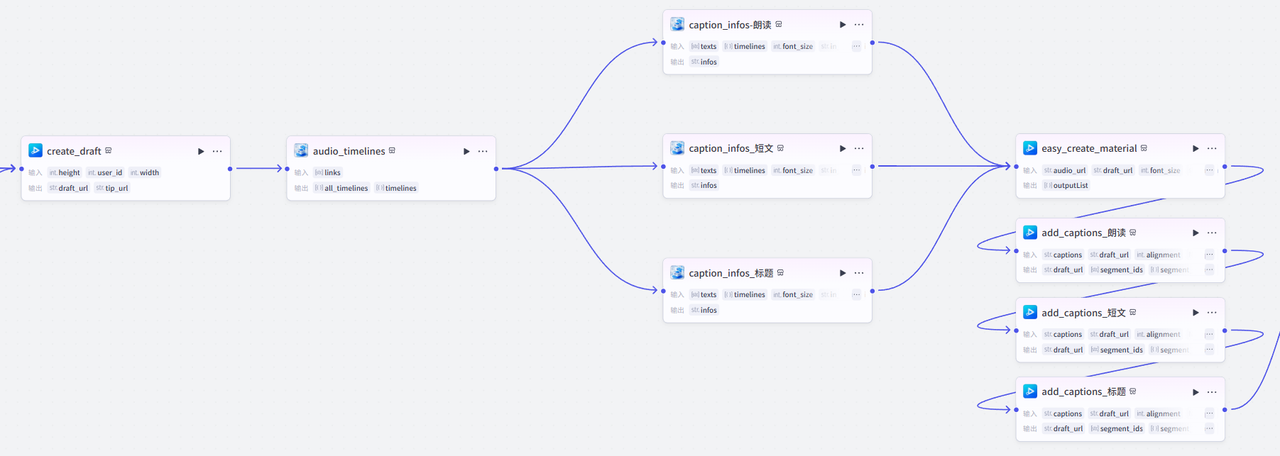
这部分的插件较多,就不在一一赘述了,插件来源于视频合成_剪映小助手和剪映小助手数据生成器
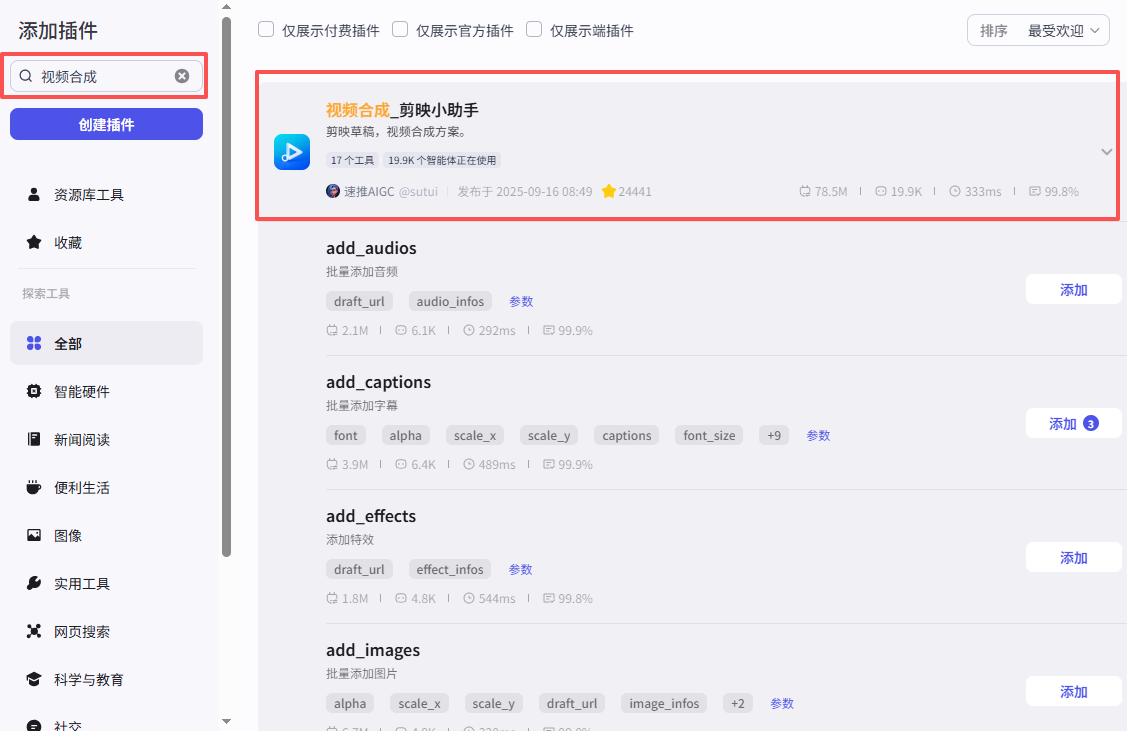
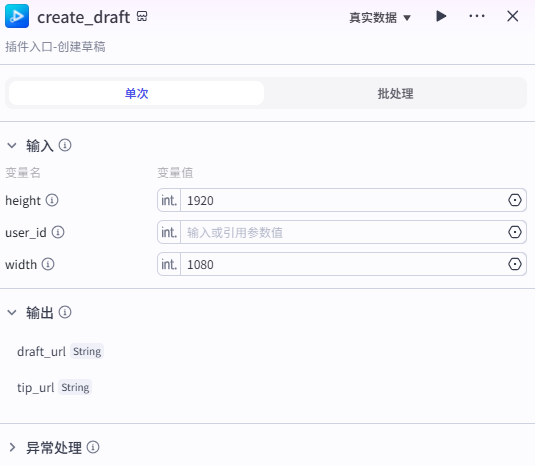
创建草稿:
这个节点是创建一个视频草稿,如图操作添加进工作流画布
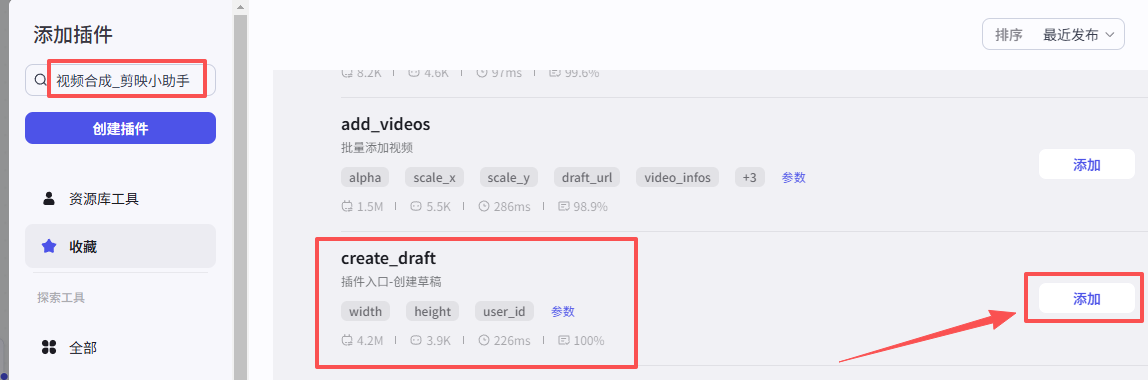
输入配置
在height和width输入数据就行,这个是草稿的画布大小
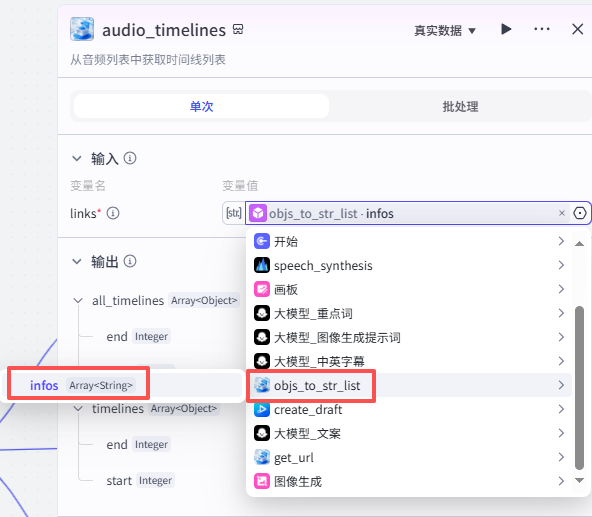
根据音频列表生成时间线:
这个节点是根据“文字转音频”节点生成的音频长度以匹配整个视频的长度创建时间线
如图操作添加进工作流画布

输入配置
输入links我们选择objs_to_str_list节点的输出infos
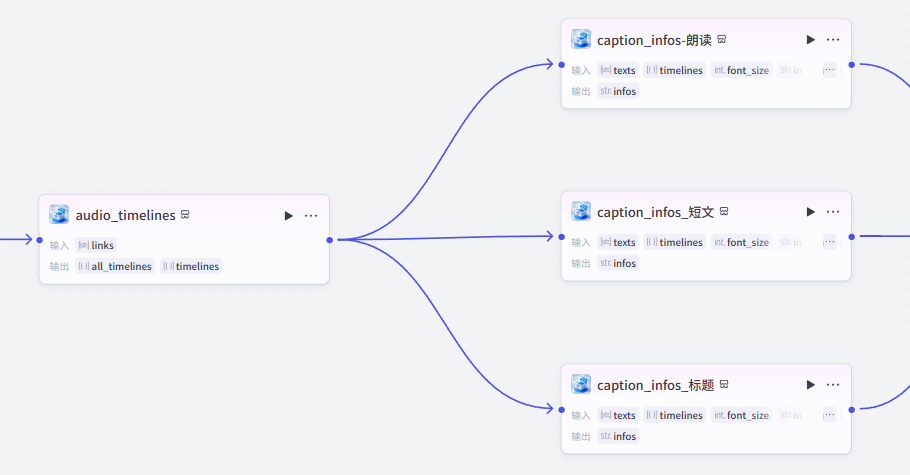
创建字幕:
接下来三线并行创建字幕,大家在链接的时候需要注意,不是串行链接哦
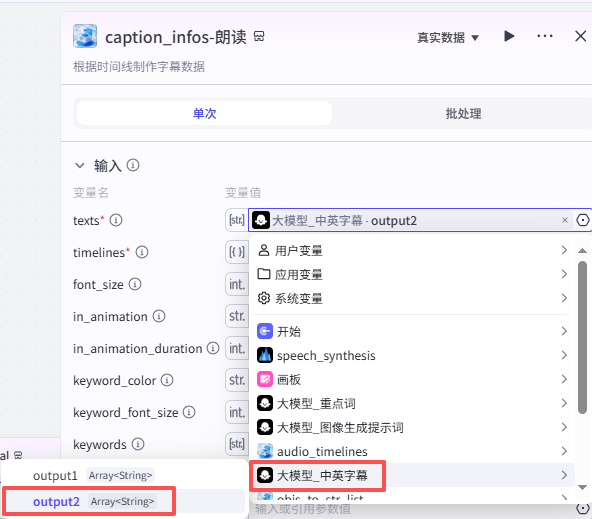
创建朗读部分字幕:
这个节点是根据时间线创建朗读部分字幕,如图操作添加进工作流画布

输入配置
-
texts:输入我们选择”大模型_中英字幕“的输出“output2”
-
timelines:输入选择“audio_timelines”的“timelines”
-
in_animation:为字幕入场动画,可在剪映中查找对应的名称自行设置
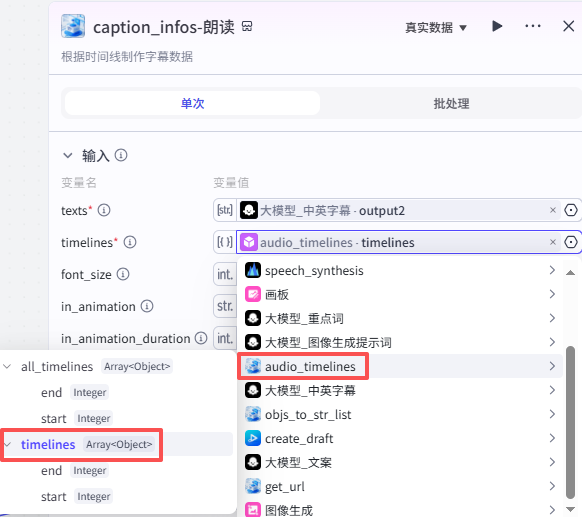
texts timelines
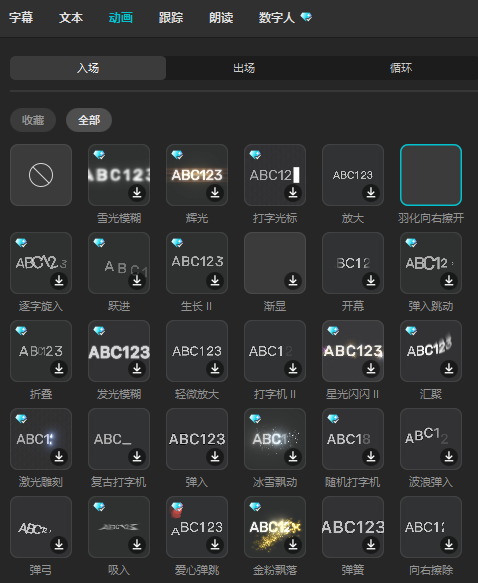
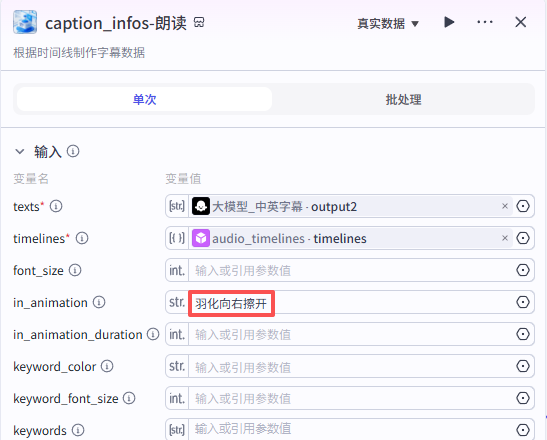
in_animation
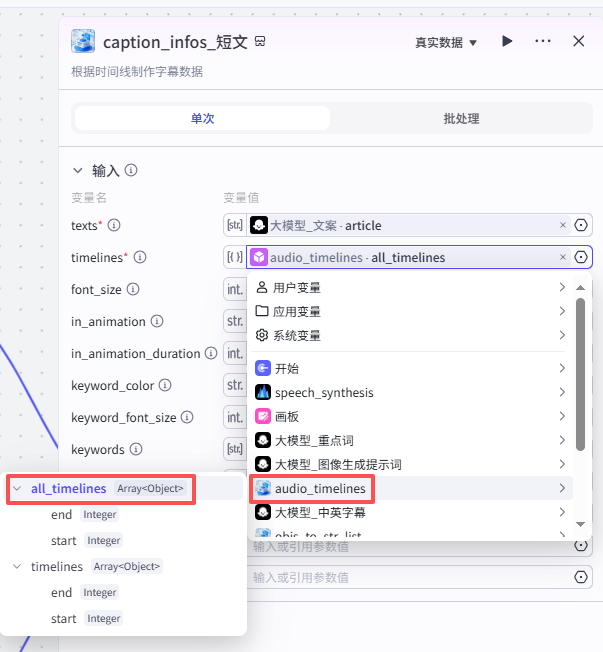
创建短文部分字幕:
这个节点是根据时间线创建短文部分字幕,如图操作添加进工作流画布

输入配置
-
texts:选择“大模型_文案”的输出article
-
timelines:选择“audio_timelines”的all_timelines
-
font_size:字体大小,我们设置了一个值7
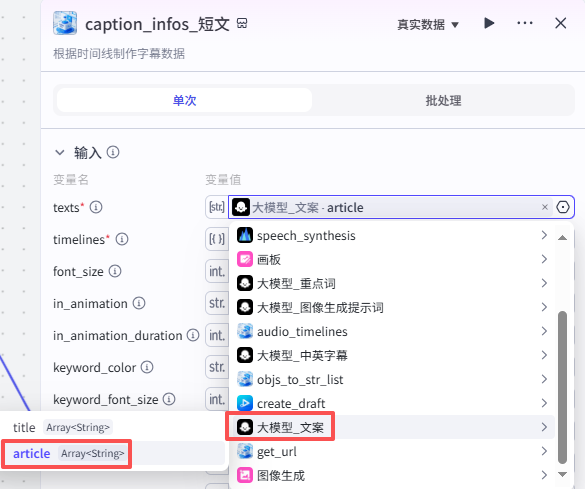
texts timelines

font_size
接下来是我们的重点词标注部分:
可自行配置重点词的颜色“keyword_color”和字体大小“keyword_font_size”

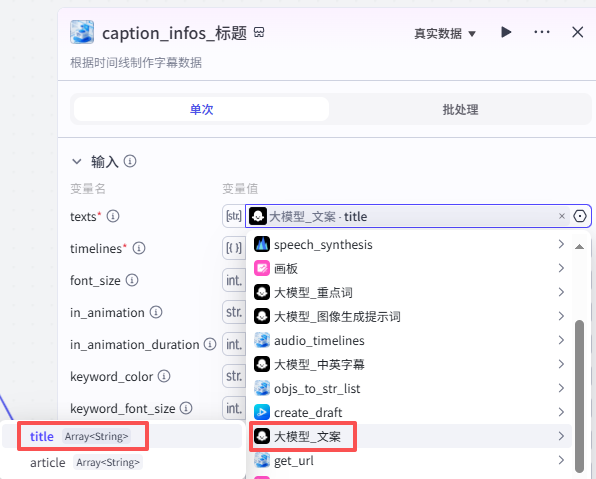
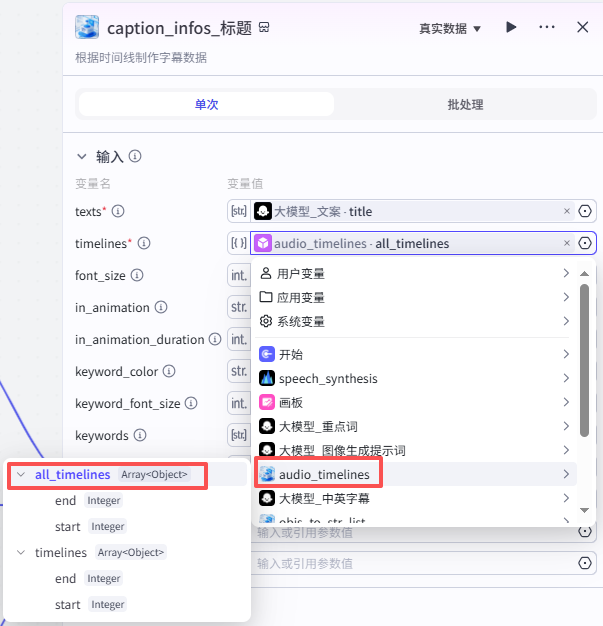
创建标题部分字幕:
这个节点是根据时间线创建短文部分字幕,如图操作添加进工作流画布

输入配置
-
texts:选择“大模型_文案”的输出title
-
timelines:选择“audio_timelines”的all_timelines
texts timelines
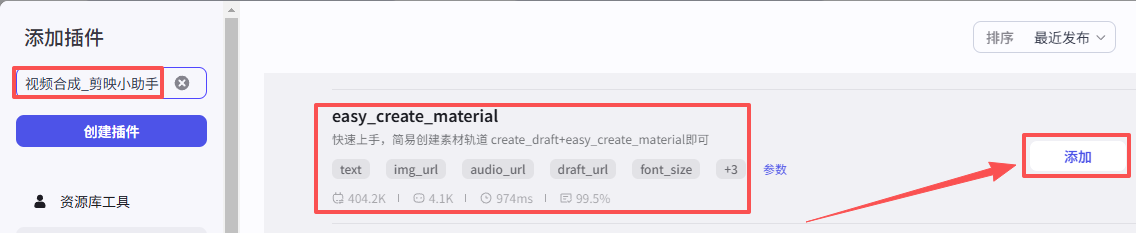
创建素材轨道
这个节点是创建素材轨道,如图操作添加进工作流画布
节点配置
首先节点模式选择批处理,批处理变量值选择为语音合成节点的输出outputlist
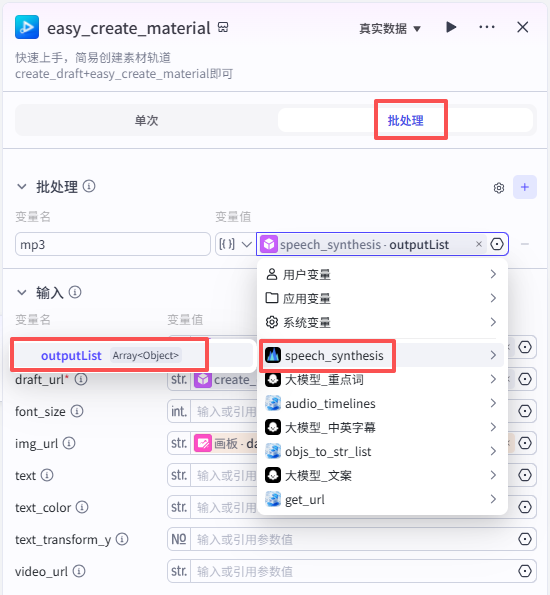
输入配置
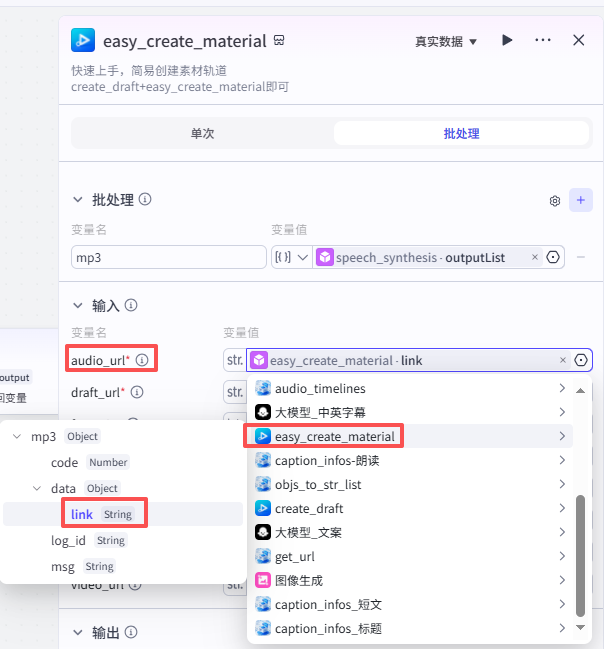
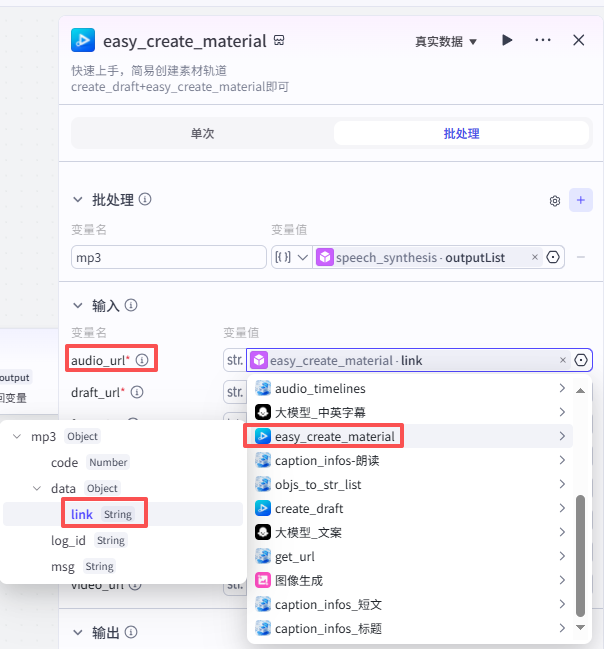
-
audio_url:选择“easy_create_material”的输出link
-
draft_url:选择“create_draft”的输出draft_url
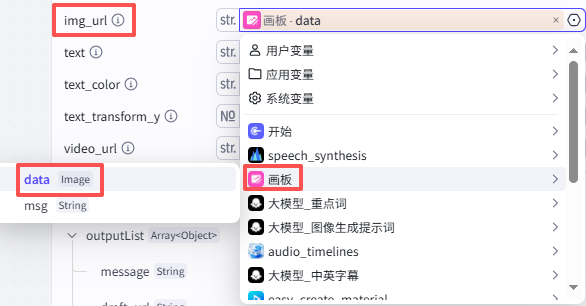
-
img_url:选择“画板”节点的输出data
audio_url
draft_url
img_url
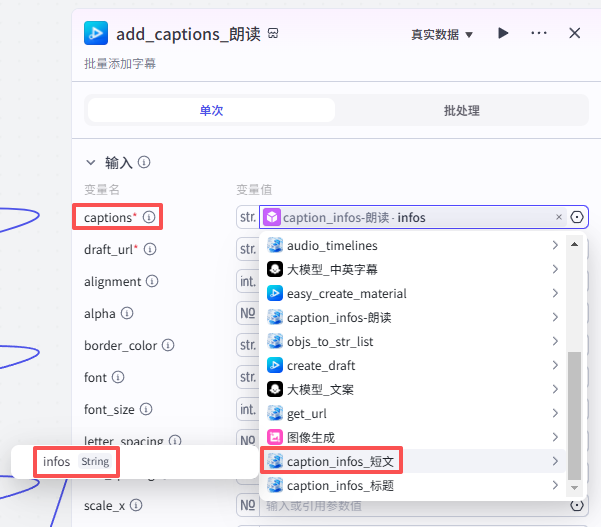
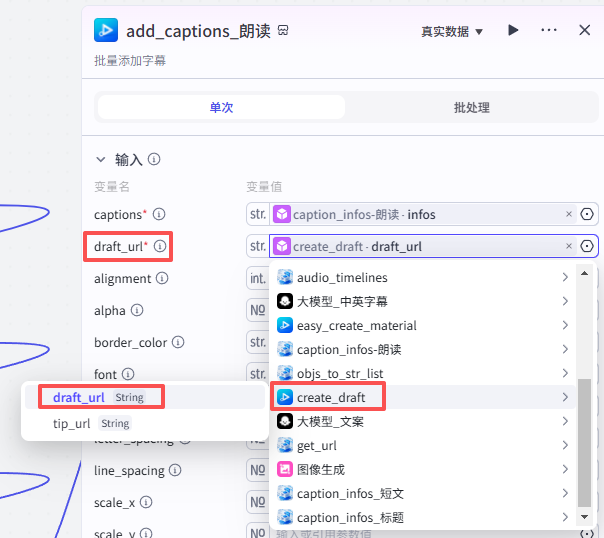
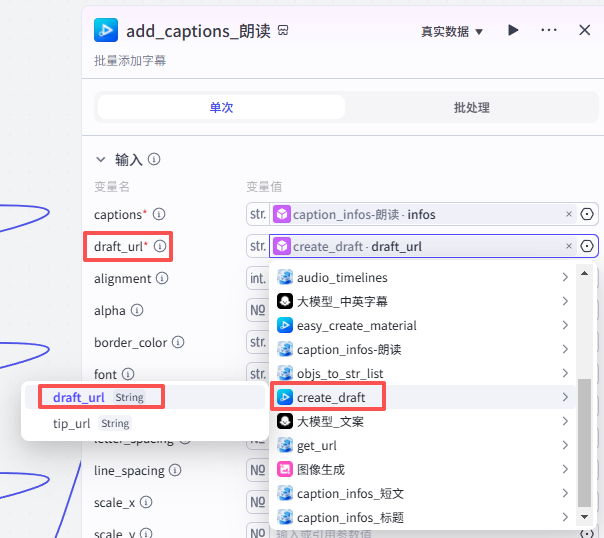
添加朗读字幕
这个节点是添加朗读字幕,如图操作添加进工作流画布

输入配置
-
captions:选择“caption_infos-朗读”的输出infos
-
draft_url:选择“create_draft”的输出draft_url
-
其他字幕设置数据:如图设置
captions draft_url

其他字幕设置数据
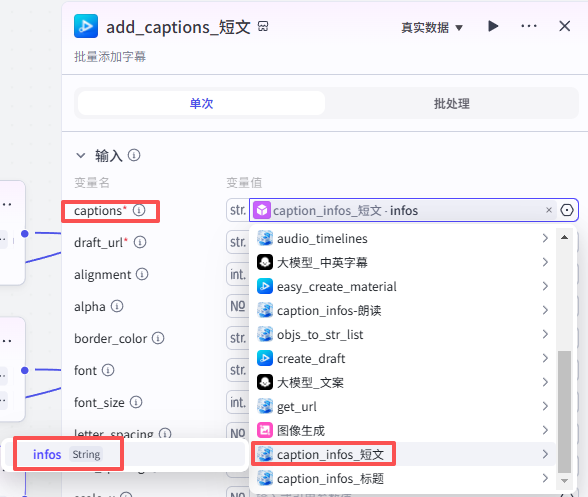
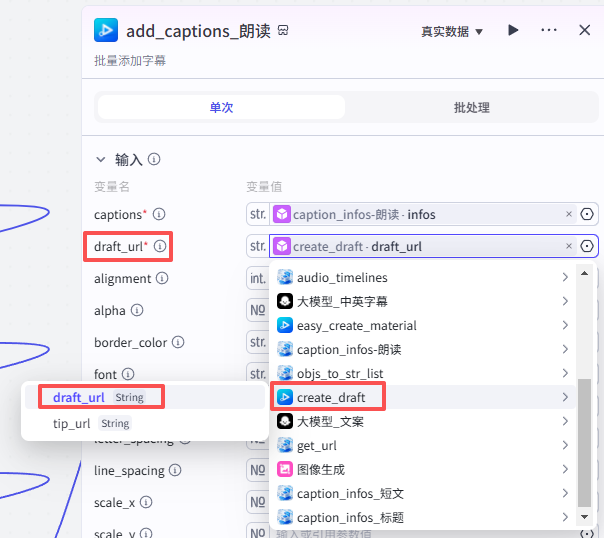
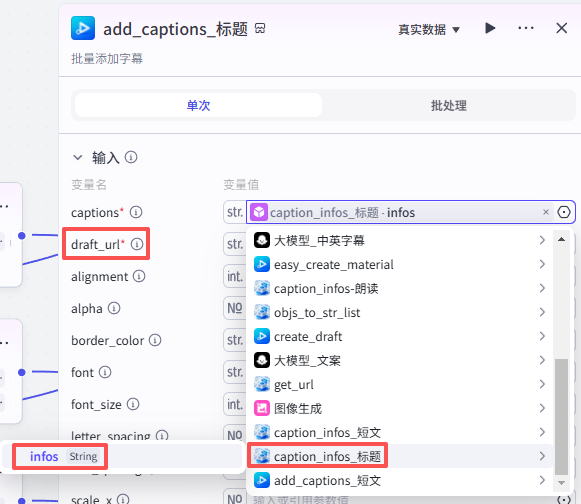
添加短文字幕
这个节点是添加短文字幕,如图操作添加进工作流画布

输入配置
-
captions:选择“caption_infos-短文”的输出infos
-
draft_url:选择“create_draft”的输出draft_url
-
其他字幕设置数据:如图设置
captions draft_url
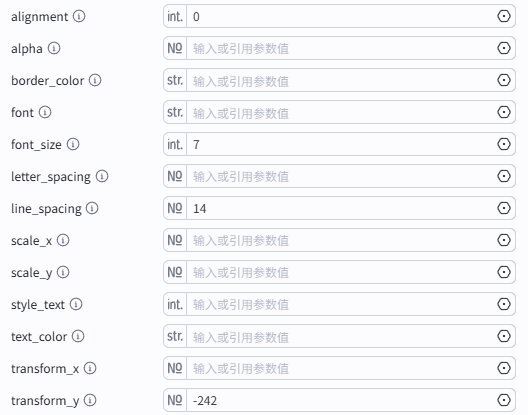
其他字幕设置数据
添加标题字幕
这个节点是添加标题字幕,如图操作添加进工作流画布

输入配置
-
captions:选择“caption_infos-短文”的输出infos
-
draft_url:选择“create_draft”的输出draft_url
-
其他字幕设置数据:如图设置
captions draft_url

其他字幕设置数据
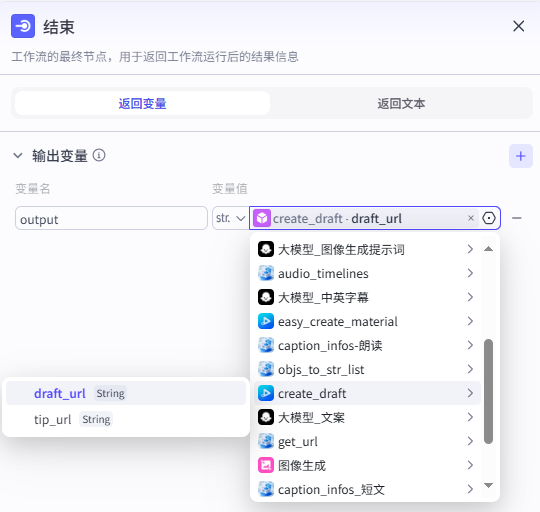
7:结束节点
最后是结束节点的配置,只需要输出我们生成好的视频的剪映小助手导出地址即可
输出配置
选择模式为返回变量,添加一个输出变量output,返回create_draft节点的输出draft_url即可
👨🏫测试展示
输入视频主题,等待运行结束
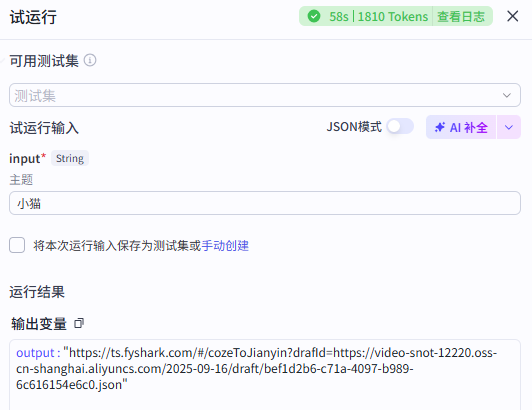
运行过程如下,可以看到工作流正常运行,顺利输出了我们的剪映小助手导出链接
只需要我们导入剪映小助手,进行素材导入剪映的步骤
不了解剪映小助手如何使用的同学,点击该按钮进行学习:前往学习
📽️案例视频展示(暂未更新)
PS:视频案例主要是展示和讲解每个工作流节点的配置内容,不是从0-1搭建智能体,大家按照教程一步一步来,不会的地方再看案例视频进行了解和补充

